- 基本演算とヴェクトル・行列,データ・フレイムの作成
- 確率分布を読み取ったりグラフに描いたりする方法
- 欠損値,変数のリコード
- 一つのカテゴリカル変数の度数分布表の作成
- 多項選択回答の表の作成
- 分割表(クロス表)の作成
統計分布・確率分布の読み取りをRで行う
大抵の統計学のテクストなどでは,巻末に「統計分布表」などが付表としてついていて,標準正規分布やχ2分布,t分布,F分布などから値を読み取る一覧表が掲載されている。しかし,これらの表は紙幅の都合から一部の代表的な値だけを掲載しており,自分の欲しい値が掲載されていない場合などは近似的に読み取る事になる。
手元にRさえあれば,これらの不十分な付表を参照する必要はなくなる。以下では,Rを統計分布表代わりに使用する為の基本的なコマンドを紹介する。
正規分布,標準正規分布
正規分布は英語で normal distribution と良い,Rでの関連コマンドには norm の文字が入る。統計分布についてのRの関数には,あるxに対する確率密度を求める d... と累積確率を求める p... ,ある累積確率に対応するxの値を求める q...,そして,確率分布に従った乱数を希望の数だけ生成する r... の4つがある。最後の r... は若干用途が異なり初心者にはやや難易度が高く感じられるだろうから,まずは最初の3つを理解する事が重要である。
正規分布には,変化し得る要素として平均 mean と標準偏差 sd の二つがある。これらを特定しなければ,正規分布が定まらない。標準正規分布では mean=0, sd=1 である。
標準正規分布において,-∞ から 1.96 までの累積確率は,コンソール画面或いはRエディタで pnorm(1.96, mean=0, sd=1) とすれば求められる。-∞からの累積確率である事に注意しよう。確率密度は dnorm(1.96, mean=0, sd=1) であるが,これはグラフを描画する時くらいしか使わないだろう。
逆に,-∞からの累積確率が .975 つまり97.5%になる座標は,qnorm(.975, mean=0, sd=1) で求める事が出来る。
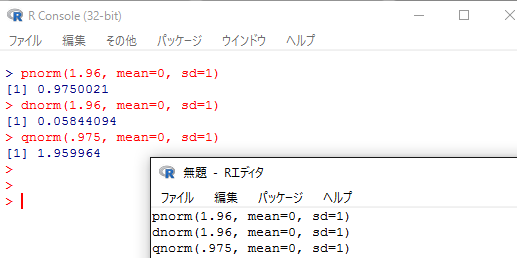
統計学の授業でよく出てくる,標準正規分布の±1.64の範囲の面積,±1.96の範囲の面積は,次の様に求める事が出来る。
pnorm(1.64, mean=0, sd=1) - pnorm(-1.64, mean=0, sd=1)
pnorm(1.96, mean=0, sd=1) - pnorm(-1.96, mean=0, sd=1)
結果を見るといずれも僅かに誤差がある。誤差のない正確な座標を求めたければ次の様にする。pnorm(1.96, mean=0, sd=1) - pnorm(-1.96, mean=0, sd=1)
qnorm(.050, mean=0, sd=1); qnorm(.950, mean=0, sd=1)
qnorm(.025, mean=0, sd=1); qnorm(.975, mean=0, sd=1)
qnorm(.025, mean=0, sd=1); qnorm(.975, mean=0, sd=1)
「値の代入」を用いると,次の様な事も出来る。meanやsdの値も変数化する事が出来る。
x <- 2.58
pnorm(x, mean=0, sd=1) - pnorm(-1*x, mean=0, sd=1)
p <- .99
qnorm((1-p)/2, mean=0, sd=1); qnorm(p+(1-p)/2, mean=0, sd=1)
x2 <- 1.96
pnorm(x, mean=0, sd=1) - pnorm(x2, mean=0, sd=1)
pnorm(x, mean=0, sd=1) - pnorm(-1*x, mean=0, sd=1)
p <- .99
qnorm((1-p)/2, mean=0, sd=1); qnorm(p+(1-p)/2, mean=0, sd=1)
x2 <- 1.96
pnorm(x, mean=0, sd=1) - pnorm(x2, mean=0, sd=1)

カイ二乗分布
