杉野 勇 (SUGINO Isamu) お茶の水女子大学・人間発達科学専攻・応用社会学コース担当
『入門・社会統計学』サポートウェブ |
|
 第2章 2変数の関連の記述統計
第2章 2変数の関連の記述統計
二つの変数の関連を特徴付ける。二変数が数量変数の場合と,カテゴリカル変数の場合に分かれる。1-1 散布図(scatter plot)と相関係数(correlation coefficient)
本文のような散布図を描くスクリプトを示す。一度に全て実行するよりも,少しずつ実行して結果を確認しながら進むのが良い。散布図も二つ描画されるので,ひとつずつ実行して比べるのが良い。


x0 <- rnorm(n <- 100, mean=0, sd=1) # 100個の標準正規変量
y0 <- rnorm(n, mean=0, sd=1)
lm0 <- lm(y0 ~ x0); names(lm0) # 単回帰分析。格納された情報を確認。
r0 <- lm0$residuals # 残差のヴェクトル
x1 <- (x0-mean(x0))/sqrt(mean((x0-mean(x0))^2)) # x0を標準化
r1 <- (r0-mean(r0))/sqrt(mean((r0-mean(r0))^2)) # 残差を標準化
rxy <- 0.6 # ここで相関係数を任意に指定する。
z1 <- rxy*x1 + sqrt(1-rxy^2)*r1 # ここが肝心
x2 <- x1*10+50 # x1を「偏差値」風に変換。本質的ではない。
z2 <- z1*10+50
cor(x2, z2) # 積率相関が指定したものと一致する事を確認。
# 基本の散布図
plot(x2,z2, xlim=c(10,90), ylim=c(10,90), bty="n",
main=sprintf("相関係数%.2fの散布図(n=%d)", cor(x2, z2), length(x2)),
xlab="", ylab="", family="serif", las=1)
dev.new() # 描画ウィンドウを新規に開く
# 4つの象限に分割した散布図
# x軸とy軸の描画範囲も上のものより広げている。
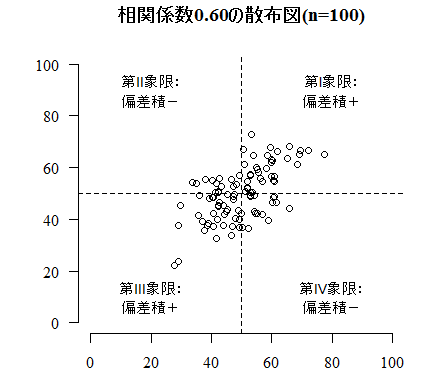
plot(x2,z2, xlim=c(0,100), ylim=c(0,100), bty="n",
main=sprintf("相関係数%.2fの散布図(n=%d)", cor(x2, z2), length(x2)),
xlab="", ylab="", family="serif", las=1)
abline(v=mean(x2), lty=2); abline(h=mean(z2), lty=2)
text(80,90,"第?象限:\n偏差積+")
text(20,90,"第?象限:\n偏差積−")
text(20,10,"第?象限:\n偏差積+")
text(80,10,"第?象限:\n偏差積−")
y0 <- rnorm(n, mean=0, sd=1)
lm0 <- lm(y0 ~ x0); names(lm0) # 単回帰分析。格納された情報を確認。
r0 <- lm0$residuals # 残差のヴェクトル
x1 <- (x0-mean(x0))/sqrt(mean((x0-mean(x0))^2)) # x0を標準化
r1 <- (r0-mean(r0))/sqrt(mean((r0-mean(r0))^2)) # 残差を標準化
rxy <- 0.6 # ここで相関係数を任意に指定する。
z1 <- rxy*x1 + sqrt(1-rxy^2)*r1 # ここが肝心
x2 <- x1*10+50 # x1を「偏差値」風に変換。本質的ではない。
z2 <- z1*10+50
cor(x2, z2) # 積率相関が指定したものと一致する事を確認。
# 基本の散布図
plot(x2,z2, xlim=c(10,90), ylim=c(10,90), bty="n",
main=sprintf("相関係数%.2fの散布図(n=%d)", cor(x2, z2), length(x2)),
xlab="", ylab="", family="serif", las=1)
dev.new() # 描画ウィンドウを新規に開く
# 4つの象限に分割した散布図
# x軸とy軸の描画範囲も上のものより広げている。
plot(x2,z2, xlim=c(0,100), ylim=c(0,100), bty="n",
main=sprintf("相関係数%.2fの散布図(n=%d)", cor(x2, z2), length(x2)),
xlab="", ylab="", family="serif", las=1)
abline(v=mean(x2), lty=2); abline(h=mean(z2), lty=2)
text(80,90,"第?象限:\n偏差積+")
text(20,90,"第?象限:\n偏差積−")
text(20,10,"第?象限:\n偏差積+")
text(80,10,"第?象限:\n偏差積−")
1-2 偏差積和と共分散(covariance)
共分散を幾つかの方法で計算して結果を比較してみよう。多くの統計ソフトの出力する共分散や分散が手計算と一致しない理由も合わせて説明している。

x <- rnorm(n <- 20, mean=0, sd=1)
y <- rnorm(n, mean=0, sd=1)
x # xの値自体を表示
x-mean(x) # xの(算術平均からの)偏差を表示
(x-mean(x))*(y-mean(y)) # xの偏差とyの偏差の偏差積を表示
sum((x-mean(x))*(y-mean(y))) # 偏差積和を表示
sum((x-mean(x))*(y-mean(y)))/length(x) # 共分散を表示・方法1
mean((x-mean(x))*(y-mean(y))) # 共分散を表示・方法2
# Rの標準関数で共分散を計算
cov(x, y)
# 値が一致しない!何故か?
# 統計ソフトは,分散・共分散を,nで割った値ではなく,n-1で割った値(不偏推定値)で示す。
# 以下の様に,n=length(x)ではなくn-1で割ると値が一致する。
sum((x-mean(x))*(y-mean(y)))/(length(x)-1) # 共分散を表示・方法3
y <- rnorm(n, mean=0, sd=1)
x # xの値自体を表示
x-mean(x) # xの(算術平均からの)偏差を表示
(x-mean(x))*(y-mean(y)) # xの偏差とyの偏差の偏差積を表示
sum((x-mean(x))*(y-mean(y))) # 偏差積和を表示
sum((x-mean(x))*(y-mean(y)))/length(x) # 共分散を表示・方法1
mean((x-mean(x))*(y-mean(y))) # 共分散を表示・方法2
# Rの標準関数で共分散を計算
cov(x, y)
# 値が一致しない!何故か?
# 統計ソフトは,分散・共分散を,nで割った値ではなく,n-1で割った値(不偏推定値)で示す。
# 以下の様に,n=length(x)ではなくn-1で割ると値が一致する。
sum((x-mean(x))*(y-mean(y)))/(length(x)-1) # 共分散を表示・方法3
1-3 ピアソンの積率相関係数(Pearson's product-moment correlation coefficient)
3つの標準正規変量を発生させて演習を行おう。また,実際の社会調査データに近付ける為に,敢えて欠損値(NA,項目無回答item nonresponseと言う)を混ぜる操作をする。

是非自分でスクリプトを試して確認して欲しい。
x <- rnorm(n <- 20, mean=0, sd=1)
y <- rnorm(n, mean=0, sd=1)
z <- rnorm(n, mean=0, sd=1)
x[c( 1, 8,15)] <- NA # ヴェクトルxの 1, 8, 15番目の値をNAに置換
y[c( 3,10,17)] <- NA
z[c( 5,12,19)] <- NA
cor(x, y) # オプションを指定しないと,NAを含む計算は結果もNAになる。
cor(x, y, use="pairwise") # ペアのいずれにもNAを含まないものに限定
cor.test(x, y) # cor.test( )関数では自動でpairwise処理
# cor( )は3つ以上のヴェクトルの相関係数行列を計算できる。
cor(cbind(x, y, z), use="pairwise") # ペアでNAが無ければ有効
cor(cbind(x, y, z), use="complete") # 全てのヴェクトルでNAを含まないケースだけが有効
cor.test(y, z) # cor( )のpairwiseの方と結果が一致する事を確認。
cor.test(z, x)
y <- rnorm(n, mean=0, sd=1)
z <- rnorm(n, mean=0, sd=1)
x[c( 1, 8,15)] <- NA # ヴェクトルxの 1, 8, 15番目の値をNAに置換
y[c( 3,10,17)] <- NA
z[c( 5,12,19)] <- NA
cor(x, y) # オプションを指定しないと,NAを含む計算は結果もNAになる。
cor(x, y, use="pairwise") # ペアのいずれにもNAを含まないものに限定
cor.test(x, y) # cor.test( )関数では自動でpairwise処理
# cor( )は3つ以上のヴェクトルの相関係数行列を計算できる。
cor(cbind(x, y, z), use="pairwise") # ペアでNAが無ければ有効
cor(cbind(x, y, z), use="complete") # 全てのヴェクトルでNAを含まないケースだけが有効
cor.test(y, z) # cor( )のpairwiseの方と結果が一致する事を確認。
cor.test(z, x)
是非自分でスクリプトを試して確認して欲しい。
1-4 相関係数と線形変換(linear transformation)
乱数を利用して,任意の相関関係にある2変数を発生させ,それを線形変換すると各種の統計量がどうなるかを簡単に示してみる。
相関係数rは-1から1の範囲で好きな値を指定出来る。そうすると,厳密にその相関関係になる変数xとyが乱数発生される。
次に,xとyから,一部予想不能な乱数を含んで線形変換したx2とy2が生成される。元のx,yと線形変換後のx2,y2で,平均,標準偏差,共分散などは全て変化してしまうが,相関係数は不変である事が確認出来る。

