- 婎杮墘嶼偲償僃僋僩儖丒峴楍丆僨乕僞丒僼儗僀儉偺嶌惉
- 妋棪暘晍傪撉傒庢偭偨傝僌儔僼偵昤偄偨傝偡傞曽朄
- 寚懝抣丆曄悢偺儕僐乕僪
- 堦偮偺僇僥僑儕僇儖曄悢偺搙悢暘晍昞偺嶌惉
- 懡崁慖戰夞摎偺昞偺嶌惉
- 暘妱昞乮僋儘僗昞乯偺嶌惉
曄悢(variable)偲曄悢抣(value)偺憖嶌
丂幮夛挷嵏僨乕僞傪埖偆応崌偵幚嵺偵柺搢側偺偼丆僨乕僞暘愅傗懡曄検夝愅偺偔偩傝偱偼側偔丆傓偟傠偦偺弨旛嶌嬈偲偟偰偺僨乕僞偺惍旛傗壛岺偺晹暘偱偁傞丅廂廤偟偨忣曬乮挷嵏昜偺夞摎慖戰巿斣崋乯偐傜暿偺悢抣偵妱傝摉偰傞儕僐乕僪傗丆忣曬偑摼傜傟側偐偭偨応崌偺寚懝抣偺張棟側偳偑偒偪傫偲弌棃側偄偲丆偦傕偦傕揔愗側廤寁傗暘愅偑峴偊側偄丅偟偐偟偙傟傜偺嶌嬈偼庢傝暘偗摑寁僜僼僩偵傛偭偰堎側傞晹暘偱偁傝丆摿偵R偺応崌偵偼SPSS側偳偲傗傗敪憐傪曄偊側偗傟偽偆傑偔巊偊側偄帠傕懡偄丅曄悢偺庬椶丗 悢抣宆偲梫場宆
丂怱棟摑寁妛偱偼曄悢偺庬椶乮広搙悈弨乯傪丆柤媊広搙丆弴彉広搙丆娫妘広搙丆斾椺広搙偵暘偗傞帠偑懡偄丅柤媊広搙傗弴彉広搙偺忣曬傪悢抣偱昞尰偡傞帠偼懡偄偑丆懌偟嶼傗堷偒嶼側偳偺墘嶼偑弌棃傞偺偼娫妘広搙偲斾椺広搙偱偁傞丅丂懠曽丆SPSS側偳偺摑寁僜僼僩傪偼偠傔丆僐儞僺儏乕僞僜僼僩偼堦斒揑偵丆悢抣宆乛暥帤宆偺條偵忣曬傪嬫暿偟丆悢抣宆偲擣幆偝傟偨傕偺偵偼壛尭忔彍側偳偺墘嶼傪峴偆丅悢帤偱偝偊偁傟偽丆偦傟偑柤媊広搙偱偁傞偐弴彉広搙偱偁傞偐娫妘広搙埲忋偱偁傞偐偼栤戣偲偟側偄丅
丂僐儞僺儏乕僞僜僼僩傪梡偄偰摑寁暘愅傪峴偆応崌丆曄悢偺庬椶埥偄偼広搙悈弨傪惓偟偔棟夝偟偰嬫暿偟側偄偲丆婥晅偐側偄偆偪偵岆偭偨暘愅傪偟偰偟傑偆帠偵側傞偺偱丆偙偺揰偵偮偄偰傛偔拲堄偟側偗傟偽側傜側偄丅
丂R偱偼庢傝姼偊偢丆悢抣宆numeric丆暥帤宆character丆梫場宆factor偺3偮偺嬫暿偵拲堄偡傞帠偵偟傛偆丅
丂椺偊偽丆幮夛挷嵏偱惈暿傪朘偹偰丆抝惈=1丆彈惈=2丆偦偺懠=3偲偟偰夞摎傪廂廤偟偨偲偟傛偆丅偙傟偼丆暥帤偱昞尰偟傛偆偑悢帤偱昞尰偟傛偆偑丆柤媊広搙偱偁傞丅
丂10恖偺夞摎傪悢抣偱償僃僋僩儖q01偵奿擺偟偨偲偡傞丅
q01 <- c(1, 2, 3, 2, 2, 1, 1, 2, 1, 3)
丂R偺娭悢 mean( ) 傗 summary( ) 傪q01偵揔梡偡傞偲丆嶼弍暯嬒傗拞墰抣側偳傪弌椡偡傞偑丆偙傟傜偼偄偢傟傕柤媊広搙偵偮偄偰媮傔傞帠偺弌棃側偄摑寁検偱偁傞丅丂偙偺償僃僋僩儖偺宆傪挷傋傞堊偵 class( ) 偲塢偆娭悢傪揔梡偡傞偲 "numeric" 偲昞帵偝傟傞丅numeric丆悢抣宆曄悢偲擣幆偝傟偰偄傞尷傝丆暯嬒偱傕暘嶶偱傕寁嶼偝傟偰偟傑偆丅