カイ二乗分布とは,それぞれ独立に標準正規分布に従う複数の変数(標準正規変量)の二乗和として定義される。標準正規変量の個数を,カイ二乗分布の自由度と呼ぶ。定義上,カイ二乗分布は0以上の値しか取らない。期待値は自由度df=νに等しい。
自由度νのカイ二乗分布において,0からあるx座標までの累積確率を求める関数が pchisq(x, df) である。
例えば,自由度6のカイ二乗分布において0から10.6までの累積確率は pchisq(10.6, df=6) で求められる。10.6から先の部分の面積を求めたければ,1-pchisq(10.6, df=6) とすれば良い。
逆に,0からの累積確率が.90になる座標を求めたければ,qchisq(.90, df=6) とすれば良い。
自由度と座標の値を指定して,そこから先の部分の面積(確率)を求めるスクリプトは以下。
df <- 6
q <- 16.8
p <- pchisq( q, df); 1-p
最後の行は,1-(p <- pchisq( q, df)) と書く事も出来る。式の中で使うオブジェクトをその場で代入しているのである。q <- 16.8
p <- pchisq( q, df); 1-p
自由度と累積確率を指定して,それに対応するx座標を求めるスクリプトは以下。
df <- 6
p <- .95
q <- qchisq( p, df); q
グラフ描画を一緒に行う方法は下の方で示す。
p <- .95
q <- qchisq( p, df); q
t分布
t分布は,一つの標準正規変量と,それとは独立な一つのカイ二乗変量によって定義される。カイ二乗分布には自由度があるので,それがt分布の自由度になる。t分布は標準正規分布を頂点から少し押し潰した様な形をしており,0を中心として左右対称であり,頂点は標準正規分布より低いが,左右の裾は標準正規分布より盛り上がる。
自由度と左右対称の座標値を指定して,その座標に挟まれた範囲の面積(確率)を求める関数は pt(q, df) であり,スクリプト例は以下。
df <- 12
q <- 1.96
p <- pt( q, df) - pt( -1*q, df); p
自由度と中心部の面積(確率)を指定して,それに対応するx座標を求める関数は qt(p, df) であり,スクリプト例は以下。q <- 1.96
p <- pt( q, df) - pt( -1*q, df); p
df <- 12
p <- .95
qt((1-p)/2, df); qt(p+(1-p)/2, df)
グラフ描画を一緒に行う方法は下の方で示す。
p <- .95
qt((1-p)/2, df); qt(p+(1-p)/2, df)
F分布
F分布は,二つの独立なカイ二乗変量によって定義されるので,自由度を二つ持つ事になる。定義域は0以上であり,少しカイ二乗分布に似た形をしている。二つの自由度とx軸の座標値を指定して,そこから先の範囲の面積(確率)を求める関数は pf(q, df1, df2) であり,スクリプト例は以下。
df1 <- 5
df2 <- 1200
q <- 2.58
1-pf(q, df1, df2)
二つの自由度と累積確率を指定して,それに対応するx軸座標を求める関数は qf(p, df1, df2) であり,スクリプト例は以下。df2 <- 1200
q <- 2.58
1-pf(q, df1, df2)
df1 <- 5
df2 <- 1200
p <- .975
qf(p, df1, df2)
df2 <- 1200
p <- .975
qf(p, df1, df2)
ポワソン分布,二項分布
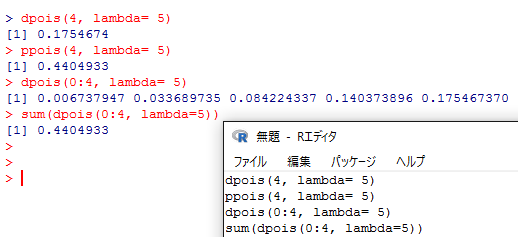
正規分布,カイ二乗分布,t分布はいずれも連続分布と呼ばれるが,分割表(クロス表)や比率の推測の分析では,整数値しか取らない離散分布であるポワソン分布や二項分布も登場する。ポワソン分布は,単位時間当たりの出来事の生起確率を表現するのに使われる。期待値(平均)を自然数で指定すると,どんな生起回数がどんな確率で生じるかを求める事が出来る。
