杉野 勇 (SUGINO Isamu) お茶の水女子大学・人間発達科学専攻・応用社会学コース担当
『入門・社会統計学』サポートウェブ |
|
 第3章 推測統計の基礎(Basics of Inferential Statistics)
第3章 推測統計の基礎(Basics of Inferential Statistics)
1-1 無作為抽出(random sampling)と可能な標本の数
N個からn個を選び出す「場合の数」の公式は次の通りである。
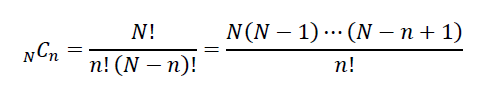
N=10, n=2とすると次のように計算できる。
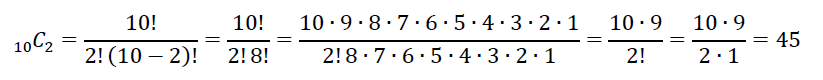
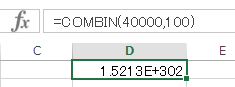
N=40000, n=100の場合は次のようになる。
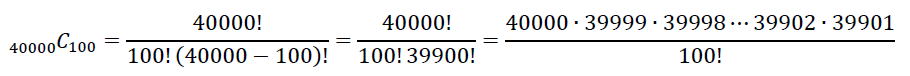
これは手計算は無理なので,Rの関数の choose(N, n) を利用する。
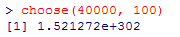
これは,「1.521272×10の302乗」と読む。e+302は10の302乗である。
MS-Excelでは,combin(N, n) という関数を利用する。
しかしこれらの関数は,Nやnがもう少し大きくなると,RやExcelで計算不能になる。Rでの計算結果を以下に示すので理解してほしい。

"Inf"というのは「無限大」という意味であるが,本当に無限大なのではなく,「簡単には計算できないくらい大きな数」という意味である。
これを計算するには,「対数変換」を利用する方法がある。場合の数(組合せの数)を以下のように k と置く。
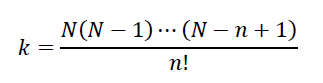
この両辺の常用対数を取り,「積の対数は対数の和に,商(割り算)の対数は対数の差に」変形できることを利用すると,次のように変形できる。
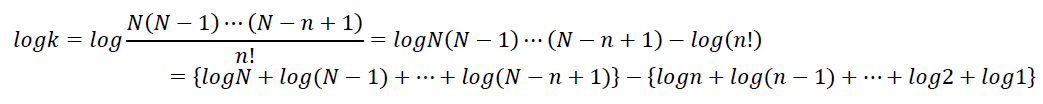
対数の和や差であればなんとかRで計算できるので,log(k)を計算してから,10のlogk乗を計算して,kを求めることができる(この計算でも多少近似的かも知れないが,おおよその大きさを把握することはできるだろう)。

これが何をしているかがわからない場合は,c((N-n+1):N) だけを実行してみる,次に log10(c((N-n+1):N)) を実行してみる,そして sum(log10(c((N-n+1):N))) を実行してみる,nume-denom を計算した後で,floor(nume-denom) を計算してみる,のように部分的・段階的に実行していくと分かる場合が多い。
Nやnを書き換えるだけで,このスクリプトを利用することができる。



N=10, n=2とすると次のように計算できる。
N=40000, n=100の場合は次のようになる。
これは手計算は無理なので,Rの関数の choose(N, n) を利用する。
これは,「1.521272×10の302乗」と読む。e+302は10の302乗である。
MS-Excelでは,combin(N, n) という関数を利用する。
しかしこれらの関数は,Nやnがもう少し大きくなると,RやExcelで計算不能になる。Rでの計算結果を以下に示すので理解してほしい。
"Inf"というのは「無限大」という意味であるが,本当に無限大なのではなく,「簡単には計算できないくらい大きな数」という意味である。
これを計算するには,「対数変換」を利用する方法がある。場合の数(組合せの数)を以下のように k と置く。
この両辺の常用対数を取り,「積の対数は対数の和に,商(割り算)の対数は対数の差に」変形できることを利用すると,次のように変形できる。
対数の和や差であればなんとかRで計算できるので,log(k)を計算してから,10のlogk乗を計算して,kを求めることができる(この計算でも多少近似的かも知れないが,おおよその大きさを把握することはできるだろう)。
N <- 100000000 # 母集団サイズを任意に指定
n <- 1000 # 標本サイズを任意に指定
# N-n+1からNまでのヴェクトルの常用対数の総和
nume <- sum(log10(c((N-n+1):N)))
# 1からnまでのヴェクトルの常用対数の総和
denom <- sum(log10(c(1:n)))
# nume-denomの整数部分を取り出す
b <- floor(nume-denom)
# nume-denomの小数部分だけを10の「べき指数」として計算する
a <- 10^(nume-denom-b)
# 結果を表示する
sprintf("%.5f×10の%d乗", a, b)
n <- 1000 # 標本サイズを任意に指定
# N-n+1からNまでのヴェクトルの常用対数の総和
nume <- sum(log10(c((N-n+1):N)))
# 1からnまでのヴェクトルの常用対数の総和
denom <- sum(log10(c(1:n)))
# nume-denomの整数部分を取り出す
b <- floor(nume-denom)
# nume-denomの小数部分だけを10の「べき指数」として計算する
a <- 10^(nume-denom-b)
# 結果を表示する
sprintf("%.5f×10の%d乗", a, b)
これが何をしているかがわからない場合は,c((N-n+1):N) だけを実行してみる,次に log10(c((N-n+1):N)) を実行してみる,そして sum(log10(c((N-n+1):N))) を実行してみる,nume-denom を計算した後で,floor(nume-denom) を計算してみる,のように部分的・段階的に実行していくと分かる場合が多い。
Nやnを書き換えるだけで,このスクリプトを利用することができる。
1-2 標本統計量の標本抽出分布(sampling distribution)
まず,上のスクリプトを使うと,4,894人から50人を選ぶ場合の数(可能な標本の数)は "7.78123×10の119乗"となる。
4,894人分の模擬年収データをcsvファイルで提供するので,右クリックでファイルを保存し,getwd() で表示されるディレクトリ(フォルダ)にコピーして使用する。wdとはworking directory,「作業場所」の事である。(working directoryを変更したい場合には,setwd("C:/Users/yourname/Documents/R") のように変更先を指定する。)
(実際の調査データに多少の加工を施して作成している。)
ファイルをworking directoryにコピーしたら,次のスクリプトで data01 として読み込もう。ついでに関数names( ),head( ),tail( )を例示する。