丂崱搙偼丆摨偠夞摎偑丆暥帤偺偐偨偪偱償僃僋僩儖q02偵奿擺偝傟偰偄傞偲偟傛偆丅
q02 <- c("抝惈", "彈惈", "偦偺懠", "彈惈", "彈惈", "抝惈", "抝惈", "彈惈", "抝惈", "偦偺懠")
丂偙偆偡傞偲 mean( ) 偼寁嶼偑嫅斲偝傟丆summary( ) 傕僨乕僞偺屄悢(Length)埲奜偼暘偐傜側偄丅丂class( ) 偲偡傞偲丆"character"丆暥帤楍偱偁傞帠偑暘偐傞乮summary( )偺寢壥偵傕昞帵偝傟偰偄傞乯丅

丂R偵偼偙傟埲奜偵梫場宆factor偲塢偆曄悢偑偁傝丆僨乕僞暘愅偱偼悢抣宆偲暲傫偱偙傟傪巊偆帠偵側傞丅
丂扨側傞暥帤宆償僃僋僩儖偺q02偐傜丆梫場宆偺償僃僋僩儖q03傪嶌惉偟偰傒傛偆丅
q03 <- factor(q02)
丂嶼弍暯嬒偼栜榑寁嶼偝傟側偄偑丆summary( ) 傪巊偆偲搙悢暘晍昞偑弌椡偝傟傞揰偱character偲堎側傞丅class(q03) 偲偡傞偲"factor"偲弌椡偝傟傞丅q02; q03偲偟偰偨偩扨偵拞恎傪昞帵偝偣傞偩偗偱傕丆factor偺曽偩偗乽Levels: 偦偺懠 彈惈 抝惈乿偲塢偆峴偑弌椡偝傟偰偄傞丅丂偨偩丆崯偺樤偩偲丆q03偺忣曬偼丆乽偦偺懠乿偑愭摢偱乽抝惈乿偑枛旜偲偟偰張棟偝傟傞丅summary(q03)傕偟偔偼table(q03)偱妋擣弌棃傞捠傝偱偁傞丅応崌偵傛偭偰偼丆埥偄偼曄悢偵傛偭偰偼丆抣偺庬椶乮悈弨乯偺暲傃曽傪巜掕偟偨偄応崌偑偁傞丅偦偆偟偨応崌偵偼丆梫場宆偵偡傞嵺偵丆levels=偲塢偆僆僾僔儑儞傪巜掕偡傞偲壜擻偵側傞丅
q04 <- factor(q02, levels=c("抝惈", "彈惈", "偦偺懠"))
丂summary( ) 傗 table( ) 偱妋擣偟偰梸偟偄丅
丂梫場宆曄悢偼柤媊広搙偲偟偰埖傢傟傞丅柤媊広搙傗弴彉広搙偺僇僥僑儕僇儖曄悢傪暘愅偡傞嵺偵偼丆偒偪傫偲梫場宆偺"factor"偵側偭偰偄傞偐偳偆偐傪妋擣偟丆"numeric"偵側偭偰偄傟偽忋偺條偵"factor偵"曄姺偟偨怴曄悢傪嶌惉偟偰偐傜暘愅偵梡偄傛偆丅
寚懝抣(NA)