例えば,期待値lambda=5のポワソン分布において,実際に4回となる確率は,dpois(4, lambda= 5) で求められ,0回から4回となる累積確率は ppois(4, lambda= 5) で求められる。累積確率は,0回,1回,2回,3回,4回となる確率の合計であるが,これらの確率は dpois(0:4, lambda= 5) とすればそれぞれ求められる。また,合計の関数 sum( ) を用いれば,個々の確率と累積確率が一致する事が確認できる。 sum(dpois(0:4, lambda= 5)) とすれば,ppois(4, lambda= 5) と一致している。
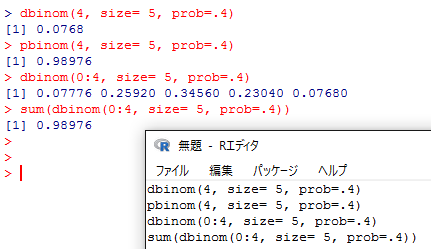
二項分布は,試行回数sizeと成功確率probを指定した場合に,何回の成功がどの程度の確率で生じるかを表す。成功確率.4の試行を5回行った時に,4回成功する確率は dbinom(4, size= 5, prob=.4),成功回数が0回〜4回の累積確率は pbinom(4, size= 5, prob=.4) で求められる。dbinom(0:4, size= 5, prob=.4) とすれば0〜4回となる確率がそれぞれ求められ,その合計 sum(dbinom(0:4, size= 5, prob=.4)) は pbinom(4, size= 5, prob=.4) と一致する。
統計分布・確率分布のグラフをRで描く
正規分布
単に数字だけでなく,グラフで図示しながら考えると効果的である。Rで簡単に統計分布のグラフを描く事を覚えよう。標準正規分布の最低限の確率密度分布グラフは,curve(dnorm(x, mean=0, sd=1), from=-3, to=3) で描ける。 これに次の一行を追加すると,真ん中95%領域が図示される。
segments(seq(-1.96, 1.96, by=.01), 0, seq(-1.96, 1.96, by=.01), dnorm(seq(-1.96, 1.96, by=.01), mean=0, sd=1))
しかしこれではスクリプトがかなり煩雑なので,次の様に,ヴェクトル,代入,省略を利用するとすっきりする。上のコマンドと全く同じ意味になるのでよく見比べよう。
segments(x0 <- seq(-1.96, 1.96, by=.01), 0, x0, dnorm(x0, 0, 1))
更に次の様にすると,最初のqに代入する値を変えるだけで好きなグラフが描ける。
q <- 1.96
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1))
以上では,グラフだけ見ると座標も面積(=確率)も分からないので,それらもグラフに書き込みたい。色々な方法が考えられる。最初の方法は,グラフタイトルなどグラフオプションを利用する方法である。paste( )関数を新たに用いている。
q <- 1.64
p <- pnorm(q, mean=0, sd=1) - pnorm(-1*q, mean=0, sd=1) # 予め面積を計算しておく
curve(dnorm(x, mean=0, sd=1), from=-3, to=3,
main=paste("真ん中の面積", round(p, 4)),
xlab=paste(-1*q, "から", q, "までの範囲"))
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1))
次の方法は,グラフの中に書き込む方法である。見栄えは未だ綺麗だとは言えないが,取り敢えず q だけ指定すれば対応する標準正規分布の面積を数値とグラフで表示出来る。p <- pnorm(q, mean=0, sd=1) - pnorm(-1*q, mean=0, sd=1) # 予め面積を計算しておく
curve(dnorm(x, mean=0, sd=1), from=-3, to=3,
main=paste("真ん中の面積", round(p, 4)),
xlab=paste(-1*q, "から", q, "までの範囲"))
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1))
q <- 1.96