相関係数rは-1から1の範囲で好きな値を指定出来る。そうすると,厳密にその相関関係になる変数xとyが乱数発生される。
次に,xとyから,一部予想不能な乱数を含んで線形変換したx2とy2が生成される。元のx,yと線形変換後のx2,y2で,平均,標準偏差,共分散などは全て変化してしまうが,相関係数は不変である事が確認出来る。
r <- 0.7 # 最初に相関係数の値を任意に設定
n <- 400 # ケース数を指定
u <- rnorm(n, mean=0, sd=1) # 材料としてのヴェクトルu
x0 <- rnorm(n, mean=0, sd=1); x <- scale(x0) # このxは後で使用
e0 <- lm(u ~ x)$residuals; e <- scale(e0) # 残差を取り出す
y <- sqrt(1-r^2)*e + r*x # xとyの相関が厳密にrになる
cor(x, y) # 確かに設定した相関になっている事を確認
plot(x, y) # 簡単に散布図を描いてみる
# xとyを,乱数を交えて線型変換してみる(結果が予め決まっていない)
x2 <- runif(1, min=1.1, max=5)*x + runif(1, min=-2, max=2)
y2 <- runif(1, min=0.1, max=0.9)*y + runif(1, min=-2, max=2)
mean(x); mean(x2) # 変換前後で平均が変わる
sd(x); sd(x2) # 変換前後で標準偏差も変わる
mean(y);mean(y2)
sd(y); sd(y2)
cov(x, y); cov(x2, y2) # 変換前後で共分散も変わる
cor(x, y); cor(x2, y2) # 変換前後で相関係数は不変
n <- 400 # ケース数を指定
u <- rnorm(n, mean=0, sd=1) # 材料としてのヴェクトルu
x0 <- rnorm(n, mean=0, sd=1); x <- scale(x0) # このxは後で使用
e0 <- lm(u ~ x)$residuals; e <- scale(e0) # 残差を取り出す
y <- sqrt(1-r^2)*e + r*x # xとyの相関が厳密にrになる
cor(x, y) # 確かに設定した相関になっている事を確認
plot(x, y) # 簡単に散布図を描いてみる
# xとyを,乱数を交えて線型変換してみる(結果が予め決まっていない)
x2 <- runif(1, min=1.1, max=5)*x + runif(1, min=-2, max=2)
y2 <- runif(1, min=0.1, max=0.9)*y + runif(1, min=-2, max=2)
mean(x); mean(x2) # 変換前後で平均が変わる
sd(x); sd(x2) # 変換前後で標準偏差も変わる
mean(y);mean(y2)
sd(y); sd(y2)
cov(x, y); cov(x2, y2) # 変換前後で共分散も変わる
cor(x, y); cor(x2, y2) # 変換前後で相関係数は不変
1-5 相関係数行列と散布図行列
上の1-3で発生させたx, y, zの三つのヴェクトルで例示してみよう。既に相関係数行列は上で示した。有効ケースの判断として"pairwise"と"complete"の二通りがあり,結果が異なる事に注意しなければならない。
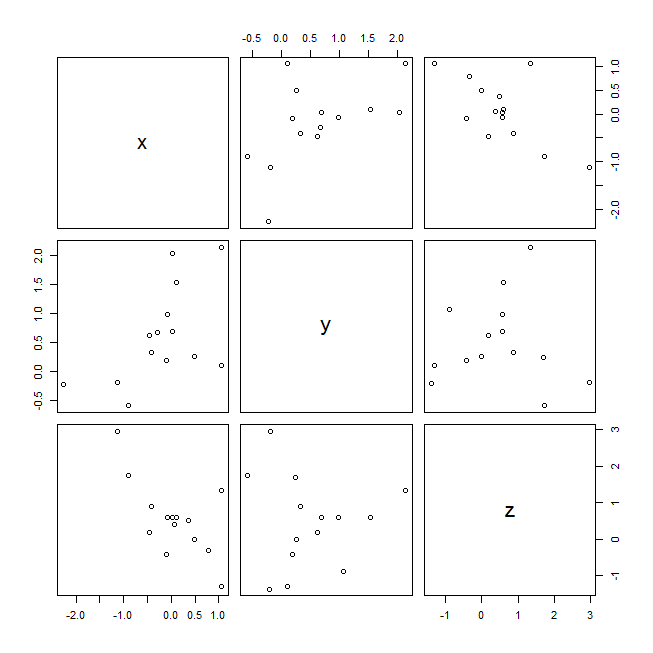
3つのヴェクトルのうちの2つの組合せで散布図が描かれているが,横軸と縦軸が入れ替わっているだけのものがあるので3組6枚の散布図になっている。次の様に2つのヴェクトルでの散布図を3組描いて,よく見比べるとどれがどれなのか分かるだろう。
# cbind( )は「列columnを結合する」と云う関数
# ヴェクトルを列結合した結果を u と云うオブジェクトに代入している。
# 以下のコマンドを実行した後で,R Consoleで u と打つとuが何かが分かる。
cor(u <- cbind(x, y, z), use="pairwise")
cor(u, use="complete")
# ここで3つのヴェクトルを含むuに,散布図を描く plot( )関数を適用しても,ひとつの散布図しか描かれない。
# plot(x, y)と見比べると同じである事が分かる。
plot(u)
plot(x, y)
# 散布図行列を描くには,単に列結合するだけでなく,それを「データ・フレイム」に変換しなければならない。
w <- data.frame(u) # 3つのヴェクトルを列結合したuをデータ・フレイム形式にする。
plot(w) # 散布図行列を描く
下が,plot(w)で描かれた散布図。pairs(w)でも同じ散布図行列が描かれる。# ヴェクトルを列結合した結果を u と云うオブジェクトに代入している。
# 以下のコマンドを実行した後で,R Consoleで u と打つとuが何かが分かる。
cor(u <- cbind(x, y, z), use="pairwise")
cor(u, use="complete")
# ここで3つのヴェクトルを含むuに,散布図を描く plot( )関数を適用しても,ひとつの散布図しか描かれない。
# plot(x, y)と見比べると同じである事が分かる。
plot(u)
plot(x, y)
# 散布図行列を描くには,単に列結合するだけでなく,それを「データ・フレイム」に変換しなければならない。
w <- data.frame(u) # 3つのヴェクトルを列結合したuをデータ・フレイム形式にする。
plot(w) # 散布図行列を描く
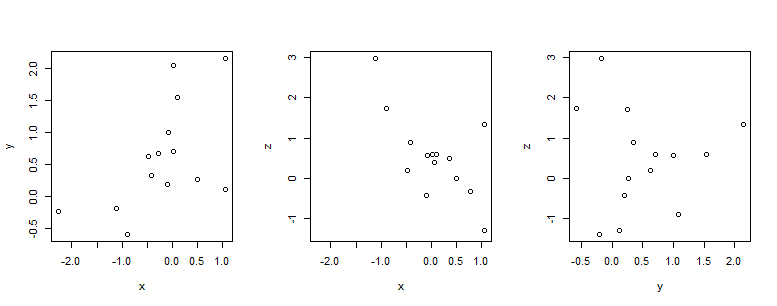
3つのヴェクトルのうちの2つの組合せで散布図が描かれているが,横軸と縦軸が入れ替わっているだけのものがあるので3組6枚の散布図になっている。次の様に2つのヴェクトルでの散布図を3組描いて,よく見比べるとどれがどれなのか分かるだろう。
par(mfrow=c(1,3)) # グラフ画面を1行3列に分割する
plot(x, y)
plot(x, z)
plot(y, z)
下がこの結果のグラフである。plot(x, y)
plot(x, z)
plot(y, z)
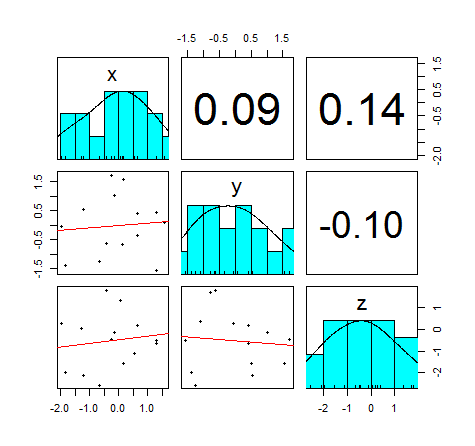
"psych"パッケイジのpairs.panels( )関数
追加パッケイジのpsychを使用すると,もっと情報量の多い散布図行列が描ける。下の例では,対角線に各変数のヒストグラム,右上三角に2変数ごとの積率相関係数,左下三角に2変数ごとの散布図と回帰直線が描かれている。
install.packages("psych", repos="https://cran.ism.ac.jp")
library(psych)
pairs.panels(w, scale=F, lm=T, ellipses=F)
library(psych)
pairs.panels(w, scale=F, lm=T, ellipses=F)
2-1 分割表(contingency table)の構成と読み取り
データ・フレイム"data"内の変数"sex"と"q1900"(大文字と小文字も区別されるので注意!)の分割表(クロス表)を作成するには,table(data$sex, data$q1900)とする。これをオブジェクト("以下ではt"とする)に代入して表示すると良い。
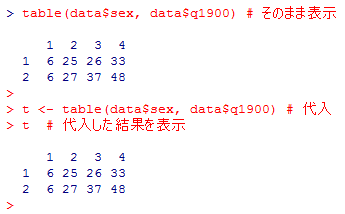
代入文だけでは結果を表示しないことには注意が必要である。代入した結果も表示したい場合には,上のように単にオブジェクト名を指定するか,もしくは代入文全体を括弧 ( ) に入れて,(t <- table(data$sex, data$q1900)) などとする。
上の例で分かるように,table( )は表の本体を表示するだけの非常に素っ気ない関数である。これに周辺度数を付加する関数が addmargins(t)である。