丂幮夛挷嵏偱偼丆忣曬傪摼傛偆偲偟偰傕摼傜傟側偄応崌偑懡乆偁傞丅摼傜傟側偐偭偨忣曬傪乽寚懝乿傗乽寚應乿丆missing value 偲屇傇丅丂MS-Excel傗csv偱僨乕僞丒僼傽僀儖傪嶌惉偡傞嵺丆寚懝抣偵偼丆梊傔寛傔偰偍偄偨儖乕儖偵廬偭偰9傗99傪擖椡偟偨傝丆扨偵嬻棑偵偟偰偍偄偨傝偡傞丅9傗99側偳偺悢抣偑擖椡偝傟偰偄傞応崌偼丆偦傟傪撉傒崬傫偱嶌惉偝傟偨R偺僨乕僞丒僼儗僀儉偱傕9傗99偲偟偰懠偺悢抣偲摨條偵埖傢傟傞丅摿偵偦傟偑寚懝抣傪堄枴偡傞偲塢偆帠偼峫椂偝傟側偄偺偱拲堄偑昁梫偱偁傞丅csv僼傽僀儖偱嬻棑偵側偭偰偄傞僙儖偵偮偄偰偼丆R偱偺寚懝抣傪堄枴偡傞 NA 偲偟偰僨乕僞丒僼儗僀儉偵撉傒崬傑傟傞丅
丂9傗99偲偟偰撉傒崬傑傟傞偲丆偆偭偐傝桳岠側僨乕僞偩偲偟偰寁嶼偵娷傑傟偨傝偡傞偺偱拲堄偑昁梫偱偁傝丆NA偲偟偰撉傒崬傑傟傞偲丆偆偭偐傝桳岠埖偄偵偝傟傞帠偼柍偄偑丆媡偵娭悢偑堄恾偟偨寁嶼寢壥傪曉偝側偄帠偑偁偭偨傝偟偰柺搢偱偁傞丅
丂師偺條偵丆嵟屻偺寚懝抣偺晹暘偩偗偑堎側傞擇偮偺償僃僋僩儖偱帋偟偰傒傛偆丅
q05a <- c(12, 12, 14, 18, 16, 16, 9, 16, 12, 16, 99)
q05b <- c(12, 12, 14, 18, 16, 16, 9, 16, 12, 16, NA)
丂summary(q05a)偲summary(q05b)偺寢壥傪尒斾傋傞偲丆q05a偼懘偺樤偱巊梡弌棃側偄帠偑暘偐傞丅q05b <- c(12, 12, 14, 18, 16, 16, 9, 16, 12, 16, NA)
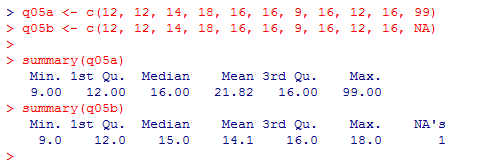
丂偟偐偟丆q05b偼丆summary( )娭悢偱偼栤戣傪惗偠側偄偑丆mean( ) 傗 sd( ) 偲塢偭偨婎杮揑側娭悢偱丆懘偺樤偱偼寁嶼傪嫅斲偝傟偰偟傑偆丅偄偢傟傕丆寢壥偑 NA 偱曉偭偰偒偰偟傑偆丅
丂偙傟傪杊偖偵偼丆mean(q05b, na.rm=T) 傗 sd(q05b, na.rm=T) 偺條偵丆na.rm=T 偲塢偆僆僾僔儑儞傪捛壛偟側偗傟偽側傜側偄丅
丂傑偨丆搙悢暘晍昞傪嶌惉偟傛偆偲 table(q05b) 偲偡傞偲崱搙偼NA偑帺摦揑偵彍奜偝傟偰弌椡偝傟傞偑丆偙傟偱偼 NA 偑懚嵼偡傞偺偐偳偆偐暘偐傜側偄丅僨乕僞傗僼傽僀儖偺僠僃僢僋嶌嬈側偳偱偼丆寚懝抣傪娷傫偱搙悢暘晍昞傗暘妱昞乮僋儘僗昞乯傪嶌惉偟側偗傟偽側傜側偄偺偱晄曋偱偁傞丅偙偺応崌偼 table(q05b, useNA="always") 枖偼 table(q05b, useNA="ifany") 偲偟側偗傟偽側傜側偄丅useNA=偺僆僾僔儑儞傪徣棯偟偨応崌偼帺摦揑偵 useNA="no" 偲偟偰埖傢傟偰偄傞偺偱偁傞丅