p <- pnorm(q, mean=0, sd=1) - pnorm(-1*q, mean=0, sd=1)
curve(dnorm(x, mean=0, sd=1), from=-3, to=3)
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1))
text(0, 0.2, paste("面積", round(p, 4)), col="white")
text(c(-1*q, q), -0.005, c(-1*q, q), col="red")
p <- pnorm(q, mean=0, sd=1) - pnorm(-1*q, mean=0, sd=1)
curve(dnorm(x, mean=0, sd=1), from=-3, to=3)
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1))
text(0, 0.2, paste("面積", round(p, 4)), col="white")
text(c(-1*q, q), -0.005, c(-1*q, q), col="red")
逆に,面積(確率)を指定して,それに対応するx座標を図示してみよう。最初の p に代入する値だけ変えて色々と試してみると良い。
p <- .99
q <- qnorm(p+(1-p)/2, mean=0, sd=1)
curve(dnorm(x, mean=0, sd=1), from=-3, to=3)
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1))
text(0, 0.2, paste("面積", p), col="white")
text(c(-1*q, q), -0.005, round(c(-1*q, q), 4), col="red")
q <- qnorm(p+(1-p)/2, mean=0, sd=1)
curve(dnorm(x, mean=0, sd=1), from=-3, to=3)
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1))
text(0, 0.2, paste("面積", p), col="white")
text(c(-1*q, q), -0.005, round(c(-1*q, q), 4), col="red")
以下は,少しオプションなどを追加するなど加工して描いたグラフとそのスクリプトである。

p <- .90
q <- qnorm(p+(1-p)/2, mean=0, sd=1)
curve(dnorm(x, mean=0, sd=1), from=-3, to=3, bty="n", xlab="", ylab="確率密度", main="標準正規分布の面積", col="#339900")
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1), col="#339900")
text(0, 0.2, paste("面積", p*100, "%"))
axis(side=1, at=c(-1*q, q), col.axis="#006600", cex=0.8, las=2)
q <- qnorm(p+(1-p)/2, mean=0, sd=1)
curve(dnorm(x, mean=0, sd=1), from=-3, to=3, bty="n", xlab="", ylab="確率密度", main="標準正規分布の面積", col="#339900")
segments(x0 <- seq(-1*q, q, by=.01), 0, x0, dnorm(x0, 0, 1), col="#339900")
text(0, 0.2, paste("面積", p*100, "%"))
axis(side=1, at=c(-1*q, q), col.axis="#006600", cex=0.8, las=2)
カイ二乗分布
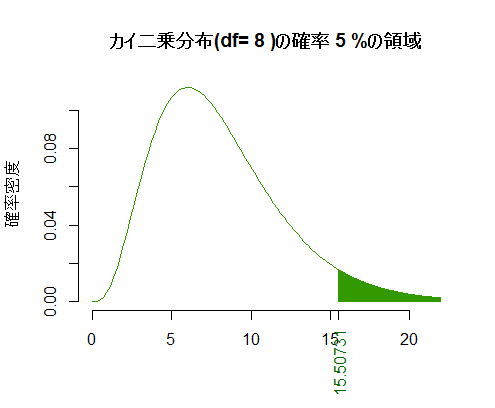