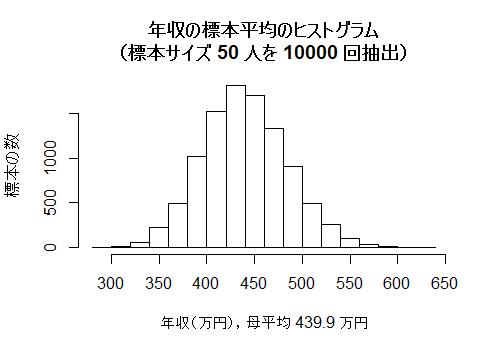
以下のスクリプトを使うと,本文のヒストグラムに類似したグラフが描ける。実行するたびにグラフは少し変化する。
テキストの,標準正規分布の95%区間のグラフを描くスクリプトを(少し簡素化して)示しておくので,pの値を.90や.99などに書き換えて実行してみよう。コマンドを一つずつ実行していくと,それぞれが何をするコマンドなのかが分かり易くなる。
4,894人分の模擬年収データをcsvファイルで提供するので,右クリックでファイルを保存し,getwd() で表示されるディレクトリ(フォルダ)にコピーして使用する。wdとはworking directory,「作業場所」の事である。(working directoryを変更したい場合には,setwd("C:/Users/yourname/Documents/R") のように変更先を指定する。)
(実際の調査データに多少の加工を施して作成している。)
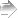
ファイルをworking directoryにコピーしたら,次のスクリプトで data01 として読み込もう。ついでに関数names( ),head( ),tail( )を例示する。
data01 <- read.csv("mock_income.csv") #csvファイルをデータフレイムに読み込む
names(data01) # data01に含まれる変数名を表示
head(data01) # 最初の6ケースを表示する
tail(data01) # 最後の6ケースを表示する
この収入データ(data01$income)から,無作為に50個の数字を抽出してその平均や標準偏差を計算してみよう。names(data01) # data01に含まれる変数名を表示
head(data01) # 最初の6ケースを表示する
tail(data01) # 最後の6ケースを表示する
sample02 <- sample(data01$income, size=50)
mean(sample02)
sd(sample02)
無作為抽出なので,実行するたびに結果が変わる。この3行だけを何度か繰り返し実行してみると良い。mean(sample02)
sd(sample02)
以下のスクリプトを使うと,本文のヒストグラムに類似したグラフが描ける。実行するたびにグラフは少し変化する。
times <- 10000 # 抽出回数の指定
n <- 50 # サンプルサイズの指定
sample_mean <- vector(length=times) # times個得られるはずの標本平均の入れ物ヴェクトルを用意
for (i in 1:times) { # times回だけ以下の操作を繰り返す
temp_sample <- sample(data01$income, n) # サイズnの標本を抽出する
sample_mean[i] <- mean(temp_sample) # 抽出した標本の平均を計算する
}
hist(sample_mean, freq=TRUE, ylab="標本の数",
main=paste("年収の標本平均のヒストグラム\n(標本サイズ", n, "人を", times, "回抽出)"),
xlab=paste("年収(万円),母平均", round(mean(data01$income), 1), "万円"))
n <- 50 # サンプルサイズの指定
sample_mean <- vector(length=times) # times個得られるはずの標本平均の入れ物ヴェクトルを用意
for (i in 1:times) { # times回だけ以下の操作を繰り返す
temp_sample <- sample(data01$income, n) # サイズnの標本を抽出する
sample_mean[i] <- mean(temp_sample) # 抽出した標本の平均を計算する
}
hist(sample_mean, freq=TRUE, ylab="標本の数",
main=paste("年収の標本平均のヒストグラム\n(標本サイズ", n, "人を", times, "回抽出)"),
xlab=paste("年収(万円),母平均", round(mean(data01$income), 1), "万円"))
テキストの,標準正規分布の95%区間のグラフを描くスクリプトを(少し簡素化して)示しておくので,pの値を.90や.99などに書き換えて実行してみよう。コマンドを一つずつ実行していくと,それぞれが何をするコマンドなのかが分かり易くなる。
p <- .95 # この値を .90や.99など書き換えて実行してみよ。
x <- seq(-4,4,by=0.1)
lwr <- qnorm((1-p)/2, mean=0, sd=1)
upr <- qnorm(1-(1-p)/2, mean=0, sd=1)
plot(x, dnorm(x, 0, 1), bty="n", xlab=paste(p*100, "%区間の限界値"),
ylab="確率密度", main="標準正規分布",
type="l", ylim=c(0, 0.45), las=1, xaxt="n")
segments(-4, 0, 4, 0)
axis(side=1, at=c(0), las=1)
x2 <- c(seq(-4, lwr, by=.01), seq(upr, 4, by=.01))
axis(side=1, at=c(round(lwr, 3), round(upr, 3)), las=2)
segments(x2, 0, x2, dnorm(x2, 0, 1), col="gray")
x <- seq(-4,4,by=0.1)
lwr <- qnorm((1-p)/2, mean=0, sd=1)
upr <- qnorm(1-(1-p)/2, mean=0, sd=1)
plot(x, dnorm(x, 0, 1), bty="n", xlab=paste(p*100, "%区間の限界値"),
ylab="確率密度", main="標準正規分布",
type="l", ylim=c(0, 0.45), las=1, xaxt="n")
segments(-4, 0, 4, 0)
axis(side=1, at=c(0), las=1)
x2 <- c(seq(-4, lwr, by=.01), seq(upr, 4, by=.01))
