- 基本演算とヴェクトル・行列,データ・フレイムの作成
- 確率分布を読み取ったりグラフに描いたりする方法
- 欠損値,変数のリコード
- 一つのカテゴリカル変数の度数分布表の作成
- 多項選択回答の表の作成
- 分割表(クロス表)の作成
多項選択回答(Multiple Answer)の処理
「以下の中から,あてはまるものを全てお選び下さい。」と云った質問―回答の方法を,多項選択方式と言う(複数回答と呼ぶ事も多い)。例えば,内閣府が毎年行っている「国民生活に関する世論調査」(平成27年度)の以下の質問がそうである。
Q9 あなたは,今後の生活において,特にどのような面に力を入れたいと思いますか。この中からいくつでもあげてください。(M.A.)
(ア) 食生活
(イ) 衣生活
(ウ) 自動車,電気製品,家具などの耐久消費財
(エ) 住生活
(オ) レジャー・余暇生活
(カ) 自己啓発・能力向上
(キ) 所得・収入
(ク) 資産・貯蓄
その他
ない
わからない
この質問は1つの質問の様に見えているが,正確には「食生活に力を入れたいと思いますか」「衣生活に力を入れたいと思いますか」などの様に各選択肢項目が一つの質問になっていると考えるべきであり,データ・ファイル中の変数にする場合には各質問項目がそれぞれ0(選択されなかった)か1(選択された)の値を取る二値変数として記録される。(近年では,多項選択形式で質問をすると"satisficing"――全ての質問や選択肢項目にきちんと回答せずに,適当なところで「これくらい答えておけばいいだろう」と回答を打ち切る回答行動――が生じて正確な情報が得られないとの批判もある。)(ア) 食生活
(イ) 衣生活
(ウ) 自動車,電気製品,家具などの耐久消費財
(エ) 住生活
(オ) レジャー・余暇生活
(カ) 自己啓発・能力向上
(キ) 所得・収入
(ク) 資産・貯蓄
その他
ない
わからない
以下では,この様な多項選択形式の質問の回答データの処理・作表についてのスクリプトを紹介する。
模擬データの作成
まずは調査データの無い人でも試してみられる様に,多項選択回答データの模擬データを生成しよう。以下では,0と1をそれぞれ異なる確率で生成する4つの二値変数を発生させている。多項選択の場合は,無回答(NA)の場合には全ての選択項目に○がついていない場合に含まれるので,ここでは個別にNAを発生させる事はしない。(多項選択でいずれかの項目だけNAになる事の方がおかしい。)
# 二値変数の生成とデータ・フレイム化
n <- 150
q0101 <- sample(c(0, 1), size=n, replace=T, prob=c(.30, .70))
q0102 <- sample(c(0, 1), size=n, replace=T, prob=c(.60, .40))
q0103 <- sample(c(0, 1), size=n, replace=T, prob=c(.40, .60))
q0104 <- sample(c(0, 1), size=n, replace=T, prob=c(.80, .20))
data01 <- data.frame(q0101, q0102, q0103, q0104)
各変数の度数分布表を個別に作成するのは簡単である。繰り返し適用するなら,新関数として定義する事も出来る。NAを考えなくて良いので非常に簡単になる。n <- 150
q0101 <- sample(c(0, 1), size=n, replace=T, prob=c(.30, .70))
q0102 <- sample(c(0, 1), size=n, replace=T, prob=c(.60, .40))
q0103 <- sample(c(0, 1), size=n, replace=T, prob=c(.40, .60))
q0104 <- sample(c(0, 1), size=n, replace=T, prob=c(.80, .20))
data01 <- data.frame(q0101, q0102, q0103, q0104)
freq.tableD <- function (x) {
freq <- table(x)
percent <- prop.table(freq)
output <- cbind("度数"=addmargins(freq), "相対度数"=addmargins(percent))
return(output)
}
freq.tableD(data01$q0101)
freq.tableD(data01$q0102)
freq.tableD(data01$q0103)
freq.tableD(data01$q0104)
freq <- table(x)
percent <- prop.table(freq)
output <- cbind("度数"=addmargins(freq), "相対度数"=addmargins(percent))
return(output)
}
freq.tableD(data01$q0101)
freq.tableD(data01$q0102)
freq.tableD(data01$q0103)
freq.tableD(data01$q0104)