自由度dfと右裾の確率pを指定すると,対応するカイ二乗分布のグラフとx座標を描くスクリプトが以下。カイ二乗分布を参照する必要がある時に,調べたい自由度と確率(検定の場合の有意水準)を指定すれば欲しい値と共にグラフで確認出来る。
df <- 8
p <- .05
curve(dchisq(x, df), from=0, to=(upr <- qchisq(max(1-p, .995), df)),
bty="n", xlab="", ylab="確率密度", col="#339900",
main=paste("カイ二乗分布(df=", df, ")の確率", round(p*100, 2), "%の領域"))
segments(x0 <- seq(q <- qchisq( 1-p, df), upr, by=.01), 0,
x0, dchisq(x0, df), col="#339900")
axis(side=1, at=c(q), col.axis="#006600", cex=0.8, las=2)
p <- .05
curve(dchisq(x, df), from=0, to=(upr <- qchisq(max(1-p, .995), df)),
bty="n", xlab="", ylab="確率密度", col="#339900",
main=paste("カイ二乗分布(df=", df, ")の確率", round(p*100, 2), "%の領域"))
segments(x0 <- seq(q <- qchisq( 1-p, df), upr, by=.01), 0,
x0, dchisq(x0, df), col="#339900")
axis(side=1, at=c(q), col.axis="#006600", cex=0.8, las=2)
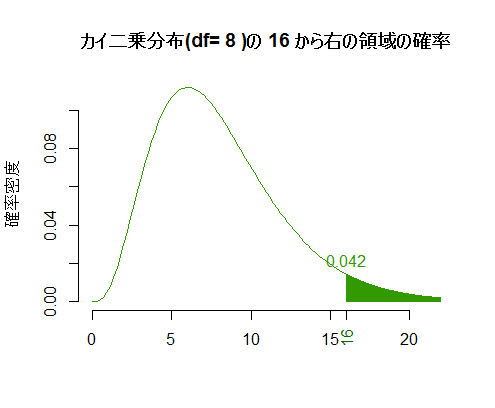
逆に,自由度dfとカイ二乗値を指定して,対応する右端確率(検定の場合の有意確率)を求めるならば以下。
df <- 8
q <- 16
curve(dchisq(x, df), from=0, to=(upr <- max(q, qchisq(.995, df))),
bty="n", xlab="", ylab="確率密度", col="#339900",
main=paste("カイ二乗分布(df=", df, ")の", q, "から右の領域の確率"))
segments(x0 <- seq(q, upr, by=.01), 0,
x0, dchisq(x0, df), col="#339900")
axis(side=1, at=c(q), col.axis="#006600", cex=0.8, las=2)
text(q, dchisq(q, df)*1.5, round(1-pchisq(q, df), 3), col="#339900")
q <- 16
curve(dchisq(x, df), from=0, to=(upr <- max(q, qchisq(.995, df))),
bty="n", xlab="", ylab="確率密度", col="#339900",
main=paste("カイ二乗分布(df=", df, ")の", q, "から右の領域の確率"))
segments(x0 <- seq(q, upr, by=.01), 0,
x0, dchisq(x0, df), col="#339900")
axis(side=1, at=c(q), col.axis="#006600", cex=0.8, las=2)
text(q, dchisq(q, df)*1.5, round(1-pchisq(q, df), 3), col="#339900")
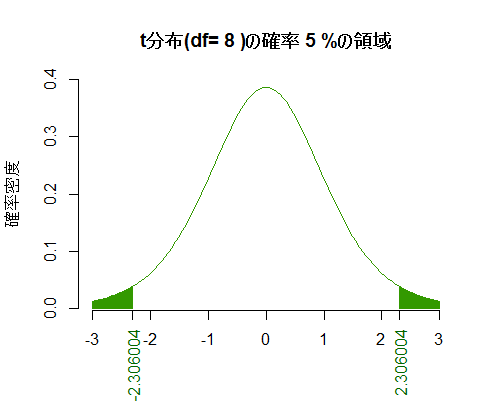
t分布
t分布も自由度を一つ指定すれば定まる。自由度と確率(有意水準)を指定すると,左右対称の裾の面積がその確率に一致する座標を計算して図示するスクリプト例を示す。
df <- 8
p <- .05
curve(dt(x, df), from=-3, to=3, bty="n", xlab="", ylab="確率密度", col="#339900",