axis(side=1, at=c(round(lwr, 3), round(upr, 3)), las=2)
segments(x2, 0, x2, dnorm(x2, 0, 1), col="gray")
1-3 母平均の区間推定(interval estimation)
99.9%信頼区間を求めるための信頼係数を本文では3.29と書いているが,p <- .999; qnorm(1-(1-p)/2, mean=0, sd=1) とすれば,3.290527と求められる。
標準正規分布とt分布を重ねて描いているグラフは,以下のスクリプトでほぼ再現できる(本文より少し簡略化してある)。
標準正規分布とt分布を重ねて描いているグラフは,以下のスクリプトでほぼ再現できる(本文より少し簡略化してある)。
.df <- 6 # t分布の自由度を書き換えることができる
x <- seq(-4, 4, by=.01)
plot(x, dnorm(x, 0, 1), bty="n", xlab="95%区間の限界値", ylab="確率密度",
main=paste("標準正規分布(実線)と自由度", .df, "のt分布(点線)"),
type="l", ylim=c(0, 0.45), las=1, xaxt="n")
segments(-4, 0, 4, 0)
axis(side=1, at=c(0), las=1)
par(new=T)
plot(x, dt(x, df=.df), bty="n", xlab="", ylab="", axes=F,
main="", type="l", lty=2, ylim=c(0, 0.45))
x2 <- c(seq(-4, qt(.025, .df), by=.01), seq(qt(.975, .df), 4, by=.01))
x3 <- c(seq(-4, qnorm(.025, 0, 1), by=.01), seq(qnorm(.975, 0, 1), 4, by=.01))
segments(x2, 0, x2, dt(x2, .df), col="#00000060")
axis(side=1, at=c(round(qt(.025, .df),2), round(qt(.975, .df),2)), las=2)
segments(x3, 0, x3, dnorm(x3, 0, 1), col="#00000020")
axis(side=1, at=c(round(qnorm(.025, 0, 1),2), round(qnorm(.975, 0, 1),2)), las=2)
自由度6のt分布の95%限界値は,qt(.975, df=6) より 2.446912 と求められる。詳細は以下のページを是非参照して欲しい。x <- seq(-4, 4, by=.01)
plot(x, dnorm(x, 0, 1), bty="n", xlab="95%区間の限界値", ylab="確率密度",
main=paste("標準正規分布(実線)と自由度", .df, "のt分布(点線)"),
type="l", ylim=c(0, 0.45), las=1, xaxt="n")
segments(-4, 0, 4, 0)
axis(side=1, at=c(0), las=1)
par(new=T)
plot(x, dt(x, df=.df), bty="n", xlab="", ylab="", axes=F,
main="", type="l", lty=2, ylim=c(0, 0.45))
x2 <- c(seq(-4, qt(.025, .df), by=.01), seq(qt(.975, .df), 4, by=.01))
x3 <- c(seq(-4, qnorm(.025, 0, 1), by=.01), seq(qnorm(.975, 0, 1), 4, by=.01))
segments(x2, 0, x2, dt(x2, .df), col="#00000060")
axis(side=1, at=c(round(qt(.025, .df),2), round(qt(.975, .df),2)), las=2)
segments(x3, 0, x3, dnorm(x3, 0, 1), col="#00000020")
axis(side=1, at=c(round(qnorm(.025, 0, 1),2), round(qnorm(.975, 0, 1),2)), las=2)
1-4 区間推定シミュレイション
N=4894の母集団からn=200の標本を20回抽出して,その都度信頼区間を求め,それを本文のようなグラフに作図するスクリプトを示す。長いので,前半と後半に分ける。
以下の後半は,この標本平均と標本標準偏差から信頼区間を計算してグラフにするスクリプトである。alphaを書き換えてこの後半だけを繰り返すと,同じ20組の標本群について,異なる信頼区間のグラフを得る事が出来る。
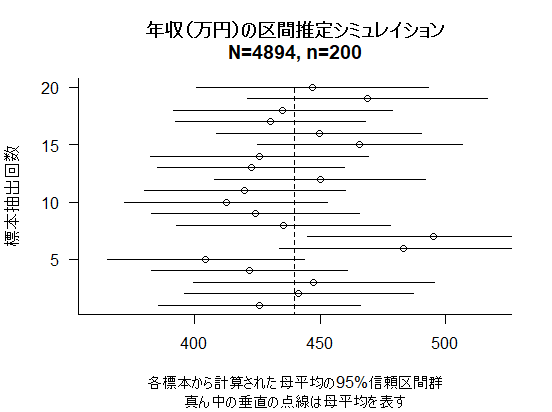
次に,スクリプトの後半だけを,alpha=.90として実行したグラフを示す(11/Aug./2017修正)。
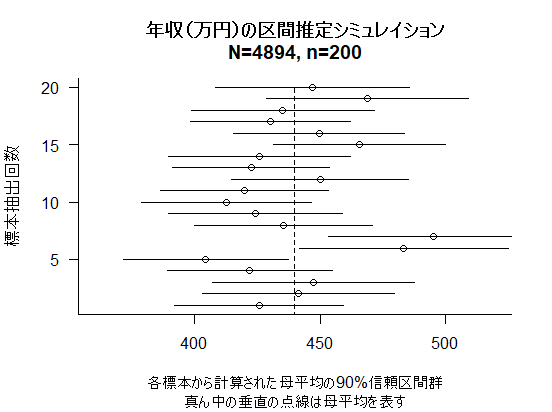
信頼区間がそれぞれ少し狭くなっている事が見て確認出来るだろう。
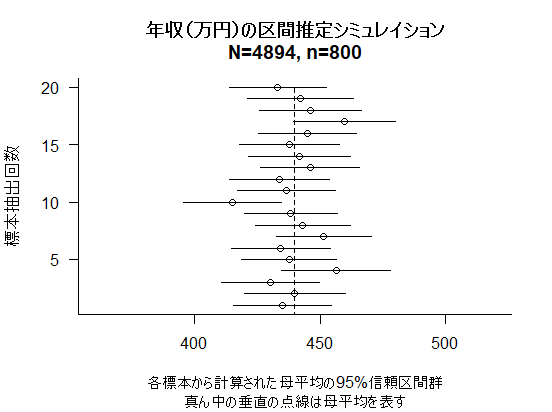
最後に,n=800,alpha=.95として前半・後半を実行したグラフを示す(11/Aug./2017修正)。標本抽出からやり直すので上記の二つのグラフとの対応関係はないが,全体的に標本平均のバラつきがぐっと小さくなり,かつ信頼区間が狭くなっている事が見て取れるだろう。これが,標本サイズを大きくする事で得られる効果である。
data01 <- read.csv("mock_income.csv")
times <- 20 # 抽出回数の指定
n <- 200 # サンプルサイズの指定
N <- length(data01$income) # 母集団サイズを算出
sample_mean <- vector(length=times)
sample_sd <- vector(length=times)
uplimit <- vector(length=times) # 信頼区間上限のヴェクトル
lowlimit <- vector(length=times) # 信頼区間下限のヴェクトル