比率を計算するのは prop.table( )である。全体比率,行比率,列比率の3つがある事に注意しよう。
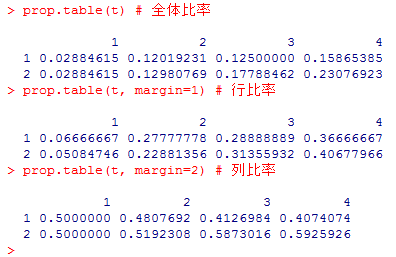
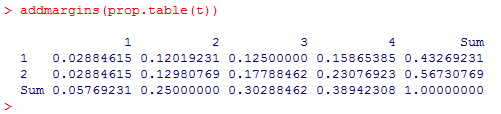
全体比率の表に周辺度数を付加すると次のようになる。
「小数ではなく%にして,その小数第一位までだけ表示したい」という場合には,次の様にすると良い。round( )は四捨五入の関数であり,最初の引数に数値オブジェクト(この場合は分割表)を指定し,二番目の引数に小数点以下の桁数を指定する。小数第一位までとすると,小数第二位を四捨五入する。上の表とよく見比べてみよう。

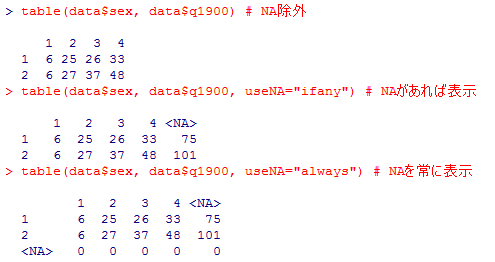
関数 table( ) は,欠損値NAは自動的に除外して集計する設定となっている。しばしばこれでは不十分であるので,NAを含んで全てのケースについての分割表を作成するオプション useNA="no|ifany|always" を紹介する。このオプションを省略した場合(デフォルト)では,useNA="no" となる。
ついでに,分割表にラベルを貼るやり方も紹介しておこう。
分割表を t とする時,names(dimnames(t)) は行変数の名前と列変数のラベル,dimnames(t)[[1]] は行変数のカテゴリのラベル,dimnames(t)[[2]] は列変数のカテゴリのラベルを意味する。
以下のスクリプトと結果をよく見て,ラベルを付ける前と付けた後を比較して欲しい。列のラベルと数値がずれている様に見えるが,コピーしてみると大丈夫である。

NAを含む場合は以下の様にする。

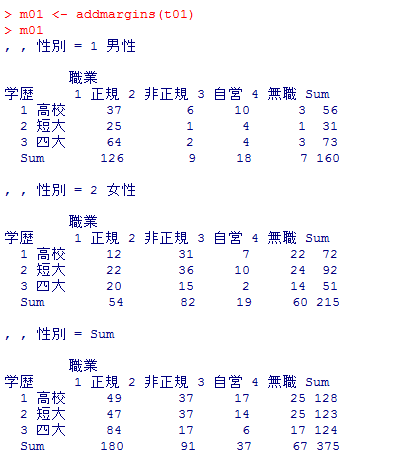
以下は,演習用データ・ファイルをdata01と云う名前のデータ・フレイムに読み込んで,性別(層変数)×学歴(行変数)×職業(列変数)の3元分割表を作成する例である。
まずは,table( )関数で単純に分割表を作成,周辺度数を付加した分割表を示す。