main=paste("t分布(df=", df, ")の確率", round(p*100, 2), "%の領域"))
segments(x0 <- seq(-3, q0 <- qt(p/2, df), by=.01), 0, x0, dt(x0, df), col="#339900")
segments(x1 <- seq(q1 <- qt(1-p/2, df), 3, by=.01), 0, x1, dt(x1, df), col="#339900")
axis(side=1, at=c(q0, q1), col.axis="#006600", cex=0.8, las=2)
p <- .05
curve(dt(x, df), from=-3, to=3, bty="n", xlab="", ylab="確率密度", col="#339900",
main=paste("t分布(df=", df, ")の確率", round(p*100, 2), "%の領域"))
segments(x0 <- seq(-3, q0 <- qt(p/2, df), by=.01), 0, x0, dt(x0, df), col="#339900")
segments(x1 <- seq(q1 <- qt(1-p/2, df), 3, by=.01), 0, x1, dt(x1, df), col="#339900")
axis(side=1, at=c(q0, q1), col.axis="#006600", cex=0.8, las=2)
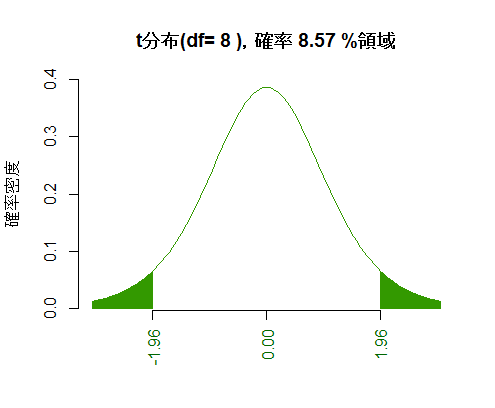
逆に,自由度と座標値xを指定して,左右の±xの外側の範囲の合計面積(有意確率)を計算して図示するスクリプト例を示す。上と違う工夫をしている部分もあるので注意する事。
df <- 8
q <- 1.96
p <- (1 - pt(q, df)) + pt(-1*q, df)
curve(dt(x, df), from=-3, to=3, bty="n", xlab="", ylab="確率密度", col="#339900",
main=paste("t分布(df=", df, "),確率", round(p*100, 2), "%領域"), xaxt="n")
segments(x0 <- c(seq(-3, -1*q, by=.01), seq(q, 3, by=.01)), 0, x0, dt(x0, df), col="#339900")
axis(side=1, at=c(-1*q, 0, q), col.axis="#006600", cex=0.8, las=2)
q <- 1.96
p <- (1 - pt(q, df)) + pt(-1*q, df)
curve(dt(x, df), from=-3, to=3, bty="n", xlab="", ylab="確率密度", col="#339900",
main=paste("t分布(df=", df, "),確率", round(p*100, 2), "%領域"), xaxt="n")
segments(x0 <- c(seq(-3, -1*q, by=.01), seq(q, 3, by=.01)), 0, x0, dt(x0, df), col="#339900")
axis(side=1, at=c(-1*q, 0, q), col.axis="#006600", cex=0.8, las=2)
次の一行を追加すると,標準正規分布を重ね書きする事も出来る。
curve(dnorm(x, 0, 1), -3, 3, add=T, col="red")
F分布
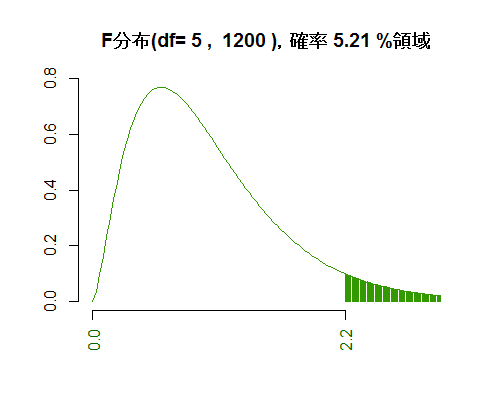
二つの自由度とF統計量(x座標値)を与えると,その右側の範囲の面積(有意確率)を示すスクリプト。
df1 <- 5
df2 <- 1200
q <- 2.2
p <- 1-pf(q, df1, df2); upr <- max(q, qf(.99, df1, df2))
curve(df(x, df1, df2), from=0, to=upr, bty="n", xlab="", ylab="", xaxt="n", col="#339900",