# times回だけ以下の標本抽出と標本統計量の計算の操作を繰り返す
for (i in 1:times) {
temp_sample <- sample(data01$income, n)
sample_mean[i] <- mean(temp_sample)
sample_sd[i] <- sd(temp_sample) # 11/Aug./2017修正
}
ここまでの前半で,サイズnの標本をtimes回抽出し,それぞれの標本における標本平均と標本標準偏差を計算している。nとtimesは変える事が出来る。times <- 20 # 抽出回数の指定
n <- 200 # サンプルサイズの指定
N <- length(data01$income) # 母集団サイズを算出
sample_mean <- vector(length=times)
sample_sd <- vector(length=times)
uplimit <- vector(length=times) # 信頼区間上限のヴェクトル
lowlimit <- vector(length=times) # 信頼区間下限のヴェクトル
# times回だけ以下の標本抽出と標本統計量の計算の操作を繰り返す
for (i in 1:times) {
temp_sample <- sample(data01$income, n)
sample_mean[i] <- mean(temp_sample)
sample_sd[i] <- sd(temp_sample) # 11/Aug./2017修正
}
以下の後半は,この標本平均と標本標準偏差から信頼区間を計算してグラフにするスクリプトである。alphaを書き換えてこの後半だけを繰り返すと,同じ20組の標本群について,異なる信頼区間のグラフを得る事が出来る。
# ここから先だけを,alphaの値を変えて繰り返す事が出来る
alpha <- .90 # 信頼水準の設定
t_alpha <- qt((1-alpha)/2, df=n-1, lower.tail=FALSE) # 限界値の計算
# 信頼区間の上限と下限の計算
uplimit <- sample_mean + t_alpha*sqrt((N-n)/(N-1))*sample_sd/sqrt(n)
lowlimit <- sample_mean - t_alpha*sqrt((N-n)/(N-1))*sample_sd/sqrt(n)
windows(width=7, height=5) # グラフウィンドウの大きさの指定
plot(sample_mean, c(1:times), bty="l", las=1, xlim=c(360, 520),
sub="真ん中の垂直の点線は母平均を表す", ylab="標本抽出回数",
xlab=sprintf("各標本から計算された母平均の%.0f%%信頼区間群", alpha*100),
main=sprintf("年収(万円)の区間推定シミュレイション\nN=%d, n=%d", N, n))
segments(lowlimit, c(1:times), uplimit, c(1:times))
segments(mean(data01$income), 0, mean(data01$income), times, lty=2)
ここでまず,n=200,times=20,alpha=.95として,前半と後半を実行したグラフを示す(11/Aug./2017修正)。alpha <- .90 # 信頼水準の設定
t_alpha <- qt((1-alpha)/2, df=n-1, lower.tail=FALSE) # 限界値の計算
# 信頼区間の上限と下限の計算
uplimit <- sample_mean + t_alpha*sqrt((N-n)/(N-1))*sample_sd/sqrt(n)
lowlimit <- sample_mean - t_alpha*sqrt((N-n)/(N-1))*sample_sd/sqrt(n)
windows(width=7, height=5) # グラフウィンドウの大きさの指定
plot(sample_mean, c(1:times), bty="l", las=1, xlim=c(360, 520),
sub="真ん中の垂直の点線は母平均を表す", ylab="標本抽出回数",
xlab=sprintf("各標本から計算された母平均の%.0f%%信頼区間群", alpha*100),
main=sprintf("年収(万円)の区間推定シミュレイション\nN=%d, n=%d", N, n))
segments(lowlimit, c(1:times), uplimit, c(1:times))
segments(mean(data01$income), 0, mean(data01$income), times, lty=2)
次に,スクリプトの後半だけを,alpha=.90として実行したグラフを示す(11/Aug./2017修正)。
信頼区間がそれぞれ少し狭くなっている事が見て確認出来るだろう。
最後に,n=800,alpha=.95として前半・後半を実行したグラフを示す(11/Aug./2017修正)。標本抽出からやり直すので上記の二つのグラフとの対応関係はないが,全体的に標本平均のバラつきがぐっと小さくなり,かつ信頼区間が狭くなっている事が見て取れるだろう。これが,標本サイズを大きくする事で得られる効果である。
発展1 母比率の区間推定
二項分布に関する関数を紹介しよう。仮に母比率を pi としたとき,サイズ n の標本において内閣支持者が w 人となる確率は,choose(n, w)*pi^w*(1-pi)^(n-w) として計算出来る。pi = .473,n=10,w=5 とした時の実行結果を以下に示す。
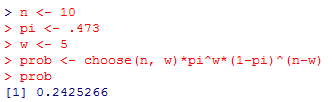
ここで,以下のように w を少し工夫して,5人以上となる確率をそれぞれ求め,その合計も求めてみる。
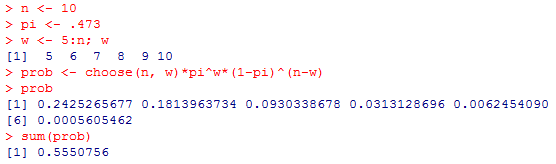
この結果は,母比率が47.3%であるとき,10人の標本中5人が支持者である確率が24.3%,6人が支持者である確率が18.1%,10人全員が支持者である確率が0.056%,それらを全て合計した5人以上が支持者である確率が55.5%である事を示している。
w <- 0:n とすると,有り得る全ての場合について計算される。確率の合計は必然的に1となる。