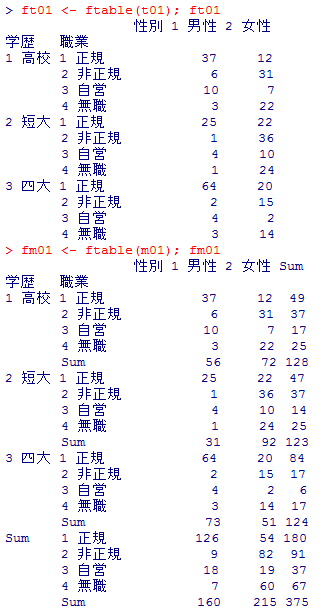
この3元分割表を2次元に縮約して表示する関数として ftable( ) がある。上の3元分割表はそれぞれ以下の様になる。
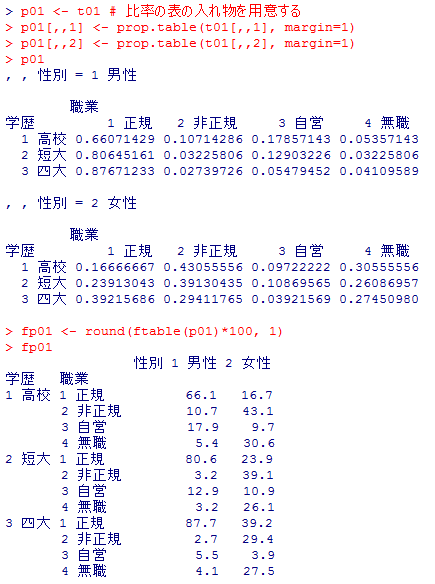
この様に簡潔な表形式で3元分割表の情報を表示する事が出来るが,度数だけではやや読み取りにくい。しかし比率を表示させるにはやや工夫が必要になる。
これだと周辺度数に相当する部分は表示されないものの,男性と女性の違いはかなり分かり易く読み取れる。
代入文だけでは結果を表示しないことには注意が必要である。代入した結果も表示したい場合には,上のように単にオブジェクト名を指定するか,もしくは代入文全体を括弧 ( ) に入れて,(t <- table(data$sex, data$q1900)) などとする。
上の例で分かるように,table( )は表の本体を表示するだけの非常に素っ気ない関数である。これに周辺度数を付加する関数が addmargins(t)である。
比率を計算するのは prop.table( )である。全体比率,行比率,列比率の3つがある事に注意しよう。
全体比率の表に周辺度数を付加すると次のようになる。
「小数ではなく%にして,その小数第一位までだけ表示したい」という場合には,次の様にすると良い。round( )は四捨五入の関数であり,最初の引数に数値オブジェクト(この場合は分割表)を指定し,二番目の引数に小数点以下の桁数を指定する。小数第一位までとすると,小数第二位を四捨五入する。上の表とよく見比べてみよう。
関数 table( ) は,欠損値NAは自動的に除外して集計する設定となっている。しばしばこれでは不十分であるので,NAを含んで全てのケースについての分割表を作成するオプション useNA="no|ifany|always" を紹介する。このオプションを省略した場合(デフォルト)では,useNA="no" となる。
table(data$sex, data$q1900) # NA除外
table(data$sex, data$q1900, useNA="ifany") # NAがあれば表示
table(data$sex, data$q1900, useNA="always") # NAを常に表示
table(data$sex, data$q1900, useNA="ifany") # NAがあれば表示
table(data$sex, data$q1900, useNA="always") # NAを常に表示
ついでに,分割表にラベルを貼るやり方も紹介しておこう。
分割表を t とする時,names(dimnames(t)) は行変数の名前と列変数のラベル,dimnames(t)[[1]] は行変数のカテゴリのラベル,dimnames(t)[[2]] は列変数のカテゴリのラベルを意味する。
以下のスクリプトと結果をよく見て,ラベルを付ける前と付けた後を比較して欲しい。列のラベルと数値がずれている様に見えるが,コピーしてみると大丈夫である。
(t <- table(data$sex, data$q1900)) # 代入して表示
names(dimnames(t0)) <- list("性別", "性別役割分業")
dimnames(t0)[[1]] <- c("1 男性", "2 女性")
dimnames(t0)[[2]] <- c("1 そう思う", "2 どち…思う", "3 どち…思わない", "4 思わない")
t
names(dimnames(t0)) <- list("性別", "性別役割分業")
dimnames(t0)[[1]] <- c("1 男性", "2 女性")
dimnames(t0)[[2]] <- c("1 そう思う", "2 どち…思う", "3 どち…思わない", "4 思わない")
t
NAを含む場合は以下の様にする。
3元分割表(3重クロス表)
ここでは2変数の連関を説明しているが,3変数以上の分割表(連関表,クロス表)についても紹介しておこう。以下は,演習用データ・ファイルをdata01と云う名前のデータ・フレイムに読み込んで,性別(層変数)×学歴(行変数)×職業(列変数)の3元分割表を作成する例である。
まずは,table( )関数で単純に分割表を作成,周辺度数を付加した分割表を示す。
data01 <- read.csv("practice.csv") # csvファイルをデータフレイムdata01として読み込む
t01 <- table(data01$edu2, data01$job, data01$sex)
names(dimnames(t01)) <- list("学歴", "職業", "性別")
dimnames(t01)[[3]] <- c("1 男性", "2 女性")
dimnames(t01)[[2]] <- c("1 正規", "2 非正規", "3 自営", "4 無職")
dimnames(t01)[[1]] <- c("1 高校", "2 短大", "3 四大")
t01
m01 <- addmargins(t01)
m01
t01 <- table(data01$edu2, data01$job, data01$sex)
names(dimnames(t01)) <- list("学歴", "職業", "性別")
dimnames(t01)[[3]] <- c("1 男性", "2 女性")
dimnames(t01)[[2]] <- c("1 正規", "2 非正規", "3 自営", "4 無職")
dimnames(t01)[[1]] <- c("1 高校", "2 短大", "3 四大")
t01
m01 <- addmargins(t01)
m01
この3元分割表を2次元に縮約して表示する関数として ftable( ) がある。上の3元分割表はそれぞれ以下の様になる。
ft01 <- ftable(t01); ft01
fm01 <- ftable(m01); fm01
fm01 <- ftable(m01); fm01
この様に簡潔な表形式で3元分割表の情報を表示する事が出来るが,度数だけではやや読み取りにくい。しかし比率を表示させるにはやや工夫が必要になる。
p01 <- t01 # 比率の表の入れ物を用意する
p01[,,1] <- prop.table(t01[,,1], margin=1)
p01[,,2] <- prop.table(t01[,,2], margin=1)
p01
fp01 <- round(ftable(p01)*100, 1)
fp01
p01[,,1] <- prop.table(t01[,,1], margin=1)
p01[,,2] <- prop.table(t01[,,2], margin=1)
p01
fp01 <- round(ftable(p01)*100, 1)
fp01
これだと周辺度数に相当する部分は表示されないものの,男性と女性の違いはかなり分かり易く読み取れる。
2-2 分割表を表現するグラフ
本文で紹介した,棒グラフ,帯グラフ,モザイクプロットのスクリプトと実例を紹介する。
まずは分割表を準備する。途中での混乱を避ける為オブジェクト名をtblとする
まずは棒グラフ barplot( ) を使用する。初めての場合はとにかく最も単純なものを実行して結果を解読するのが良いだろう。その後,必要に応じて色々なオプションを指定する事を学んでいく。
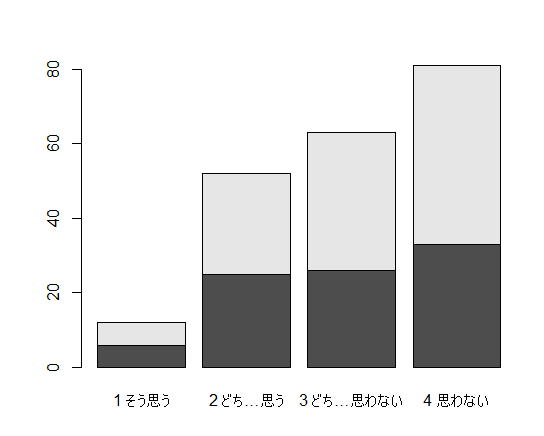
分割表に対してそのまま棒グラフを描くと,この様に積み上げ棒グラフになる。列変数ごとに,行変数の値を積み上げている事が分かる。横に並んだ単純な棒グラフを描きたい場合は,beside=T というオプションが必要になる。
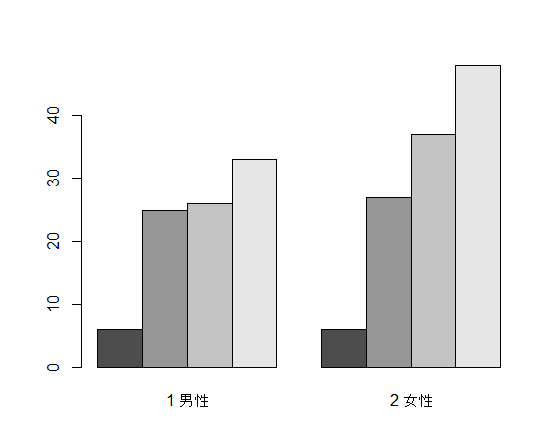
積み上げは積み上げでも,男女別に積み上げたい場合は,転置行列の関数 t( ) を使用する。
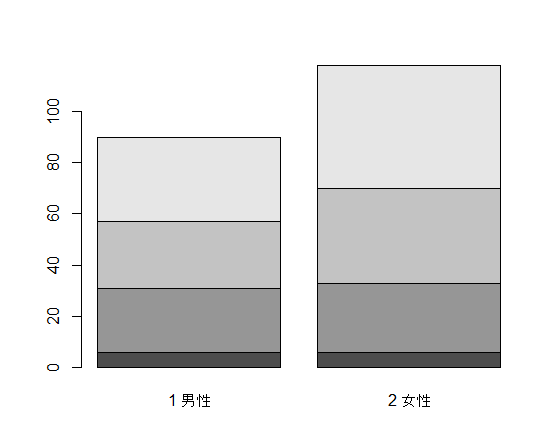
凡例が無いと見づらいので,legend.text= オプションで凡例を指定する。
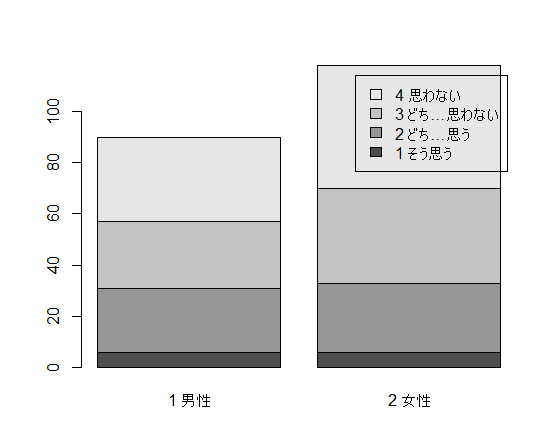
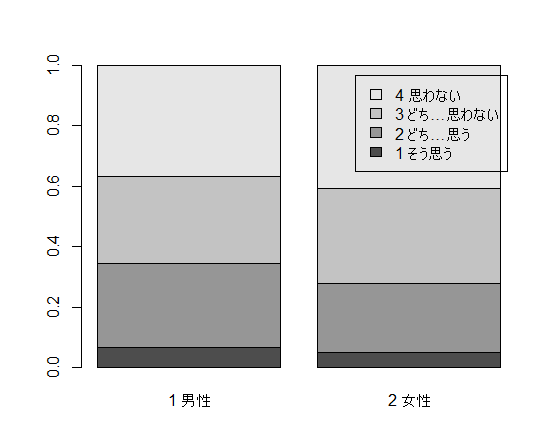
パーセンテージで表現する「帯グラフ」を描くには,分割表を比率にして積み上げ棒グラフを描けば良い。まずは prop.table(tbl, margin=1) によって行比率の分割表に変換し,それを上と同様に転置する t(prop.table(tbl, margin=1)) 。それを凡例付きで積み上げ棒グラフにする。
最後に,モザイクプロットを描く。
これでは余りに素っ気ないので,幾つかオプションを指定して装飾しよう。最後の二行の text( ) は度数を書き込んでいるものだが,中身はやや難しいので分からなくて良い。
まずは分割表を準備する。途中での混乱を避ける為オブジェクト名をtblとする
tbl <- table(data$sex, data$q1900) # オブジェクト名tbl
names(dimnames(tbl)) <- list("性別", "性別役割分業")
dimnames(tbl)[[1]] <- c("1 男性", "2 女性")
dimnames(tbl)[[2]] <- c("1 そう思う", "2 どち…思う", "3 どち…思わない", "4 思わない")
tbl # まず分割表(特に行変数と列変数)を確認する。
names(dimnames(tbl)) <- list("性別", "性別役割分業")
dimnames(tbl)[[1]] <- c("1 男性", "2 女性")
dimnames(tbl)[[2]] <- c("1 そう思う", "2 どち…思う", "3 どち…思わない", "4 思わない")
tbl # まず分割表(特に行変数と列変数)を確認する。
まずは棒グラフ barplot( ) を使用する。初めての場合はとにかく最も単純なものを実行して結果を解読するのが良いだろう。その後,必要に応じて色々なオプションを指定する事を学んでいく。
barplot(tbl) # 積み上げ棒グラフ
分割表に対してそのまま棒グラフを描くと,この様に積み上げ棒グラフになる。列変数ごとに,行変数の値を積み上げている事が分かる。横に並んだ単純な棒グラフを描きたい場合は,beside=T というオプションが必要になる。
barplot(t(t), beside=T) #単純な棒グラフ
積み上げは積み上げでも,男女別に積み上げたい場合は,転置行列の関数 t( ) を使用する。
barplot(t(tbl)) # 行と列を入れ替えたいので,転置行列の関数 t( ) を使用。
凡例が無いと見づらいので,legend.text= オプションで凡例を指定する。
barplot(t(tbl), legend.text=dimnames(tbl)[[2]]) # 凡例を入れる
パーセンテージで表現する「帯グラフ」を描くには,分割表を比率にして積み上げ棒グラフを描けば良い。まずは prop.table(tbl, margin=1) によって行比率の分割表に変換し,それを上と同様に転置する t(prop.table(tbl, margin=1)) 。それを凡例付きで積み上げ棒グラフにする。
barplot(t(prop.table(tbl, margin=1)), legend.text=dimnames(tbl)[[2]]) # 帯グラフ(比率にして積み上げ)
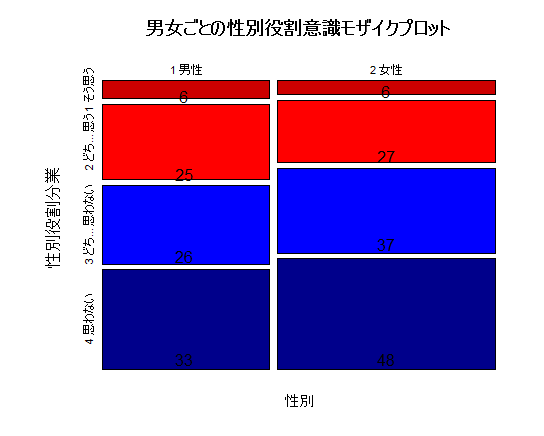
最後に,モザイクプロットを描く。
mosaicplot(tbl) # モザイクプロット
これでは余りに素っ気ないので,幾つかオプションを指定して装飾しよう。最後の二行の text( ) は度数を書き込んでいるものだが,中身はやや難しいので分からなくて良い。
mosaicplot(tbl,
main="男女ごとの性別役割意識モザイクプロット",
col=c("red3", "red", "blue", "blue4"))
text(sum(tbl[1,]*.5)/sum(tbl), 1-cumsum(tbl[1,])/sum(tbl[1,]), tbl[1,])
text(sum(tbl[1,]+tbl[2,]*.5)/sum(tbl), 1-cumsum(tbl[2,])/sum(tbl[2,]), tbl[2,])
main="男女ごとの性別役割意識モザイクプロット",
col=c("red3", "red", "blue", "blue4"))
text(sum(tbl[1,]*.5)/sum(tbl), 1-cumsum(tbl[1,])/sum(tbl[1,]), tbl[1,])
text(sum(tbl[1,]+tbl[2,]*.5)/sum(tbl), 1-cumsum(tbl[2,])/sum(tbl[2,]), tbl[2,])
2-3 名義尺度(nominal scale)の連関係数(association coefficient)
まず演習用に2行2列の分割表を用意しよう。後の式の見易さの為にオブジェクト名は一文字でxとしておく。行列を作成する matrix( ) 関数の書式をよく確認しておくと良い。

テクストの定義式に従ってユールのQを計算すると次のようになる。

ユールのQやφ係数の分子 ad-bc は行列式と呼ばれるもので,det( )で求められる。
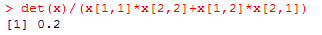
別の2×2分割表でQを計算したい時,行列 x の中身だけ変えれば,これらの計算式がそのまま利用出来る。
※ table( )関数で作成した分割表には det( ) は使えないので,その場合には table( ) から matrix( ) に変換する。