main=paste("F分布(df=", df1, ", ", df2, "),確率", round(p*100, 2), "%領域"))
segments(x0 <- seq(q, upr, by=.01), 0, x0, df(x0, df1, df2), col="#339900")
axis(side=1, at=c(0, q), col.axis="#006600", cex=0.8, las=2)
df2 <- 1200
q <- 2.2
p <- 1-pf(q, df1, df2); upr <- max(q, qf(.99, df1, df2))
curve(df(x, df1, df2), from=0, to=upr, bty="n", xlab="", ylab="", xaxt="n", col="#339900",
main=paste("F分布(df=", df1, ", ", df2, "),確率", round(p*100, 2), "%領域"))
segments(x0 <- seq(q, upr, by=.01), 0, x0, df(x0, df1, df2), col="#339900")
axis(side=1, at=c(0, q), col.axis="#006600", cex=0.8, las=2)
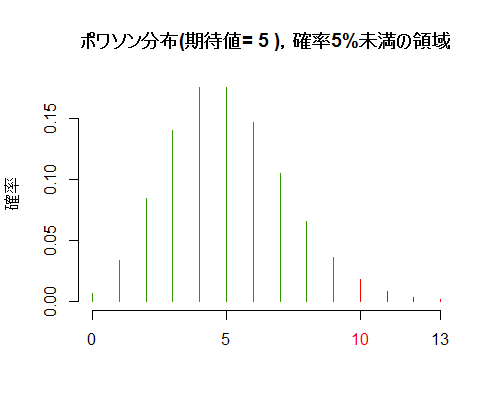
ポワソン分布,二項分布
ポワソン分布,二項分布に関しては余り描画する事が多く無いだろうから,簡単なスクリプト例のみ示しておく。右端5%未満になる領域を赤で塗り分けている。
df <- 5
q <- qpois(.95, df)
plot(x <- 0:q, dpois(x, df), bty="n", xlab="", ylab="確率", col="#339900", type="h",
main=paste("ポワソン分布(期待値=", df, "),確率5%領域"), xlim=c(0, qmax <- qpois(.999, df)),
ylim=c(0, ymax <- max(dpois(1:df*2, df))), xaxt="n")
par(new=T)
plot(x <- (q+1):qmax, dpois(x, df), bty="n", xlab="", ylab="", col="red", type="h",
xlim=c(0, qpois(.999, df)), axes=F, ylim=c(0, ymax))
axis(side=1, at=c(0, df, qmax), cex=0.8)
axis(side=1, at=q+1, col.axis="red", cex=0.8)
ppois((q-1):(q+1), df) # 境界の前後の累積確率を確認してみる。
q <- qpois(.95, df)
plot(x <- 0:q, dpois(x, df), bty="n", xlab="", ylab="確率", col="#339900", type="h",
main=paste("ポワソン分布(期待値=", df, "),確率5%領域"), xlim=c(0, qmax <- qpois(.999, df)),
ylim=c(0, ymax <- max(dpois(1:df*2, df))), xaxt="n")
par(new=T)
plot(x <- (q+1):qmax, dpois(x, df), bty="n", xlab="", ylab="", col="red", type="h",
xlim=c(0, qpois(.999, df)), axes=F, ylim=c(0, ymax))
axis(side=1, at=c(0, df, qmax), cex=0.8)
axis(side=1, at=q+1, col.axis="red", cex=0.8)
ppois((q-1):(q+1), df) # 境界の前後の累積確率を確認してみる。
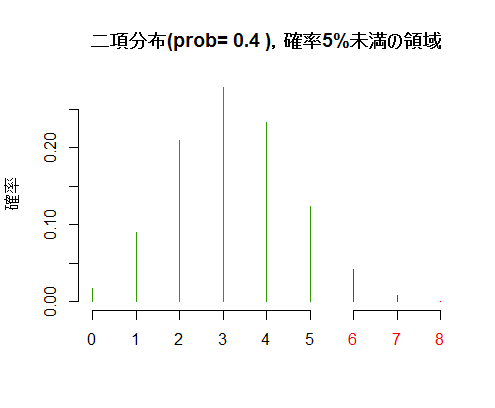