同じ計算は,dbinom(w, n, pi) という関数を使って行う事が出来る。

最低限のグラフを描くには以下のコマンドだけでよい。2つあるが,どちらも同じグラフとなる。前者の描画例だけを下に示す。
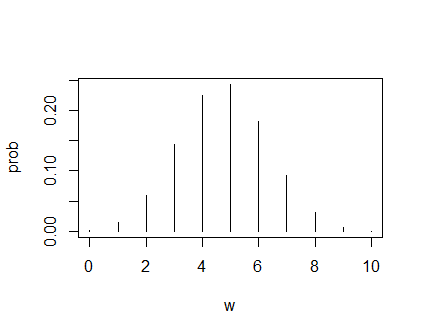
これではあまりに素っ気ないので,以下のようにオプションを追加して描いてみる。
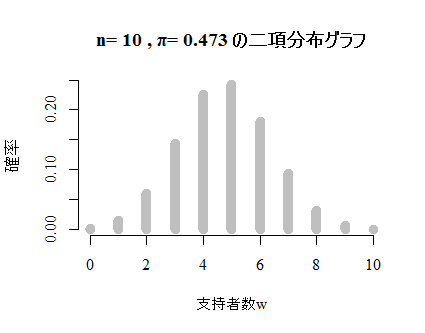
本文ではn=25,π=.40のグラフを掲載しているが,以下にはn=50,π=.473の例を掲載しよう。オプション lwd は"line width"で,nが大きくなるとこの「棒線の太さ」を細くしないと棒が重なってしまうので,以下ではlwd=2としてある。
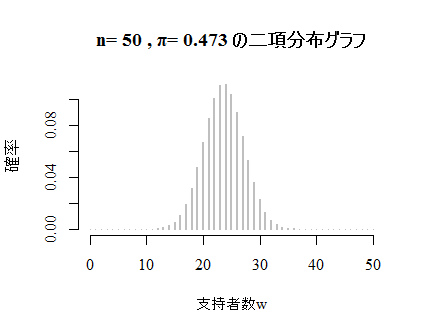
本文同様,正規分布に非常に似通っている事が確認出来る。
以下は,x軸を支持者数wではなく,標本比率w/nにしてグラフを描くスクリプトである。

実際に二値変数を発生させて,標本分散と不偏分散を比較してみる。

標本分散を用いても不偏分散を用いても殆ど違いがない。
以下,本文の世論調査(内閣支持率p=.412,標本サイズn=1248)の区間推定を行う。
本文よりも少し工夫したスクリプトを挙げるので見比べてみると良い。

有限母集団修正項(fpc),不偏分散とt分布を用いた場合は下記となる。

本文で,n=10,p=.20のような場合は標準正規分布やt分布を用いて計算した信頼区間が不適切である事を述べた。F分布を用いた計算も含めて以下で示す。

本来は二項分布を用いて求めるべきものであるので,以下の様に求めてみる。
pi <- seq(0, 1, by=0.000001) として,母比率 pi を0から1までの間で,0.0001%単位で変化させたヴェクトルを作る。
x=n*p(標本において,二値変数uが1となる人数)である時,関数 pbinom(x, size=n, prob=pi) は,母比率がpiである時にn人の標本においてu=1となる人数がx人以下となる確率を意味する。例えば,pbinom(4, size=10, prob=.473) の結果は 0.4449244 となる。
95%信頼区間というのは,「母比率がpiである時に,標本比率がx/n以下(つまり該当者がx人以下)になる確率が2.5%以上であり,かつ標本比率がx/n以上になる確率も2.5%以上になる」範囲に由来する。
該当者がx人以下になる確率が2.5%以上という条件は pbinom(x, n, pi) >= .025 と書ける。該当者がx人以上になる確率が2.5%以上という条件は,該当者がx人未満(x-1人以下)になる確率が97.5%以下になる事と等しいので,pbinom(x-1, n, pi) <= .975 と書ける。ただし,x-1がマイナスになるとエラーが生じるので,pbinom(max(0, x-1), n, pi) <= .975 としなければならない。
この条件を合わせると,pbinom(x, n, pi) >= .025 & pbinom(max(0, x-1), n, pi) <= .975 となる。
より一般化して,pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2 とする。
この条件を充たすpiの集合 pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2] が(alpha*100)%信頼区間となるので,その下限minと上限maxを求めればよい。

F分布を使用して求めた区間とほぼ一致している事が確認出来る。もっと精度を粗くして良いなら,by=0.000001の部分をby=0.00001やby=0.0001にすると,計算時間がぐっと短縮される。
標本1,248人中514人が支持者であった場合の信頼区間を,正規分布近似,t分布近似,F分布使用,二項分布スクリプトのそれぞれで求めたのが下記である。