しかし,多項選択形式の回答の整理には,全ての項目の選択数や選択率を一覧にして示す事が多い。次にその為の簡単なスクリプトを紹介しよう。
多項選択一括集計表の作成
データ・フレイム data01 は集計したい二値変数だけからなり,集計したい二値変数は全て data01 に含まれているとする。上記と同じ様に,各変数には0か1の値が必ず入力されており,NAを含め他の値は存在しないものとする(NAを考えなくて良い二値変数の処理は非常に簡単になる)。以下では,二値変数の個数を4つとは前提せず,ケース数も150とは前提としない一般的なスクリプトを作成している。
apply( ) や tapply( ) と云う関数は使える様になると非常に便利であるので,ウェブ上などで"R apply"などと検索して調べてみると良い。
apply( ) 関数において,MARGIN は1が行方向,2が列方向を意味し,FUN はそれに適用する関数(function)を指定する。sum は合計の関数であり,0か1の二値変数を合計すると1の個数に等しくなる事を利用している。apply(data, MARGIN=2, FUN=sum) を colSums(data),apply(data, MARGIN=1, FUN=sum) を rowSums(data) と書いても同じになる。
# 多項選択形式の回答の集計表
nYES <- apply(data01, MARGIN=2, FUN=sum) # colSums(data01)としても同じ。
MA01 <- cbind("○の数"=nYES, "×の数"=nrow(data01)-nYES, "総度数"=nrow(data01),
"○の%"=nYES/nrow(data01)*100, "×の%"=(nrow(data01)-nYES)/nrow(data01)*100)
rownames(MA01) <- colnames(data01)
MA01
# 結果表をcsvに保存する
write.csv(MA01, file="multiple_answer.csv", quote=F)
nYES <- apply(data01, MARGIN=2, FUN=sum) # colSums(data01)としても同じ。
MA01 <- cbind("○の数"=nYES, "×の数"=nrow(data01)-nYES, "総度数"=nrow(data01),
"○の%"=nYES/nrow(data01)*100, "×の%"=(nrow(data01)-nYES)/nrow(data01)*100)
rownames(MA01) <- colnames(data01)
MA01
# 結果表をcsvに保存する
write.csv(MA01, file="multiple_answer.csv", quote=F)
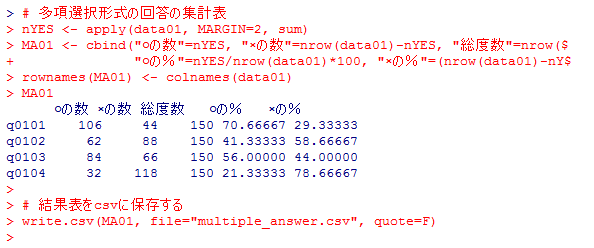
最後に保存したcsvファイルをMS-Excelで開いた状態を以下に示す。
それぞれ独立にNAが含まれる二値変数の一括集計表
何らかの理由で,それぞれ別個にNAを含む様な二値変数を一括集計表にする方法も考えて見よう。NAが含まれる場合は上記よりも格段に難易度が上がる。まずは二値変数を生成するところから始める。
# NAを含む二値変数の生成
n <- 125
q0201 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.70, .25, .05))
q0202 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.60, .37, .03))
q0203 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.44, .54, .02))
q0204 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.90, .08, .02))
q0205 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.30, .66, .04))
data01 <- data.frame(q0201, q0202, q0203, q0204, q0205) # 二値変数だけでデータ・フレイムにする
次に,それぞれの度数分布表を作成してみよう。度数分布表を作成する新関数 freq.tableDN( ) は,必要だと思われる情報に限定している。n <- 125
q0201 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.70, .25, .05))
q0202 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.60, .37, .03))
q0203 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.44, .54, .02))
q0204 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.90, .08, .02))
