- 基本演算とヴェクトル・行列,データ・フレイムの作成
- 確率分布を読み取ったりグラフに描いたりする方法
- 欠損値,変数のリコード
- 一つのカテゴリカル変数の度数分布表の作成
- 多項選択回答の表の作成
- 分割表(クロス表)の作成
一つのカテゴリカル変数の度数分布表
調査結果の報告においては,高度な分析をするだけではなく,収集した情報の基本的な集計結果を示す事も重要になる。しかしRでは,度数分布表(単純集計表などとも呼ばれる)や分割表(連関表,クロス表)について,必要最低限の結果を出力するコマンドが基本で,色々な情報を纏めて提示する為には自分で少し手を加える必要がある。以下では,学部学生の演習レヴェルであると便利だと思われる作表方法を紹介する。
模擬データの作成
自分で分析できる調査データを持たない学習者も多いだろうから,あたかも社会調査によって得たかの様な模擬データをRで簡単に作成する方法から紹介しよう。ここでの目的から,二つのカテゴリカル変数を生成する事にする。まずは以下のコマンドで一つのカテゴリカル変数模擬データを生成してみる。
q1 <- sample(c(1, 2, 3, NA), size=100, replace=T, prob=c(.34, .40, .23, .03))
sample( )関数は,無作為抽出(確率抽出)する為の関数で,抽出元となるヴェクトル,抽出回数size,復元抽出か非復元抽出かreplace,抽出する時の確率probを指定する事が出来る。上の例では,c(1, 2, 3, NA)から100回復元抽出を,それぞれの値が抽出される確率を.34,.40,.23,.03として行え,と云う意味になっている。sizeに与える数字は先に変数として値を与えておく事も出来る。社会調査データらしくする為に,わざわざ欠損値NAも多少発生する様にしている。もしデータ入力において欠損値が88や99の値でq1に入力されている場合は,欠損値をNAに置き換えた変数(ヴェクトル)q1rを作成しておくと良い。次の模擬データ生成例を参考にせよ。実際に試してみると良い。
n <- 120
q1 <- sample(c(1, 2, 3, 88, 99), size=n, replace=T, prob=c(.30, .40, .20, .05, .05))
q1r <- c(1, 2, 3)[q1]
q1; q1r
以下は,二つの変数(5件法と4件法,NA混じり)を発生させて,それを(敢えて)データ・フレイムにしている。何故敢えてデータ・フレイムにしているかと言えば,通常社会調査データはcsvファイルでデータを作成し,それをデータ・フレイムとしてRに読み込んで分析するので,それに近い状態を再現する為である。
q1 <- sample(c(1, 2, 3, 88, 99), size=n, replace=T, prob=c(.30, .40, .20, .05, .05))
q1r <- c(1, 2, 3)[q1]
q1; q1r
n <- 125
q1 <- sample(c(1, 2, 3, 4, 5, NA), size=n, replace=T, prob=c(.25, .15, .20, .20, .15, .05))
q2 <- sample(c(1, 2, 3, 4, NA), size=n, replace=T, prob=c(.30, .20, .20, .25, .05))
data01 <- data.frame(q1, q2)
それぞれの変数にアクセスする為には,data01$q1,data01$q2とする事になる。q1 <- sample(c(1, 2, 3, 4, 5, NA), size=n, replace=T, prob=c(.25, .15, .20, .20, .15, .05))
q2 <- sample(c(1, 2, 3, 4, NA), size=n, replace=T, prob=c(.30, .20, .20, .25, .05))
data01 <- data.frame(q1, q2)
一つのカテゴリカル変数の度数分布表の作成
一変数の度数分布表を作成するコマンド(関数)は,table( )である。この関数の引数に変数を渡すと,NAを除いた集計結果を出力する。NAも集計結果に表示させる為には,useNA="ifany" または useNA="always" と云うオプションを付ける。また,集計結果自体をオブジェクトに格納(保存)する事が出来る。オブジェクトに格納しておくと,一度表示して終わりではなく,その後幾らでも再利用出来るので非常に便利である。なるべく集計結果や分析結果をオブジェクトに格納する習慣を付けよう。
table(data01$q1)
table(data01$q1, useNA="ifany")
t01 <- table(data01$q1); t01
table(data01$q1, useNA="ifany")
t01 <- table(data01$q1); t01

しかしこれでは度数だけである。度数分布表(単純集計表)は通常,累積度数や相対度数(%)なども纏めて表示される。欠損値の有無別に相対度数を表示する事も多い。それらを付加した表を作成する事を目指す。
ヴェクトルに対して,累積和を求める関数が cumsum( ) である。また,ヴェクトルに対して割合(比率)を求める関数が prop.table( ) である。基本の度数分布表freqを作成した後,累積度数のヴェクトル,比率のヴェクトルを作成する例を示す。それぞれcumfreq,percentと云う名前を付けてオブジェクトとして格納し,最後にその結果を表示させている。
freq <- table(data01$q1)
cumfreq <- cumsum(freq)
percent <- prop.table(freq)
freq
cumfreq
percent
cumfreq <- cumsum(freq)
percent <- prop.table(freq)
freq
cumfreq
percent
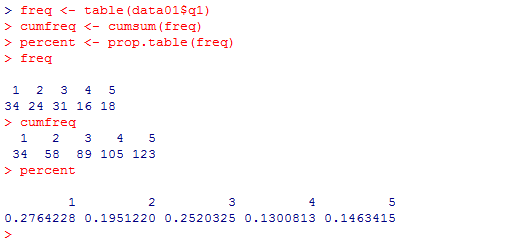
相対度数のヴェクトルpercentに関数 cumsum( ) を適用すると,累積相対度数のヴェクトルを作成出来る。
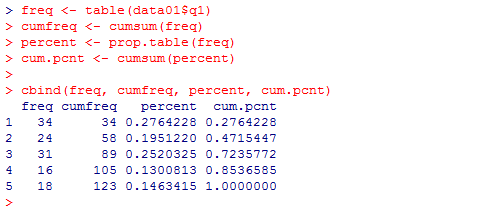
cum.pcnt <- cumsum(percent)
次の様に,列columnを結合bindする関数 cbind( ) を使うと,これらの結果を一纏めに表示出来る。これもオブジェクトに格納したいところだが,後でもう少し手を加えるのでここでは表示だけで済ませる。