いずれを用いても実用上はほぼ問題無い程度の違いと言えるだろう。
ここで,以下のように w を少し工夫して,5人以上となる確率をそれぞれ求め,その合計も求めてみる。
この結果は,母比率が47.3%であるとき,10人の標本中5人が支持者である確率が24.3%,6人が支持者である確率が18.1%,10人全員が支持者である確率が0.056%,それらを全て合計した5人以上が支持者である確率が55.5%である事を示している。
w <- 0:n とすると,有り得る全ての場合について計算される。確率の合計は必然的に1となる。
同じ計算は,dbinom(w, n, pi) という関数を使って行う事が出来る。
最低限のグラフを描くには以下のコマンドだけでよい。2つあるが,どちらも同じグラフとなる。前者の描画例だけを下に示す。
plot(w, prob, type="h") # 最低限の,飾り気のないプロット
plot(w, dbinom(w, n, pi), type="h") # これでも同じグラフ
plot(w, dbinom(w, n, pi), type="h") # これでも同じグラフ
これではあまりに素っ気ないので,以下のようにオプションを追加して描いてみる。
plot(w, prob, type="h", lwd=10, col="#00000040",
bty="n", ylab="確率", xlab="支持者数w", family="serif",
main=paste("n=", n, ", π=", pi, "の二項分布グラフ"))
bty="n", ylab="確率", xlab="支持者数w", family="serif",
main=paste("n=", n, ", π=", pi, "の二項分布グラフ"))
本文ではn=25,π=.40のグラフを掲載しているが,以下にはn=50,π=.473の例を掲載しよう。オプション lwd は"line width"で,nが大きくなるとこの「棒線の太さ」を細くしないと棒が重なってしまうので,以下ではlwd=2としてある。
n <- 50
pi <- .473
w <- 0:n
prob <- choose(n, w)*pi^w*(1-pi)^(n-w)
plot(w, prob, type="h", lwd=2, col="#00000040",
bty="n", ylab="確率", xlab="支持者数w", family="serif",
main=paste("n=", n, ", π=", pi, "の二項分布グラフ"))
pi <- .473
w <- 0:n
prob <- choose(n, w)*pi^w*(1-pi)^(n-w)
plot(w, prob, type="h", lwd=2, col="#00000040",
bty="n", ylab="確率", xlab="支持者数w", family="serif",
main=paste("n=", n, ", π=", pi, "の二項分布グラフ"))
本文同様,正規分布に非常に似通っている事が確認出来る。
以下は,x軸を支持者数wではなく,標本比率w/nにしてグラフを描くスクリプトである。
n <- 100
pi <- .4
w <- 0:n
prob <- choose(n, w)*pi^w*(1-pi)^(n-w)
plot(w/n, prob, type="h", lwd=2, col="#00000040",
bty="n", ylab="確率", family="serif", xlab="標本比率w/n",
main=paste("標本サイズn=", n, ", 母比率π=", pi, "の二項分布グラフ"))
ここで少し脱線して,二値変数の分散の求め方を示しておこう。pi <- .4
w <- 0:n
prob <- choose(n, w)*pi^w*(1-pi)^(n-w)
plot(w/n, prob, type="h", lwd=2, col="#00000040",
bty="n", ylab="確率", family="serif", xlab="標本比率w/n",
main=paste("標本サイズn=", n, ", 母比率π=", pi, "の二項分布グラフ"))
実際に二値変数を発生させて,標本分散と不偏分散を比較してみる。
n <- 1248 # 標本サイズ
pi <- .45 # 母比率
u <- rbinom(n, 1, pi)
table(u) # 標本における変数値の分布
mean(u) # 標本平均
var(u) # Rによる分散(不偏分散)
mean((u-mean(u))^2) # 定義から計算した標本分散
n*mean((u-mean(u))^2)/(n-1) # 定義から計算した不偏分散
pi <- .45 # 母比率
u <- rbinom(n, 1, pi)
table(u) # 標本における変数値の分布
mean(u) # 標本平均
var(u) # Rによる分散(不偏分散)
mean((u-mean(u))^2) # 定義から計算した標本分散
n*mean((u-mean(u))^2)/(n-1) # 定義から計算した不偏分散
標本分散を用いても不偏分散を用いても殆ど違いがない。
以下,本文の世論調査(内閣支持率p=.412,標本サイズn=1248)の区間推定を行う。
本文よりも少し工夫したスクリプトを挙げるので見比べてみると良い。
# 標本比率と標本サイズの指定
p <- .412; n <- 1248; alpha <- .95
# 標準正規分布を用いて(alpha*100)%信頼区間の上限と下限の計算
lwr <- p - qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
upr <- p + qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
lwr; upr # 計算結果の表示
p <- .412; n <- 1248; alpha <- .95
# 標準正規分布を用いて(alpha*100)%信頼区間の上限と下限の計算
lwr <- p - qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
upr <- p + qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
lwr; upr # 計算結果の表示
有限母集団修正項(fpc),不偏分散とt分布を用いた場合は下記となる。
本文で,n=10,p=.20のような場合は標準正規分布やt分布を用いて計算した信頼区間が不適切である事を述べた。F分布を用いた計算も含めて以下で示す。
# 標本比率と標本サイズの指定
p <- .20; n <- 10; alpha <- .95
# 標準正規分布を用いて(alpha*100)%信頼区間の上限と下限の計算
lwr <- p - qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
upr <- p + qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
lwr; upr # 計算結果の表示
# t分布を用いて(alpha*100)%信頼区間の上限と下限の計算
N <- 104000000
lwr2 <- p - qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
upr2 <- p + qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
lwr2; upr2 # 計算結果の表示
x <- n*p
# F分布で求める信頼区間下限
2*x/(2*x+2*(n-x+1)*qf(.975, 2*(n-x+1), 2*x))
# F分布で求める信頼区間上限
2*(x+1)*qf(.975, 2*(x+1), 2*(n-x))/(2*(n-x)+2*(x+1)*qf(.975, 2*(x+1), 2*(n-x)))
p <- .20; n <- 10; alpha <- .95
# 標準正規分布を用いて(alpha*100)%信頼区間の上限と下限の計算
lwr <- p - qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
upr <- p + qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
lwr; upr # 計算結果の表示