二項分布は,試行回数sと成功確率pで特定される。やはり5%未満の領域を赤く塗り分けている。
s <- 8
p <- .4
q <- qbinom(.95, s, p)
plot(x <- 0:q, dbinom(x, s, p), bty="n", xlab="", ylab="確率", col="#339900", type="h",
main=paste("二項分布(prob=", p, "),確率5%未満の領域"), xlim=c(0, s), xaxt="n",
ylim=c(0, ymax <- max(dbinom(0:s, s, p))))
par(new=T)
plot(x <- (q+1):s, dbinom(x, s, p), bty="n", xlab="", ylab="", col="red", type="h",
xlim=c(0, s), axes=F, ylim=c(0, ymax))
axis(side=1, at=0:q, cex=0.8)
axis(side=1, at=(q+1):s, col.axis="red", cex=0.8)
pbinom((q-1):(q+1), size=s, prob=p) # 境界の前後の累積確率を確認
p <- .4
q <- qbinom(.95, s, p)
plot(x <- 0:q, dbinom(x, s, p), bty="n", xlab="", ylab="確率", col="#339900", type="h",
main=paste("二項分布(prob=", p, "),確率5%未満の領域"), xlim=c(0, s), xaxt="n",
ylim=c(0, ymax <- max(dbinom(0:s, s, p))))
par(new=T)
plot(x <- (q+1):s, dbinom(x, s, p), bty="n", xlab="", ylab="", col="red", type="h",
xlim=c(0, s), axes=F, ylim=c(0, ymax))
axis(side=1, at=0:q, cex=0.8)
axis(side=1, at=(q+1):s, col.axis="red", cex=0.8)
pbinom((q-1):(q+1), size=s, prob=p) # 境界の前後の累積確率を確認
統計分布・確率分布に従う乱数を発生させる
正規分布
Rは疑似データを発生させたりシミュレイションを繰り返したりする能力に優れている。SPSSなどとはその点は圧倒的に異なっており,特に自由になる大規模データなどが無い学習者にとっては非常に便利である。ここではそのほんの一例として,幾つか疑似乱数を発生させて操作してみる。
rnorm(10, mean=0, sd=1) とすると,それぞれ独立に標準正規分布に従う乱数の実現値が10個,ヴェクトルとして得られる。イメージがしにくいと思うので試しに実行してみるのが手っ取り早い。何度か実行すればその都度異なる数値群が得られる。
少し応用して,以下のようにすると,テストの偏差値風の模擬データになる。
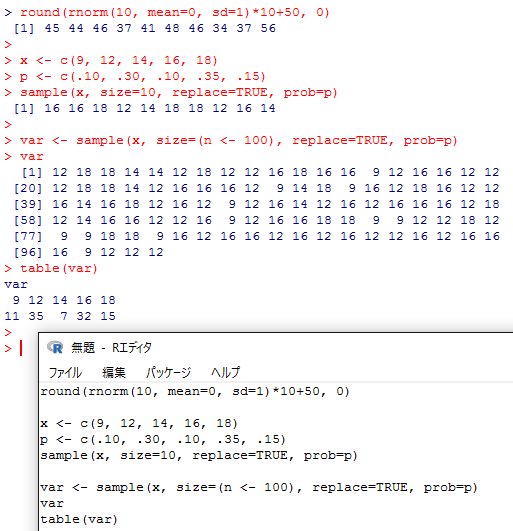
round(rnorm(10, mean=0, sd=1)*10+50, 0)
因みに乱数発生には別の方法として,無作為抽出する関数 sample( ) を利用する事が出来る。
次の例は,5つの値からなるヴェクトルxから,それぞれpの確率に応じて確率標本抽出するスクリプトである。replace=TRUE は復元抽出の為のオプション。sizeはサンプリングして取り出す個数。これも何度も繰り返し実行してみるとその都度異なる結果が得られる。
x <- c(9, 12, 14, 16, 18)
p <- c(.10, .30, .10, .35, .15)
sample(x, size=10, replace=TRUE, prob=p)
次の様に多くの乱数を発生させてみて,table( ) 関数で度数分布表を見てみると良い。
var <- sample(x, size=(n <- 100), replace=TRUE, prob=p)
var
table(var)