次はφ係数を計算してみよう。色々な計算の仕方が出来る。
 本文026頁に間違いを発見しました。〔訂正〕刊行後に見つかった誤りの訂正ページを御覧下さい。
本文026頁に間違いを発見しました。〔訂正〕刊行後に見つかった誤りの訂正ページを御覧下さい。

最後はオッズ比である。度数が0のセルが無ければ単純である。

0セルがあるかどうかは,すべてのセルの積を prod(x) で計算し,これが0になるかどうかで判断出来るので,prod(x)が0であれば0.5,正の値であれば0となる変数dを作成して,これをすべてのセルに加えてオッズ比を計算すれば良い。

上の結果をよく見比べて理解してほしい。こうすれば,特に手作業で場合分けして計算式を変えなくても,一つのスクリプトでオッズ比を計算出来る。
以下のようにすれば,判別条件を含んで一つのコマンドで書く事も出来るが,単に好みの問題であり,分からなくても支障ない。また,下のコンソール画面では一行の長さの長いコマンドは全て一行に表示する事ができずに$マークで省略された事が示されている。

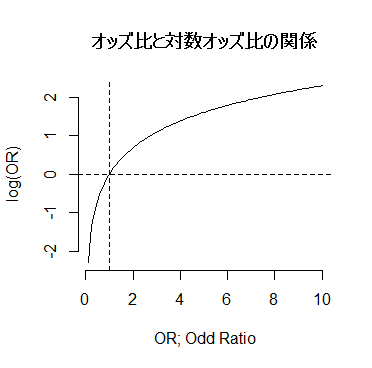
のちのロジスティック回帰分析などでは,オッズ比そのものではなく,オッズ比の自然対数である「対数オッズ比」が登場する事になる。オッズ比は正の実数で,1を境に非対称であるが,対数オッズ比は0を境に対称的に変化する。

0〜+∞の値を取りうるオッズ比と,-∞〜+∞の値を取りうる対数オッズ比の関係をグラフで確認してみよう。描画の都合上,x軸のオッズ比は0.1から10の範囲を指定する。オッズ比が0.1なら対数オッズ比は-2.302585,オッズ比が10なら対数オッズ比は2.302585である。
x <- matrix(c(10, 8, 5, 6), ncol=2, nrow=2)
x
x
テクストの定義式に従ってユールのQを計算すると次のようになる。
Q <- (x[1,1]*x[2,2]-x[1,2]*x[2,1])/(x[1,1]*x[2,2]+x[1,2]*x[2,1])
Q
Q
ユールのQやφ係数の分子 ad-bc は行列式と呼ばれるもので,det( )で求められる。
det(x)/(x[1,1]*x[2,2]+x[1,2]*x[2,1])
別の2×2分割表でQを計算したい時,行列 x の中身だけ変えれば,これらの計算式がそのまま利用出来る。
※ table( )関数で作成した分割表には det( ) は使えないので,その場合には table( ) から matrix( ) に変換する。
# data.frameから分割表を作成する
t01 <- table("sex"=data01$sex, "univ"=data01$edu1)
t01
# tableオブジェクトにはdet()関数は使えない
det(t01)
## クラスtableのオブジェクトをクラスmatrixに変換
x <- matrix(t01, ncol=2)
det(x)
t01 <- table("sex"=data01$sex, "univ"=data01$edu1)
t01
# tableオブジェクトにはdet()関数は使えない
det(t01)
## クラスtableのオブジェクトをクラスmatrixに変換
x <- matrix(t01, ncol=2)
det(x)
次はφ係数を計算してみよう。色々な計算の仕方が出来る。
本文026頁に間違いを発見しました。〔訂正〕刊行後に見つかった誤りの訂正ページを御覧下さい。
phi <- det(x)/sqrt(sum(x[1,])*sum(x[2,])*sum(x[,1])*sum(x[,2]))
phi
x2 <- addmargins(x); x2
det(x)/sqrt(x2[3,1]*x2[3,2]*x2[1,3]*x2[2,3])
phi
x2 <- addmargins(x); x2
det(x)/sqrt(x2[3,1]*x2[3,2]*x2[1,3]*x2[2,3])
最後はオッズ比である。度数が0のセルが無ければ単純である。
OR <- x[1,1]*x[2,2]/(x[1,2]*x[2,1])
OR
ただし,0セルがあると定義できないので,その場合にはすべてのセルに0.5を加えて計算する事になっている。以下の例を見てみよう。オッズ比 OR は無限大を表す Inf となっている。OR
0セルがあるかどうかは,すべてのセルの積を prod(x) で計算し,これが0になるかどうかで判断出来るので,prod(x)が0であれば0.5,正の値であれば0となる変数dを作成して,これをすべてのセルに加えてオッズ比を計算すれば良い。
x <- matrix(c(10, 8, 1, 6), ncol=2, nrow=2)
d <- 0; if (prod(x)==0) d <-0.5
OR <- (x[1,1]+d)*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
x; d; OR
x <- matrix(c(10, 8, 0, 6), ncol=2, nrow=2)
d <- 0; if (prod(x)==0) d <-0.5
OR <- (x[1,1]+d)*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
x; d; OR
d <- 0; if (prod(x)==0) d <-0.5
OR <- (x[1,1]+d)*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
x; d; OR
x <- matrix(c(10, 8, 0, 6), ncol=2, nrow=2)
d <- 0; if (prod(x)==0) d <-0.5
OR <- (x[1,1]+d)*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
x; d; OR
上の結果をよく見比べて理解してほしい。こうすれば,特に手作業で場合分けして計算式を変えなくても,一つのスクリプトでオッズ比を計算出来る。
以下のようにすれば,判別条件を含んで一つのコマンドで書く事も出来るが,単に好みの問題であり,分からなくても支障ない。また,下のコンソール画面では一行の長さの長いコマンドは全て一行に表示する事ができずに$マークで省略された事が示されている。
OR <- (x[1,1]+(d <- 0.5*(1 - ceiling(prod(x)/(prod(x)+.1)))))*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
OR
OR
のちのロジスティック回帰分析などでは,オッズ比そのものではなく,オッズ比の自然対数である「対数オッズ比」が登場する事になる。オッズ比は正の実数で,1を境に非対称であるが,対数オッズ比は0を境に対称的に変化する。
x <- matrix(c(6, 3, 8, 2), ncol=2, nrow=2)
OR <- (x[1,1]+(d <- 0.5*(1 - ceiling(prod(x)/(prod(x)+.1)))))*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
LogOR <- log(OR)
x; OR; LogOR
x <- matrix(c(8, 6, 2, 3), ncol=2, nrow=2)
OR <- (x[1,1]+(d <- 0.5*(1 - ceiling(prod(x)/(prod(x)+.1)))))*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
LogOR <- log(OR)
x; OR; LogOR
OR <- (x[1,1]+(d <- 0.5*(1 - ceiling(prod(x)/(prod(x)+.1)))))*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
LogOR <- log(OR)
x; OR; LogOR
x <- matrix(c(8, 6, 2, 3), ncol=2, nrow=2)
OR <- (x[1,1]+(d <- 0.5*(1 - ceiling(prod(x)/(prod(x)+.1)))))*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
LogOR <- log(OR)
x; OR; LogOR
0〜+∞の値を取りうるオッズ比と,-∞〜+∞の値を取りうる対数オッズ比の関係をグラフで確認してみよう。描画の都合上,x軸のオッズ比は0.1から10の範囲を指定する。オッズ比が0.1なら対数オッズ比は-2.302585,オッズ比が10なら対数オッズ比は2.302585である。
curve(log(x), from=0.1, to=10, bty="n",
main="オッズ比と対数オッズ比の関係",
xlab="OR; Odd Ratio", ylab="log(OR)")
abline(h=0, lty=2)
abline(v=1, lty=2)
main="オッズ比と対数オッズ比の関係",
xlab="OR; Odd Ratio", ylab="log(OR)")
abline(h=0, lty=2)
abline(v=1, lty=2)
2-4 独立性(independence)とカイ二乗統計量(chi-square statistic)
分割表について,カイ二乗統計量などを計算する方法を説明しよう。Rのカイ二乗検定の関数 chisq.test( ) を使えば簡単に求められるが,より手計算に近い方法も紹介しよう。

chisq.test( )関数を使用し,そこから情報を取り出す方法を以下で紹介する。カイ二乗検定の結果の要点(c0)が表示され,カイ二乗値が上で求めた値と(四捨五入の範囲内で)一致している事が確認出来る。検定の自由度は6,有意確率は.5249となっている。