# t分布を用いて(alpha*100)%信頼区間の上限と下限の計算
N <- 104000000
lwr2 <- p - qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
upr2 <- p + qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
lwr2; upr2 # 計算結果の表示
x <- n*p
# F分布で求める信頼区間下限
2*x/(2*x+2*(n-x+1)*qf(.975, 2*(n-x+1), 2*x))
# F分布で求める信頼区間上限
2*(x+1)*qf(.975, 2*(x+1), 2*(n-x))/(2*(n-x)+2*(x+1)*qf(.975, 2*(x+1), 2*(n-x)))
本来は二項分布を用いて求めるべきものであるので,以下の様に求めてみる。
pi <- seq(0, 1, by=0.000001) として,母比率 pi を0から1までの間で,0.0001%単位で変化させたヴェクトルを作る。
x=n*p(標本において,二値変数uが1となる人数)である時,関数 pbinom(x, size=n, prob=pi) は,母比率がpiである時にn人の標本においてu=1となる人数がx人以下となる確率を意味する。例えば,pbinom(4, size=10, prob=.473) の結果は 0.4449244 となる。
95%信頼区間というのは,「母比率がpiである時に,標本比率がx/n以下(つまり該当者がx人以下)になる確率が2.5%以上であり,かつ標本比率がx/n以上になる確率も2.5%以上になる」範囲に由来する。
該当者がx人以下になる確率が2.5%以上という条件は pbinom(x, n, pi) >= .025 と書ける。該当者がx人以上になる確率が2.5%以上という条件は,該当者がx人未満(x-1人以下)になる確率が97.5%以下になる事と等しいので,pbinom(x-1, n, pi) <= .975 と書ける。ただし,x-1がマイナスになるとエラーが生じるので,pbinom(max(0, x-1), n, pi) <= .975 としなければならない。
この条件を合わせると,pbinom(x, n, pi) >= .025 & pbinom(max(0, x-1), n, pi) <= .975 となる。
より一般化して,pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2 とする。
この条件を充たすpiの集合 pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2] が(alpha*100)%信頼区間となるので,その下限minと上限maxを求めればよい。
p <- .20; n <- 10; alpha <- .95
pi <- seq(0, 1, by=0.000001) # 母比率を0から1まで,.0001%単位で変化させる
lower <- min(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2]) # 下限値
upper <- max(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2]) # 上限値
lower; upper
pi <- seq(0, 1, by=0.000001) # 母比率を0から1まで,.0001%単位で変化させる
lower <- min(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2]) # 下限値
upper <- max(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2]) # 上限値
lower; upper
F分布を使用して求めた区間とほぼ一致している事が確認出来る。もっと精度を粗くして良いなら,by=0.000001の部分をby=0.00001やby=0.0001にすると,計算時間がぐっと短縮される。
標本1,248人中514人が支持者であった場合の信頼区間を,正規分布近似,t分布近似,F分布使用,二項分布スクリプトのそれぞれで求めたのが下記である。
# 標本比率と標本サイズ,信頼係数などの指定
n <- 1248; x <- 512; p <- x/n; alpha <- .95
# 標準正規分布を用いて(alpha*100)%信頼区間の上限と下限の計算
lwr <- p - qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
upr <- p + qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
lwr; upr
# t分布を用いて(alpha*100)%信頼区間の上限と下限の計算
N <- 104000000
lwr2 <- p - qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
upr2 <- p + qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
lwr2; upr2
# F分布で求める信頼区間下限と下限
2*x/(2*x+2*(n-x+1)*qf(.975, 2*(n-x+1), 2*x)); 2*(x+1)*qf(.975, 2*(x+1), 2*(n-x))/(2*(n-x)+2*(x+1)*qf(.975, 2*(x+1), 2*(n-x)))
# 二項分布スクリプト
pi <- seq(0, 1, by=0.000001)
lower <- min(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2])
upper <- max(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2])
lower; upper
n <- 1248; x <- 512; p <- x/n; alpha <- .95
# 標準正規分布を用いて(alpha*100)%信頼区間の上限と下限の計算
lwr <- p - qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
upr <- p + qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
lwr; upr
# t分布を用いて(alpha*100)%信頼区間の上限と下限の計算
N <- 104000000
lwr2 <- p - qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
upr2 <- p + qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
lwr2; upr2
# F分布で求める信頼区間下限と下限
2*x/(2*x+2*(n-x+1)*qf(.975, 2*(n-x+1), 2*x)); 2*(x+1)*qf(.975, 2*(x+1), 2*(n-x))/(2*(n-x)+2*(x+1)*qf(.975, 2*(x+1), 2*(n-x)))
# 二項分布スクリプト
pi <- seq(0, 1, by=0.000001)
lower <- min(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2])
upper <- max(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2])
lower; upper
いずれを用いても実用上はほぼ問題無い程度の違いと言えるだろう。
発展2 無回答誤差(non-response error)
本書ではユニット無回答(unit non-response)や項目無回答(item non-response)については殆ど扱っていないので,ここでだけほんの少し無回答の影響について検討してみよう。
対象となる社会が高収入群と低収入群1:1であるとする。簡便化の為に,高収入群の平均年収を500(万円)に,高収入群の回収率(ユニット回答率)を50%に固定する。収入格差をdM(万円),回収率の差をdr(ポイント)とし,この二つの値だけを変化させて比較する。
詳しくコメントを付けたスクリプトは下記である。