丂偦偺懠丆憡娭學悢傪媮傔傞娭悢 cor( ) 傕丆NA偑娷傑傟偰偄傞偲寁嶼偟偰偔傟側偄偺偱丆cor(x, y , use="complete") 偺條偵丆use="complete"傕偟偔偼use="pairwise"偺僆僾僔儑儞傪巜掕偟側偗傟偽側傜側偄丅
丂僨乕僞廤寁傗暘愅偱壗屘偐寁嶼寢壥偑 NA 偲偟偰曉偝傟傞応崌偵偼丆僨乕僞偺拞偵NA偑娷傑傟偰偄傞偺偵揔愗偵偦傟傪彍奜偟偰偄側偄壜擻惈傪峫偊偰尒傛偆丅傑偨 table( ) 傪巊梡偡傞帪偵偼丆useNA="always"偺僆僾僔儑儞傪晅偗偨応崌偲尒斾傋偰丆NA偺桳柍傪妋擣偡傞條偵偟傛偆丅
丂寚懝抣傪張棟偡傞僆僾僔儑儞偺巜掕偺巇曽偼娭悢偵傛偭偰堎側偭偰偄傞帠傕偁傞偺偱丆抦偭偰偄傞僆僾僔儑儞偱偆傑偔峴偐側偄応崌偵偼僂僃僽側偳偱挷傋偰傒傛偆丅
儕僐乕僪丆曄悢偺壛岺
丂幮夛挷嵏偱偼夞摎慖戰巿偺悢帤傪懘偺樤僨乕僞僼傽僀儖偵婰榐偡傞偺偑捠椺偩偑丆夞摎慖戰巿斣崋偑暘愅壜擻側悢検曄悢偵側傞偲偼尷傜側偄丅丂椺偊偽丆嵟廔妛楌school偑乽拞妛=1丆崅峑=2丆抁婜戝妛=3丆巐擭惂戝妛=4乿偲偟偰婰榐偝傟偰偄傞応崌丆偙傟傪嫵堢擭悢乮偦傟偧傟丆9丆12丆14丆16乯偲偟偰暘愅偵梡偄偨偄帠偑懡偄丅
壖偵10恖暘偺僨乕僞 school <- c(3, 3, 2, 2, 4, 2, 4, 3, 1, 4, 4) 偱偁傞偲偟傛偆丅
SPSS偱偁傟偽 recode 偲塢偆僐儅儞僪傪巊偆偑丆R偵摨偠傕偺偼柍偄丅偳傫側僐儞僺儏乕僞尵岅偵傕偁傞if暥偲塢偆偺傪巊偆曽朄傕偁傞偑丆school偼偁偔傑偱堦偮偺悢帤偱偼側偔償僃僋僩儖偱偁傞帠傪偒偪傫偲棟夝偟偰偄側偄偲丆堄恾偟偨摦嶌傪偟側偄丅
丂乽school偑1側傜偽edu傪9偵偡傞乿傪懘偺樤僐儅儞僪偵昞尰偡傞偲丆 if (school == 1) edu <- 9 偲側傝偦偆偩偑丆school == 1 偼school偑堦偮偺悢帤偱偁傞帠傪憐掕偟偰偄傞昞尰偲側偭偰偍傝偆傑偔峴偐側偄丅昞帵偝傟傞僄儔乕儊僢僙僀僕偲 edu 偺撪梕傪妋擣偡傟偽暘偐傞丅

丂school帺懱偼償僃僋僩儖偱偁傝丆偦偺拞偺梫慺偑1偵摍偟偄偐斲偐傪昡壙偟偨偄偺偱丆埲壓偺條偵偡傞偲堄恾偟偨寢壥偵側傞丅
edu <- NULL
edu[school == 1] <- 9
丂[ ] 偼償僃僋僩儖拞偺梫慺傪巜掕偡傞堊偺傕偺偱偁偭偨丅偙偺 [ ] 偺拞偵彂偄偰偁傞傕偺偼梫慺偵偮偄偰偺忦審偱偁傞偲夝庍偝傟丆乬school偺抣偑1偱偁傞働乕僗乮峴乯偵偮偄偰偼edu偺抣偵9傪戙擖偣傛乭偲塢偆堄枴偵側傞丅扐偟偙偺応崌丆婛偵edu偲塢偆償僃僋僩儖偑懚嵼偟偰偄傞帠傪慜採偲偟偨昞尰偵側傞偺偱丆愭偵edu傪嬻敔(NULL)偲偟偰嶌惉偟偰偍偔丅嶌惉偝傟偨edu傪妋擣偡傞偲堦儠強偩偗9偵側偭偰偍傝丆懠偼NA偑戙擖偝傟偰偄傞丅偙偺曽幃偱堄恾偟偨曄姺偼壜擻偩偑丆school偺慡偰偺抣偵偮偄偰幃傪彂偐側偗傟偽側傜側偄丅edu[school == 1] <- 9