names( )でc0に格納されている情報名の一覧が表示される。情報の取り出し方は以下を参考にして欲しい。また,上の手計算の結果と照合して欲しい。

クラメール(クラマー)のVの計算には,カイ二乗統計量を利用する。

# 分割表を準備
x <- matrix(c(6, 3, 3, 17, 15, 19, 26, 21, 15, 25, 22, 31), nrow=3)
# 周辺度数を付加
addx <- addmargins(x); addx
# 期待度数の表を,ヴェクトル同士の積 %*% を使用して作成する。
f <- addx[1:3, 5] %*% t(addx[4, 1:4])/sum(x)
f
# 残差の表
x-f
# 標準化残差(ピアソン残差)の表
stdres <- (x-f)/sqrt(f); stdres
# 標準化残差の二乗和,即ちカイ二乗統計量
sum(stdres^2)
x <- matrix(c(6, 3, 3, 17, 15, 19, 26, 21, 15, 25, 22, 31), nrow=3)
# 周辺度数を付加
addx <- addmargins(x); addx
# 期待度数の表を,ヴェクトル同士の積 %*% を使用して作成する。
f <- addx[1:3, 5] %*% t(addx[4, 1:4])/sum(x)
f
# 残差の表
x-f
# 標準化残差(ピアソン残差)の表
stdres <- (x-f)/sqrt(f); stdres
# 標準化残差の二乗和,即ちカイ二乗統計量
sum(stdres^2)
chisq.test( )関数を使用し,そこから情報を取り出す方法を以下で紹介する。カイ二乗検定の結果の要点(c0)が表示され,カイ二乗値が上で求めた値と(四捨五入の範囲内で)一致している事が確認出来る。検定の自由度は6,有意確率は.5249となっている。
# カイ二乗検定の関数
c0 <- chisq.test(x); c0
names(c0)
c0 <- chisq.test(x); c0
names(c0)
names( )でc0に格納されている情報名の一覧が表示される。情報の取り出し方は以下を参考にして欲しい。また,上の手計算の結果と照合して欲しい。
c0$statistic # カイ二乗統計量
c0$observed # 観測度数の表
c0$expected # 期待度数の表
c0$residuals # 標準化残差の表(ただの残差ではない!)
c0$stdres # 調整済み標準化残差(Haberman残差)の表
sum(c0$residuals^2) # 標準化残差の二乗和=カイ二乗値
c0$observed # 観測度数の表
c0$expected # 期待度数の表
c0$residuals # 標準化残差の表(ただの残差ではない!)
c0$stdres # 調整済み標準化残差(Haberman残差)の表
sum(c0$residuals^2) # 標準化残差の二乗和=カイ二乗値
クラメール(クラマー)のVの計算には,カイ二乗統計量を利用する。
V <- sqrt(c0$statistic/(min(dim(x)-1)*sum(x)))
names(V) <- "Cramer's V" # 出力のラベル表示を修正するだけなので省略可
V
names(V) <- "Cramer's V" # 出力のラベル表示を修正するだけなので省略可
V
2-5 順序尺度(ordinal scale)の連関係数(rank correlation coefficient)
任意の分割表から,本文にあるペアのタイプのA,B,C,D,Eの数を全て数え上げ,それを元にグッドマンとクラスカルのγや,ケンドールのτ3種類を計算するスクリプトを,前半と後半に分けて紹介する。

これらからつぎに,4種類の順序連関係数を計算する。
# 分割表を準備
x0 <- matrix(c(6, 3, 3, 17, 15, 19, 26, 21, 15, 25, 22, 31), nrow=3)
## rank Correlation
table01 <- x0 # 元になる分割表を x0 とし,table01にコピーして以下で使用。
n.col <- ncol(x0) # x0の列数
n.row <- nrow(x0) # x0の行数
sum01 <- sum(table01) # 全度数
sum.pair <- sum01*(sum01-1)/2 # ペアの総数
# それぞれのタイプのペアの数の初期値を全て0として定義しておく。
con.pair <- dis.pair <- r.tie <- c.tie <- all.tie <- 0
# 各タイプのペアの数を数え上げる
for (i in 1:n.row) {
for (i2 in 1:n.row) {
for (j in 1:n.col) {
for (j2 in 1:n.col) {
if (i>i2 & j>j2) con.pair <- con.pair+table01[i,j]*table01[i2,j2]
if (i>i2 & j<j2) dis.pair <- dis.pair+table01[i,j]*table01[i2,j2]
if (i==i2 & j>j2) r.tie <- r.tie+table01[i,j]*table01[i2,j2]
if (i>i2 & j==j2) c.tie <- c.tie+table01[i,j]*table01[i2,j2]
if (i==i2 & j==j2) all.tie <- all.tie+table01[i,j]*(table01[i2,j2]-1)/2
}}}}
# それぞれのペアの数を表示
con.pair; dis.pair; r.tie; c.tie; all.tie
# ペアの総数を確認
all.tie+r.tie+c.tie+con.pair+dis.pair
sum.pair
これらからつぎに,4種類の順序連関係数を計算する。
## Goodman and Kruskal's Gamma
gamma <- (con.pair-dis.pair)/(con.pair+dis.pair)
## Kendall's tau-a
taua <- (con.pair-dis.pair)/sum.pair
## Kendall's tau-b
taub <- (con.pair-dis.pair)/sqrt((con.pair+dis.pair+r.tie)*(con.pair+dis.pair+c.tie))
## Kendall's tau-c
tauc <- (con.pair-dis.pair)*2*min(dim(table01))/(sum01^2*(min(dim(table01))-1))
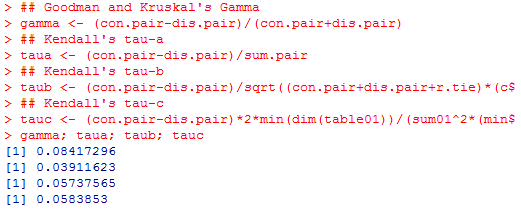
gamma; taua; taub; tauc
gamma <- (con.pair-dis.pair)/(con.pair+dis.pair)
## Kendall's tau-a
taua <- (con.pair-dis.pair)/sum.pair
## Kendall's tau-b
taub <- (con.pair-dis.pair)/sqrt((con.pair+dis.pair+r.tie)*(con.pair+dis.pair+c.tie))
## Kendall's tau-c
tauc <- (con.pair-dis.pair)*2*min(dim(table01))/(sum01^2*(min(dim(table01))-1))
gamma; taua; taub; tauc
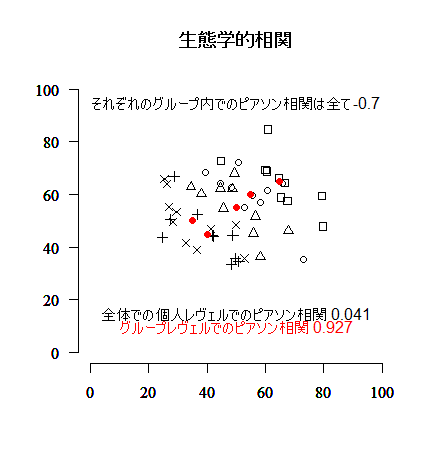
発展1-1 生態学的誤謬(ecological fallacy)
少し難しいが,生態学的誤謬を視覚的に確認するスクリプトを作ってみたので,#### ここまでで一旦実行してグラフを確認 ####の指示に従って,スクリプトを部分的に実行しながらグラフを確認して行って欲しい。最後に出来上がったグラフも示す。
rxy <- -0.7 # グループ内での個人レヴェルでの相関
x0 <- rnorm(50, mean=0, sd=1); y0 <- rnorm(50, mean=0, sd=1) # 10人×5グループ分のタネ
## 第1グループ
z1 <- rxy*(x1 <- scale(x0[1:10])) + sqrt(1-rxy^2)*scale(lm(y0[1:10] ~ x0[1:10])$residuals)
x11 <- x1*10+65; z11 <- z1*10+65
## 第2グループ
z1 <- rxy*(x1 <- scale(x0[11:20])) + sqrt(1-rxy^2)*scale(lm(y0[11:20] ~ x0[11:20])$residuals)
x12 <- x1*10+55; z12 <- z1*10+60
## 第3グループ
z1 <- rxy*(x1 <- scale(x0[21:30])) + sqrt(1-rxy^2)*scale(lm(y0[21:30] ~ x0[21:30])$residuals)
x13 <- x1*10+50; z13 <- z1*10+55
## 第4グループ
z1 <- rxy*(x1 <- scale(x0[31:40])) + sqrt(1-rxy^2)*scale(lm(y0[31:40] ~ x0[31:40])$residuals)
x14 <- x1*10+40; z14 <- z1*10+45
## 第5グループ
z1 <- rxy*(x1 <- scale(x0[41:50])) + sqrt(1-rxy^2)*scale(lm(y0[41:50] ~ x0[41:50])$residuals)
x15 <- x1*10+35; z15 <- z1*10+50
# 5つのグループごとのプロット
plot(x11,z11, xlim=c(0,100), ylim=c(0,100), bty="n", pch=0,
main="生態学的相関", xlab="", ylab="", family="serif", las=1)
text(50, 95, "それぞれのグループ内でのピアソン相関は全て-0.7")
#### ここまでで一旦実行してグラフを確認 ####
par(new=T); plot(x12,z12, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=1)
#### ここまでで一旦実行してグラフを確認 ####
par(new=T); plot(x13,z13, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=2)
#### ここまでで一旦実行してグラフを確認 ####
par(new=T); plot(x14,z14, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=3)
#### ここまでで一旦実行してグラフを確認 ####
par(new=T); plot(x15,z15, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=4)
#### ここまでで一旦実行してグラフを確認 ####
# 全体での個人レヴェルでの相関係数
x_ind <- c(x11, x12, x13, x14, x15)
z_ind <- c(z11, z12, z13, z14, z15)
text(50, 15, paste("全体での個人レヴェルでのピアソン相関", round(cor(x_ind, z_ind), 3))) # 個人レヴェルでの相関
#### ここまでで一旦実行してグラフを確認 ####
# グループ平均のプロット
x_agg <- c(mean(x11), mean(x12), mean(x13), mean(x14), mean(x15))
z_agg <- c(mean(z11), mean(z12), mean(z13), mean(z14), mean(z15))
par(new=T);
plot(x_agg, z_agg, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=19, col="red")
text(50, 10, # アグリゲイトレヴェルでの相関
paste("グループレヴェルでのピアソン相関", round(cor(x_agg, z_agg), 3)), col="red")
x0 <- rnorm(50, mean=0, sd=1); y0 <- rnorm(50, mean=0, sd=1) # 10人×5グループ分のタネ
## 第1グループ
z1 <- rxy*(x1 <- scale(x0[1:10])) + sqrt(1-rxy^2)*scale(lm(y0[1:10] ~ x0[1:10])$residuals)
x11 <- x1*10+65; z11 <- z1*10+65
## 第2グループ
z1 <- rxy*(x1 <- scale(x0[11:20])) + sqrt(1-rxy^2)*scale(lm(y0[11:20] ~ x0[11:20])$residuals)
x12 <- x1*10+55; z12 <- z1*10+60
## 第3グループ
z1 <- rxy*(x1 <- scale(x0[21:30])) + sqrt(1-rxy^2)*scale(lm(y0[21:30] ~ x0[21:30])$residuals)
x13 <- x1*10+50; z13 <- z1*10+55
## 第4グループ
z1 <- rxy*(x1 <- scale(x0[31:40])) + sqrt(1-rxy^2)*scale(lm(y0[31:40] ~ x0[31:40])$residuals)
x14 <- x1*10+40; z14 <- z1*10+45
## 第5グループ
z1 <- rxy*(x1 <- scale(x0[41:50])) + sqrt(1-rxy^2)*scale(lm(y0[41:50] ~ x0[41:50])$residuals)
x15 <- x1*10+35; z15 <- z1*10+50
# 5つのグループごとのプロット
plot(x11,z11, xlim=c(0,100), ylim=c(0,100), bty="n", pch=0,
main="生態学的相関", xlab="", ylab="", family="serif", las=1)
text(50, 95, "それぞれのグループ内でのピアソン相関は全て-0.7")
#### ここまでで一旦実行してグラフを確認 ####
par(new=T); plot(x12,z12, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=1)
#### ここまでで一旦実行してグラフを確認 ####
par(new=T); plot(x13,z13, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=2)
#### ここまでで一旦実行してグラフを確認 ####
par(new=T); plot(x14,z14, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=3)
#### ここまでで一旦実行してグラフを確認 ####
par(new=T); plot(x15,z15, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=4)
#### ここまでで一旦実行してグラフを確認 ####
# 全体での個人レヴェルでの相関係数
x_ind <- c(x11, x12, x13, x14, x15)
z_ind <- c(z11, z12, z13, z14, z15)
text(50, 15, paste("全体での個人レヴェルでのピアソン相関", round(cor(x_ind, z_ind), 3))) # 個人レヴェルでの相関
#### ここまでで一旦実行してグラフを確認 ####
# グループ平均のプロット
x_agg <- c(mean(x11), mean(x12), mean(x13), mean(x14), mean(x15))
z_agg <- c(mean(z11), mean(z12), mean(z13), mean(z14), mean(z15))
par(new=T);
plot(x_agg, z_agg, xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=19, col="red")
text(50, 10, # アグリゲイトレヴェルでの相関
paste("グループレヴェルでのピアソン相関", round(cor(x_agg, z_agg), 3)), col="red")
発展1-2 シンプソンのパラドクス(Simpson's paradox)
本文の例について,それぞれクラメールのVを計算して示す。