cbind(freq, cumfreq, percent, cum.pcnt)
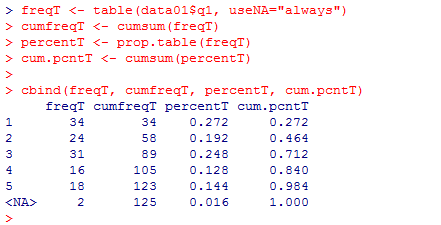
同じ事を,欠損値を含んだ度数分布表についても行う。
freqT <- table(data01$q1, useNA="always")
cumfreqT <- cumsum(freqT)
percentT <- prop.table(freqT)
cum.pcntT <- cumsum(percentT)
cbind(freqT, cumfreqT, percentT, cum.pcntT)
cumfreqT <- cumsum(freqT)
percentT <- prop.table(freqT)
cum.pcntT <- cumsum(percentT)
cbind(freqT, cumfreqT, percentT, cum.pcntT)
最後に,以上の結果から,必要なものだけを纏めてラベルも付けて一つの表にしよう。
NAを含む度数分布表と含まない度数分布表では行の数(ヴェクトルの長さ)が1つ異なるので,最初にそれを調整している。
percent <- c(percent, NA); cum.pcnt <- c(cum.pcnt, NA)
freq.table <- cbind("度数"=freqT, "累積度数"=cumfreqT, "相対度数"=percentT, "累積相対度数"=cum.pcntT, "有効相対度数"=percent, "有効累積相対度数"=cum.pcnt)
freq.table
freq.table <- cbind("度数"=freqT, "累積度数"=cumfreqT, "相対度数"=percentT, "累積相対度数"=cum.pcntT, "有効相対度数"=percent, "有効累積相対度数"=cum.pcnt)
freq.table

以上から必要な部分だけを抜き出すと以下の通りである。これを,度数分布表を作成したい変数ごとに使いまわせば良い。最初の二行の data01$q1 の部分だけを書き換えれば良い。
freq <- table(data01$q1)
freqT <- table(data01$q1, useNA="always")
percent <- prop.table(freq)
cum.pcnt <- cumsum(percent)
percent <- c(percent, NA); cum.pcnt <- c(cum.pcnt, NA)
cumfreqT <- cumsum(freqT)
percentT <- prop.table(freqT)
cum.pcntT <- cumsum(percentT)
freq.table <- cbind("度数"=freqT, "累積度数"=cumfreqT, "相対度数"=percentT, "累積相対度数"=cum.pcntT, "有効相対度数"=percent, "有効累積相対度数"=cum.pcnt)
freq.table
しかしいちいちこれを全て変数ごとにコピー&ペイストして使用するのは手間がかかると云う場合には,「Rでは自分で新しい関数を自由に定義出来る」と云う極めて便利な機能を利用すると良い。自作関数の定義は,初心者が多用すると却って混乱する懸念もあるが,こうした長いスクリプトを繰り返し利用する事が分かっている場合は使ってみても良いだろう。freqT <- table(data01$q1, useNA="always")
percent <- prop.table(freq)
cum.pcnt <- cumsum(percent)
percent <- c(percent, NA); cum.pcnt <- c(cum.pcnt, NA)
cumfreqT <- cumsum(freqT)
percentT <- prop.table(freqT)
cum.pcntT <- cumsum(percentT)
freq.table <- cbind("度数"=freqT, "累積度数"=cumfreqT, "相対度数"=percentT, "累積相対度数"=cum.pcntT, "有効相対度数"=percent, "有効累積相対度数"=cum.pcnt)
freq.table
以下では,freq.table( ) と云う関数名で定義している。
freq.table <- function (x) {
freq <- table(x)
freqT <- table(x, useNA="always")
percent <- prop.table(freq)
cum.pcnt <- cumsum(percent)
percent <- c(percent, NA); cum.pcnt <- c(cum.pcnt, NA)
cumfreqT <- cumsum(freqT)
percentT <- prop.table(freqT)
cum.pcntT <- cumsum(percentT)
output <- cbind("度数"=freqT, "累積度数"=cumfreqT, "相対度数"=percentT, "累積相対度数"=cum.pcntT, "有効相対度数"=percent, "有効累積相対度数"=cum.pcnt)
return(output)
}
こうして新関数として定義した後で,その関数に q1 や q2 を引数として与えると以下の様になる(本来ならデータ・フレイム中の変数として,data01$q1 ,data01$q2 として引数に与えるべきところであったが,以下のスクリーンショットでは誤ってデータ・フレイム外の q1,q2 として引数としてしまっている)。freq <- table(x)
freqT <- table(x, useNA="always")
percent <- prop.table(freq)
cum.pcnt <- cumsum(percent)
percent <- c(percent, NA); cum.pcnt <- c(cum.pcnt, NA)
cumfreqT <- cumsum(freqT)
percentT <- prop.table(freqT)
cum.pcntT <- cumsum(percentT)
output <- cbind("度数"=freqT, "累積度数"=cumfreqT, "相対度数"=percentT, "累積相対度数"=cum.pcntT, "有効相対度数"=percent, "有効累積相対度数"=cum.pcnt)
return(output)
}