丂傕偭偲岠棪揑側曽朄偲偟偰丆師偺條側曽朄偑偁傞丅
edu <- c(9, 12, 14, 16)[school]
丂c(9, 12, 14, 16)偼償僃僋僩儖偱偁傞丅c(9, 12, 14, 16)偺梫慺傪巜掕偟偨偄応崌丆c(9, 12, 14, 16)[2]側偳偲偡傞帠偵側傞丅梫慺偼暋悢傪巜掕偡傞帠偑弌棃傞偺偱丆c(9, 12, 14, 16)[c(2, 3)]側偳偲偡傞帠偑弌棃傞乮[2, 3]偲巜掕偡傞偲擇師尦償僃僋僩儖偺2峴3楍栚傪巜帵偟偰偄傞帠偵側傞偺偱僄儔乕偵側傞乯丅school傕堦師尦償僃僋僩儖偱偁傞偺偱丆偙偆偟偨償僃僋僩儖偺梫慺巜掕傪墳梡偟偰SPSS偺recode摨條偵乮埥偄偼傛傝娙扨偵乯怴曄悢傪嶌惉偡傞帠偑弌棃傞偺偱偁傞丅
丂偙偙偱丆嵟弶偺僨乕僞偵寚懝抣偺堄枴偱99偑婰榐偝傟偰偄傞応崌傪峫偊傛偆丅
school <- c(3, 3, 2, 2, 4, 2, 4, 3, 1, 4, 99)
丂c(9, 12, 14, 16)偵傕99斣栚偺梫慺傪捛壛偡傞偺偼乮娙扨偵弌棃傞帠偼弌棃傞偑乯柺搢偱偁傞丅傑偨丆忋偺寚懝抣偺売強偱弎傋偨條偵丆99偼NA偲偟偰撉傒崬傫偩曽偑椙偄丅丂幚偼愭偺 edu <- c(9, 12, 14, 16)[school] 傪懘偺樤梡偄傞偲丆99傪NA偵偡傞曄姺傕堦弿偵弌棃傞丅償僃僋僩儖c(9, 12, 14, 16)偺99斣栚偺梫慺傪巜掕偟傛偆偲偡傞偲丆偦傫側梫慺偼懚嵼偟側偄偺偱NA偵側傞偺偱偁傞丅傛偭偰丆寚懝抣偵曄姺偟偨偄抣偵偮偄偰偼丆傢偞傢偞弨旛偡傞昁梫偑柍偄丅

丂杮恖妛楌school丆攝嬼幰妛楌sschool丆晝妛楌fschool丆曣妛楌mschool偵慡偰摨偠曄姺傪巤偟偨偄応崌丆曄姺偵梡偄傞償僃僋僩儖偵柤慜傪晅偗偰巊梡偡傞偲偡偭偒傝偟偰尒堈偄丅
x <- c(9, 12, 14, 16)
edu <- x[school]; sedu <- x[sschool]; fedu <- x[fschool]; medu <- x[mschool]
edu <- x[school]; sedu <- x[sschool]; fedu <- x[fschool]; medu <- x[mschool]