A <- matrix(c(550, 450, 80, 20), ncol=2) # A大学
B <- matrix(c( 50, 150,120,180), ncol=2) # B大学
VA <- sqrt(chisq.test(A)$statistic/(min(dim(A)-1)*sum(A)))
VB <- sqrt(chisq.test(B)$statistic/(min(dim(B)-1)*sum(B)))
Z <- A + B # A大学とB大学のデータの合併
VZ <- sqrt(chisq.test(Z)$statistic/(min(dim(Z)-1)*sum(Z)))
names(VA) <- names(VB) <- names(VZ) <- "Cramer's V"
A; VA
B; VB
Z; VZ
B <- matrix(c( 50, 150,120,180), ncol=2) # B大学
VA <- sqrt(chisq.test(A)$statistic/(min(dim(A)-1)*sum(A)))
VB <- sqrt(chisq.test(B)$statistic/(min(dim(B)-1)*sum(B)))
Z <- A + B # A大学とB大学のデータの合併
VZ <- sqrt(chisq.test(Z)$statistic/(min(dim(Z)-1)*sum(Z)))
names(VA) <- names(VB) <- names(VZ) <- "Cramer's V"
A; VA
B; VB
Z; VZ
発展1-3 スピアマンの順位相関係数(Spearman's rank-order coefficient)
2変数のうち一方でも,尺度水準が間隔尺度とは言えず順序尺度でしかない場合には,ピアソンの積率相関係数を計算する事が出来ず,ケンドールのτの様な順序連関係数やスピアマンの順位相関係数を計算するしかない。取り得る値の種類が少ないか同順位(tie)が多い場合には順序連関係数を用いれば良いと考えられるので,順位相関係数は,取り得る値の種類は多くて同順位になる事は少ないが,しかし間隔尺度とは見做せない場合に適用される事になる。社会調査データでは余りこうした変数は多くは無いだろう。よって以下では,間隔尺度以上の変数に対して,順位相関係数を用いる事の意義に注目する。
本文のように,外れ値が無い場合と有る場合とで,積率相関と順位相関がどのように変わるかをシミュレイションするスクリプトを挙げておく。実行するたびに形が変わる。
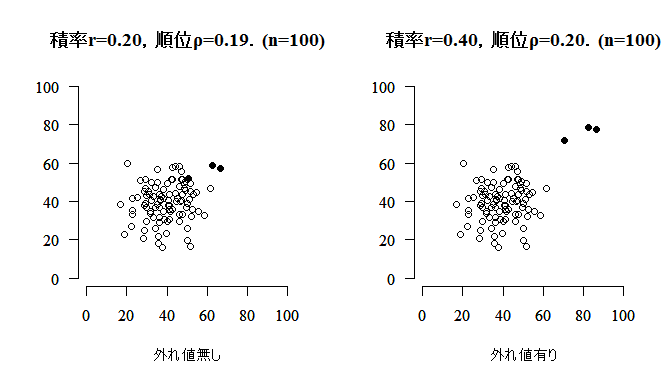
本文のように,外れ値が無い場合と有る場合とで,積率相関と順位相関がどのように変わるかをシミュレイションするスクリプトを挙げておく。実行するたびに形が変わる。
x0 <- rnorm(n=100, mean=0, sd=1)
y0 <- rnorm(n=100, mean=0, sd=1)
r0 <- lm(y0 ~ x0)$residuals
z1 <- (rxy <- 0.2)*scale(x0) + sqrt(1-rxy^2)*scale(r0)
x3 <- x2 <- x1*10+40
z3 <- z2 <- z1*10+40
xc <- 50; zc <- 50
x3[x2 > xc & z2 > zc] <- x2[x2 > xc & z2 > zc] + 20
z3[x2 > xc & z2 > zc] <- z2[x2 > xc & z2 > zc] + 20
windows(7, 4) # 描画ウィンドウのサイズ
par(mfrow=c(1,2)) # 描画ウィンドウを1行2列に分割
plot(x2[x2 <= xc | z2 <= zc],z2[x2 <= xc | z2 <= zc],
xlim=c(0,100), ylim=c(0,100), bty="n",
main=sprintf("積率r=%.2f,順位ρ=%.2f.(n=%d)",
cor(x2, z2), cor(x2, z2, method="spearman"), length(x2)),
xlab="外れ値無し", ylab="", family="serif", las=1)
par(new=T)
plot(x2[x2 > xc & z2 > zc],z2[x2 > xc & z2 > zc],
xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=16)
plot(x3[x2 <= xc | z2 <= zc],z3[x2 <= xc | z2 <= zc],
xlim=c(0,100), ylim=c(0,100), bty="n",
main=sprintf("積率r=%.2f,順位ρ=%.2f.(n=%d)",
cor(x3, z3), cor(x3, z3, method="spearman"), length(x2)),
xlab="外れ値有り", ylab="", family="serif", las=1)
par(new=T)
plot(x3[x2 > xc & z2 > zc],z3[x2 > xc & z2 > zc],
xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=16)
y0 <- rnorm(n=100, mean=0, sd=1)
r0 <- lm(y0 ~ x0)$residuals
z1 <- (rxy <- 0.2)*scale(x0) + sqrt(1-rxy^2)*scale(r0)
x3 <- x2 <- x1*10+40
z3 <- z2 <- z1*10+40
xc <- 50; zc <- 50
x3[x2 > xc & z2 > zc] <- x2[x2 > xc & z2 > zc] + 20
z3[x2 > xc & z2 > zc] <- z2[x2 > xc & z2 > zc] + 20
windows(7, 4) # 描画ウィンドウのサイズ
par(mfrow=c(1,2)) # 描画ウィンドウを1行2列に分割
plot(x2[x2 <= xc | z2 <= zc],z2[x2 <= xc | z2 <= zc],
xlim=c(0,100), ylim=c(0,100), bty="n",
main=sprintf("積率r=%.2f,順位ρ=%.2f.(n=%d)",
cor(x2, z2), cor(x2, z2, method="spearman"), length(x2)),
xlab="外れ値無し", ylab="", family="serif", las=1)
par(new=T)
plot(x2[x2 > xc & z2 > zc],z2[x2 > xc & z2 > zc],
xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=16)
plot(x3[x2 <= xc | z2 <= zc],z3[x2 <= xc | z2 <= zc],
xlim=c(0,100), ylim=c(0,100), bty="n",
main=sprintf("積率r=%.2f,順位ρ=%.2f.(n=%d)",
cor(x3, z3), cor(x3, z3, method="spearman"), length(x2)),
xlab="外れ値有り", ylab="", family="serif", las=1)
par(new=T)
plot(x3[x2 > xc & z2 > zc],z3[x2 > xc & z2 > zc],
xlim=c(0,100), ylim=c(0,100), bty="n",
main="", xlab="", ylab="", family="serif", las=1, pch=16)
第2章【練習問題】の解答
1)の答え:
因みに,本人年収incomeを世帯年収fincomeに置き換えると,ピアソン相関は約0.30に上がる。自分で試してみよう。
2)の答え: 結果は自分で確認してみよう。
3)の答え:

4)の答え:
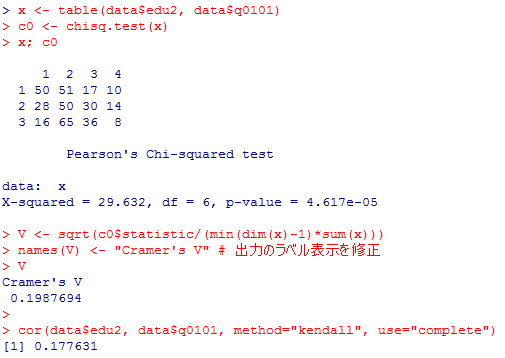
5)の答え:


# データフレイムの準備の復習
getwd() # Working Directoryを確認して,そこにデータのcsvファイルを置く
data <- read.csv("practice.csv") # csvファイルをデータフレイムとして読み込む
# 散布図――散布図のスクリプトは一つずつ実行して比較しよう
plot(data$income, data$q1700)
# 幾つかオプションを付ける
plot(data$income, data$q1700,
bty="n", main="本人年収と幸福度")
# 更にオプションを付ける
plot(data$income, data$q1700,
bty="n", main="本人年収と幸福度",
xlab="本人年収income(万円)",
ylab="幸福度(低0← →10高)")
# 相関係数の値と回帰直線を書き込む
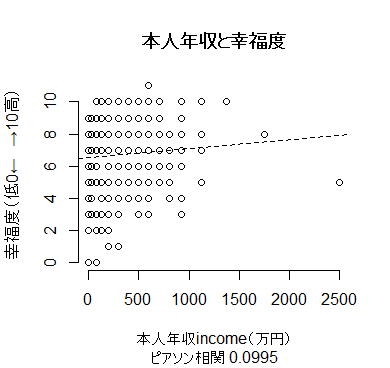
r <- cor(data$income, data$q1700, use="complete")
plot(data$income, data$q1700,
bty="n", main="本人年収と幸福度",
xlab="本人年収income(万円)",
ylab="幸福度(低0← →10高)",
sub=paste("ピアソン相関", round(r, 4)))
abline(lm(data$q1700 ~ data$income), lty=2)
最後の散布図は以下となる。getwd() # Working Directoryを確認して,そこにデータのcsvファイルを置く
data <- read.csv("practice.csv") # csvファイルをデータフレイムとして読み込む
# 散布図――散布図のスクリプトは一つずつ実行して比較しよう
plot(data$income, data$q1700)
# 幾つかオプションを付ける
plot(data$income, data$q1700,
bty="n", main="本人年収と幸福度")
# 更にオプションを付ける
plot(data$income, data$q1700,
bty="n", main="本人年収と幸福度",
xlab="本人年収income(万円)",
ylab="幸福度(低0← →10高)")
# 相関係数の値と回帰直線を書き込む
r <- cor(data$income, data$q1700, use="complete")
plot(data$income, data$q1700,
bty="n", main="本人年収と幸福度",
xlab="本人年収income(万円)",
ylab="幸福度(低0← →10高)",
sub=paste("ピアソン相関", round(r, 4)))
abline(lm(data$q1700 ~ data$income), lty=2)
因みに,本人年収incomeを世帯年収fincomeに置き換えると,ピアソン相関は約0.30に上がる。自分で試してみよう。
2)の答え: 結果は自分で確認してみよう。
# 最も単純な分割表
t01 <- table(data$sex, data$edu1)
t01
# 分割表にラベルを付ける
names(dimnames(t01)) <- c("性別", "大卒/非大卒")
dimnames(t01)[[1]] <- c("男性", "女性")
dimnames(t01)[[2]] <- c("非大卒", "大卒")
t01
# 周辺度数付きの分割表
t02 <- addmargins(t01)
t02
# 行%の表
prop.table(t01, margin=1)
# 列%の表
prop.table(t01, margin=2)
### ユールのQ
# 上で作成したスクリプトを再利用する為に,xにt01を行列にして代入
x <- matrix(t01, ncol=2)
Q <- det(x)/(x[1,1]*x[2,2]+x[1,2]*x[2,1]); Q
# 分割表を行列化しない場合は,下記のスクリプトを使用
x <- t01
Q <- (x[1,1]*x[2,2]-x[1,2]*x[2,1])/(x[1,1]*x[2,2]+x[1,2]*x[2,1])
Q
### φ係数
x <- matrix(t01, ncol=2)
phi <- det(x)/sqrt(sum(x[1,])*sum(x[2,])*sum(x[,1])*sum(x[,2]))
phi
# 行列化しない方法
x <- t01
phi <- (x[1,1]*x[2,2]-x[1,2]*x[2,1])/sqrt(sum(x[1,])*sum(x[2,])*sum(x[,1])*sum(x[,2]))
phi
### オッズ比
x <- t01
OR <- (x[1,1]+(d <- 0.5*(1 - ceiling(prod(x)/(prod(x)+.1)))))*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
OR
t01 <- table(data$sex, data$edu1)
t01
# 分割表にラベルを付ける
names(dimnames(t01)) <- c("性別", "大卒/非大卒")
dimnames(t01)[[1]] <- c("男性", "女性")
dimnames(t01)[[2]] <- c("非大卒", "大卒")
t01
# 周辺度数付きの分割表
t02 <- addmargins(t01)
t02
# 行%の表
prop.table(t01, margin=1)
# 列%の表
prop.table(t01, margin=2)
### ユールのQ
# 上で作成したスクリプトを再利用する為に,xにt01を行列にして代入
x <- matrix(t01, ncol=2)
Q <- det(x)/(x[1,1]*x[2,2]+x[1,2]*x[2,1]); Q
# 分割表を行列化しない場合は,下記のスクリプトを使用
x <- t01
Q <- (x[1,1]*x[2,2]-x[1,2]*x[2,1])/(x[1,1]*x[2,2]+x[1,2]*x[2,1])
Q
### φ係数
x <- matrix(t01, ncol=2)
phi <- det(x)/sqrt(sum(x[1,])*sum(x[2,])*sum(x[,1])*sum(x[,2]))
phi
# 行列化しない方法
x <- t01
phi <- (x[1,1]*x[2,2]-x[1,2]*x[2,1])/sqrt(sum(x[1,])*sum(x[2,])*sum(x[,1])*sum(x[,2]))
phi
### オッズ比
x <- t01
OR <- (x[1,1]+(d <- 0.5*(1 - ceiling(prod(x)/(prod(x)+.1)))))*(x[2,2]+d)/((x[1,2]+d)*(x[2,1]+d))
OR
3)の答え:
table(data$sex, data$edu2)
table(data$sex, data$edu2, useNA="ifany")
table(data$sex, data$edu2, useNA="always")
# 分割表にラベルを付けるには下記のように。
t10 <- table(data$sex, data$edu2, useNA="always")
names(dimnames(t10)) <- c("性別", "学歴")
dimnames(t10)[[1]] <- c("男性", "女性", "NA")
dimnames(t10)[[2]] <- c("初等学歴", "中等学歴", "高等学歴", "NA")
t10
table(data$sex, data$edu2, useNA="ifany")
table(data$sex, data$edu2, useNA="always")
# 分割表にラベルを付けるには下記のように。
t10 <- table(data$sex, data$edu2, useNA="always")
names(dimnames(t10)) <- c("性別", "学歴")
dimnames(t10)[[1]] <- c("男性", "女性", "NA")
dimnames(t10)[[2]] <- c("初等学歴", "中等学歴", "高等学歴", "NA")
t10
4)の答え:
x <- table(data$edu2, data$q0101)
c0 <- chisq.test(x)
x; c0
V <- sqrt(c0$statistic/(min(dim(x)-1)*sum(x)))
names(V) <- "Cramer's V" # 出力のラベル表示を修正
V
cor(data$edu2, data$q0101, method="kendall", use="complete")
c0 <- chisq.test(x)
x; c0
V <- sqrt(c0$statistic/(min(dim(x)-1)*sum(x)))
names(V) <- "Cramer's V" # 出力のラベル表示を修正
V
cor(data$edu2, data$q0101, method="kendall", use="complete")
5)の答え:
t21 <- table(data$edu2, data$job)
t22 <- table(data$edu2, data$job, data$sex)
# これでは見にくいので,ラベルを付ける。
names(dimnames(t21)) <- c("学歴3区分", "従業上の地位")
names(dimnames(t22)) <- c("学歴3区分", "従業上の地位", "性別")
dimnames(t21)[[1]] <- dimnames(t22)[[1]] <- c("1 初等", "2 中等", "3 高等")
dimnames(t21)[[2]] <- dimnames(t22)[[2]] <- c("1 常雇", "2 臨時", "3 自営", "4 無職")
dimnames(t22)[[3]] <- c("1 男性", "2 女性")
t21
t22
# 3元分割表の「第1層」と「第2層」を足せば2元分割表に一致する。
t22[,,1] + t22[,,2]
t22 <- table(data$edu2, data$job, data$sex)
# これでは見にくいので,ラベルを付ける。
names(dimnames(t21)) <- c("学歴3区分", "従業上の地位")
names(dimnames(t22)) <- c("学歴3区分", "従業上の地位", "性別")
dimnames(t21)[[1]] <- dimnames(t22)[[1]] <- c("1 初等", "2 中等", "3 高等")
dimnames(t21)[[2]] <- dimnames(t22)[[2]] <- c("1 常雇", "2 臨時", "3 自営", "4 無職")
dimnames(t22)[[3]] <- c("1 男性", "2 女性")
t21
t22
# 3元分割表の「第1層」と「第2層」を足せば2元分割表に一致する。
t22[,,1] + t22[,,2]
# 3元(3次元)分割表,3重クロス表の変数を入れ替える。
# 変数は順に,行変数,列変数,層変数となっている。
# 行変数と列変数の入れ替えは余り重要ではない。
# 以下の結果をよく見比べて解読しよう。
table(data$edu2, data$job, data$sex)
table(data$sex, data$job, data$edu2)
table(data$sex, data$edu2, data$job)
結果は最初の二つだけ以下に表示する。# 変数は順に,行変数,列変数,層変数となっている。
# 行変数と列変数の入れ替えは余り重要ではない。
# 以下の結果をよく見比べて解読しよう。
table(data$edu2, data$job, data$sex)
table(data$sex, data$job, data$edu2)
table(data$sex, data$edu2, data$job)
Copyright (C) 2016-2017 SUGINO Isamu All Rights Reserved. design by tempnate