q0205 <- sample(c(0, 1, NA), size=n, replace=T, prob=c(.30, .66, .04))
data01 <- data.frame(q0201, q0202, q0203, q0204, q0205) # 二値変数だけでデータ・フレイムにする
freq.tableDN <- function (x) {
freqT <- table(x, useNA="always")
cumfreqT <- cumsum(freqT)
percentT <- prop.table(freqT)
percent <- c(prop.table(table(x)), NA)
return(cbind("度数"=freqT, "累積度数"=cumfreqT, "相対度数"=percentT, "有効相対度数"=percent))
}
freq.tableDN(data01$q0201)
freq.tableDN(data01$q0202)
freq.tableDN(data01$q0203)
freq.tableDN(data01$q0204)
freq.tableDN(data01$q0205)
freqT <- table(x, useNA="always")
cumfreqT <- cumsum(freqT)
percentT <- prop.table(freqT)
percent <- c(prop.table(table(x)), NA)
return(cbind("度数"=freqT, "累積度数"=cumfreqT, "相対度数"=percentT, "有効相対度数"=percent))
}
freq.tableDN(data01$q0201)
freq.tableDN(data01$q0202)
freq.tableDN(data01$q0203)
freq.tableDN(data01$q0204)
freq.tableDN(data01$q0205)

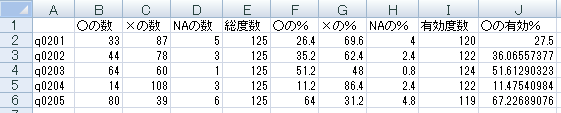
さて,いよいよ一括集計表を作成しよう。下のスクリプト中, colSums(data01, na.rm=T) は apply(data01, MARGIN=2, FUN=sum, na.rm=T) とするのと同じである。また,apply(data01, 2, function(x){sum(is.na(x))}) は,FUNの部分で新関数を定義しており,その関数は,「xがNAに等しい」の真偽値(TRUE=1, FALSE=0)の合計 となっている。
denom <- nrow(data01) # ケース数(データ・フレイムの行数に等しい)
nYES <- colSums(data01, na.rm=T) # naをremoveして1を数える
nNA <- apply(data01, 2, function(x){sum(is.na(x))}) # 列方向に,NAであるものの個数を数える
nNO <- denom - (nYES + nNA) # ケース数からYESの数とNAの数を引く
MA.NA01 <- cbind("○の数"=nYES, "×の数"=nNO, "NAの数"=nNA, "総度数"=denom,
"○の%"=nYES/denom*100, "×の%"=nNO/denom*100, "NAの%"=nNA/denom*100,
"有効度数"=nYES+nNO, "○の有効%"=nYES/(nYES+nNO)*100)
rownames(MA.NA01) <- colnames(data01)
MA.NA01
write.csv(MA.NA01, file="multiple_answer2.csv", quote=F) # 最後にcsvファイル保存
出力表の列数が多いので画面に収まりきらずに下に折り返されている。上の各変数の度数分布表と見比べて対応している事を確認すると良い。nYES <- colSums(data01, na.rm=T) # naをremoveして1を数える
nNA <- apply(data01, 2, function(x){sum(is.na(x))}) # 列方向に,NAであるものの個数を数える
nNO <- denom - (nYES + nNA) # ケース数からYESの数とNAの数を引く
MA.NA01 <- cbind("○の数"=nYES, "×の数"=nNO, "NAの数"=nNA, "総度数"=denom,
"○の%"=nYES/denom*100, "×の%"=nNO/denom*100, "NAの%"=nNA/denom*100,
"有効度数"=nYES+nNO, "○の有効%"=nYES/(nYES+nNO)*100)
rownames(MA.NA01) <- colnames(data01)
MA.NA01
write.csv(MA.NA01, file="multiple_answer2.csv", quote=F) # 最後にcsvファイル保存

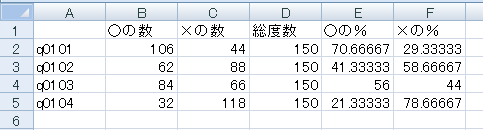
最後に保存したcsvファイルをMS-Excelで開くと以下の通りである。