丂擭廂側偳偺僨乕僞傕丆杮恖擭廂丆攝嬼幰擭廂丆悽懷擭廂側偳偺忣曬傪庢摼偟偰偄偨傝偡傞偺偱丆偙偆偟偨曄姺偑曋棙偱偁傞丅埲壓偼丆僨乕僞丒僼儗僀儉data01拞偺杮恖擭廂q24丆攝嬼幰擭廂q25丆悽懷擭廂q26偺慖戰巿斣崋忣曬傪丆擭廂妟傪昞偡income丆sincome丆fincome偵曄姺偡傞椺偱偁傞丅慖戰巿斣崋1偐傜16偵偼擭廂僇僥僑儕偑妱傝摉偰傜傟偰偍傝丆17偼乽傢偐傜側偄乿丆18偼乽摎偊偨偔側偄乿偲側偭偰偄傞傕偺偲偡傞丅17丆18偼寚懝抣偵偟偨偄偺偱丆1乣16偵懳墳偡傞嬥妟傪巜掕偡傟偽椙偄丅
x_inc <- c(0, 25, 75, 125, 200, 300, 400, 500, 600, 700, 800, 925, 1125, 1375, 1750, 2250)
data01$income <- x_inc[data01$q24]
data01$sincome <- x_inc[data01$q25]
data01$fincome <- x_inc[data01$q26]
data01$income <- x_inc[data01$q24]
data01$sincome <- x_inc[data01$q25]
data01$fincome <- x_inc[data01$q26]
丂惈暿偼傛偔乽抝惈=1丆彈惈=2乿乮挷嵏偵傛偭偰偼峏偵乽偦偺懠=3乿摍偑偁傞乯偲婰榐偝傟偰偄傞偑丆懎偵乽抝惈僟儈乕乿乮埥偄偼彈惈僟儈乕乯偲屇偽傟傞曄悢偵曄姺偟偨偄帠偑偟偽偟偽偁傞丅抝惈僟儈乕曄悢偲偼丆抝惈偱偁傟偽1丆偦偆偱側偗傟偽0偺抣傪偲傞曄悢偺帠偱偁傞丅曄悢sex偼1乮抝惈乯丆2乮彈惈乯丆3乮偦偺懠乯偺抣傪庢傞偲偡傞偲丆抝惈僟儈乕male偼師偺條偵嶌惉弌棃傞丅
male <- c(1, 0, 0)[sex]
彈惈僟儈乕側傜 female <- c(0, 1, 0)[sex] 偱偁傞丅丂忋偺shool曄悢傪丆弶摍妛楌乮媊柋嫵堢乯乛拞摍妛楌乮崅峑乯乛崅摍妛楌乮抁戝埲忋乯偺3嬫暘偺柤媊広搙gaku偵曄姺偡傞偵偼師偺條偵偡傟偽椙偄丅
gaku0 <- c(1, 2, 3, 3)[school]
gaku <- factor(gaku0, levels=c(1, 2, 3), labels=c("弶摍", "拞摍", "崅摍"))
gaku
summary(gaku)
gaku <- factor(gaku0, levels=c(1, 2, 3), labels=c("弶摍", "拞摍", "崅摍"))
gaku
summary(gaku)