この数値例では,二群の平均収入差は全体平均の50%,高収入群の平均の40%に相当し,回収率の差は20%ポイント,母平均400万円に対して標本平均は425万円となり,バイアスは25万円,バイアスの母平均に対する比は6.25%となる。
収入格差と回収率差を変化させるとどうなるかを以下に示すので自分で読み解いてみよう。

まず教育年数eduを適当に尤もらしい確率で乱数発生させ,次にそのeduと強く順相関する年収データincome0を生成する。更に,年収が低い程高い値を取りやすい0〜1の範囲の変数missを生成させて,missの上位10%のケースについて,年収だけをNAにした変数incomeを生成する。最後に,それらの要約統計量と相関係数行列を示している。
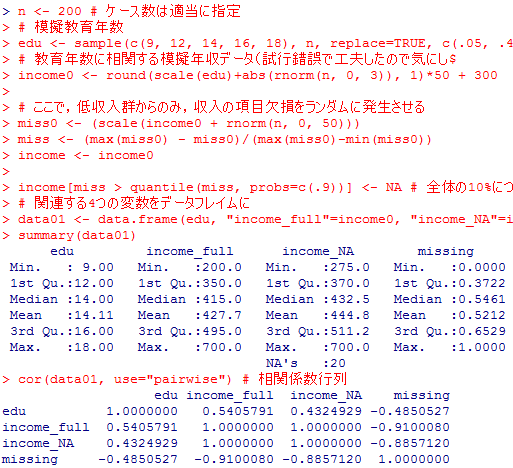
当然,欠損を含んだ年収incomeは分布が全体に高い方にずれ,教育年数eduとの積率相関は完備データ(income_full)より低下している。本来は教育年数と年収はもっと強く相関しているのに,低収入層が不釣り合いに分析から除外される為に,相関が弱まって見えてしまっていると云う(仮想的)状況である。これは「完備データ分析(complete case analysis)」の問題を示している。
まずは有効ケースの平均でNAを置き換える方法の結果を示す。スクリプトと結果から解読してみよう。
よく考えれば当然だが,分布はより平均に集中してバラつきが小さくなり,教育年数eduとの相関も更に小さくなっている。主に低い年収であった筈のケースが全体平均年収で補定されているのであるから当然そうなる。欠測がランダムではない上の例の限りでは,平均値で補定する利点は無い。
次に,収入の欠測を,収入を教育年数に回帰させた結果を用いた予測値で置換する方法を示す。偶然誤差(攪乱項)を含まない回帰補定である。回帰分析の結果を利用する為に,summary( )関数,names( )関数などで確認をしている部分も敢えて表示させている。それぞれの意味をしっかり解読しよう。

次がここでの本来の目的の回帰補定の結果と比較である。平均値補定程はバラつきは過小にならないが,それでも本来の分布からすると集中度が高く,平均値も未だ高い。教育年数との相関も,平均値補定程は弱くならないが,本来の相関からするとまだ弱い。欠損値生成(miss0が登場する行以降)をやり直すと結果は変化するが,何度か繰り返してもこの傾向は変わらない。自分で確認してみると良い。
このほか,回帰補定に誤差(攪乱項)を交える方法や,複数の値で補定して異なるデータセット・分析結果を作り出して,その結果を統合する多重代入法(multiple imputation)などの方法がある。注目度が高いのは最後の多重代入法であるが,高度な内容になるのでここでは割愛する。
回収率(回答率;response rate)と無回答バイアス(non-response bias)
ごく簡単な例として,架空の単純なモデルを考えてみよう。対象となる社会が高収入群と低収入群1:1であるとする。簡便化の為に,高収入群の平均年収を500(万円)に,高収入群の回収率(ユニット回答率)を50%に固定する。収入格差をdM(万円),回収率の差をdr(ポイント)とし,この二つの値だけを変化させて比較する。
詳しくコメントを付けたスクリプトは下記である。
Mh <- 500; rh <- .50 # 高収入群
dM <- 200; dr <- .20 # 二群の差
# 母集団に於ける平均年収は,当然中間値になる。
M <- (Mh + (Mh -dM))/2; M # 母平均
# 二群の母平均差と全体母平均の比, 及び高所得群平均の比
dM/M; dM/Mh
# 標本平均。それぞれの設計標本サイズをn(同比率なので共通)とすると,
# (Mh*n*rh + (Mh-dM)*n*(rh-dr))/(n*rh + n*(rh-dr))
# (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr))
m <- (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr)); m
# 回収率差,標本平均と真の母平均の差,及びその差の母平均に対する比
dr; m - M; (m - M)/M
dM <- 200; dr <- .20 # 二群の差
# 母集団に於ける平均年収は,当然中間値になる。
M <- (Mh + (Mh -dM))/2; M # 母平均
# 二群の母平均差と全体母平均の比, 及び高所得群平均の比
dM/M; dM/Mh
# 標本平均。それぞれの設計標本サイズをn(同比率なので共通)とすると,
# (Mh*n*rh + (Mh-dM)*n*(rh-dr))/(n*rh + n*(rh-dr))
# (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr))
m <- (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr)); m
# 回収率差,標本平均と真の母平均の差,及びその差の母平均に対する比
dr; m - M; (m - M)/M
この数値例では,二群の平均収入差は全体平均の50%,高収入群の平均の40%に相当し,回収率の差は20%ポイント,母平均400万円に対して標本平均は425万円となり,バイアスは25万円,バイアスの母平均に対する比は6.25%となる。
収入格差と回収率差を変化させるとどうなるかを以下に示すので自分で読み解いてみよう。
### 繰り返し比較用
dM <- 200; dr <- .20 # 収入格差も回答率差も中程度
M <- (Mh + (Mh -dM))/2
m <- (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr))
M; dM/M; dM/Mh
dr; m; m - M; (m - M)/M
dM <- 100; dr <- .40 # 収入格差小,回答率差大
M <- (Mh + (Mh -dM))/2
m <- (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr))
M; dM/M; dM/Mh
dr; m; m - M; (m - M)/M
dM <- 400; dr <- .10 # 収入格差大,回答率差小
M <- (Mh + (Mh -dM))/2
m <- (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr))
M; dM/M; dM/Mh
dr; m; m - M; (m - M)/M
dM <- 200; dr <- .20 # 収入格差も回答率差も中程度
M <- (Mh + (Mh -dM))/2
m <- (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr))
M; dM/M; dM/Mh
dr; m; m - M; (m - M)/M
dM <- 100; dr <- .40 # 収入格差小,回答率差大
M <- (Mh + (Mh -dM))/2
m <- (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr))
M; dM/M; dM/Mh
dr; m; m - M; (m - M)/M
dM <- 400; dr <- .10 # 収入格差大,回答率差小
M <- (Mh + (Mh -dM))/2
m <- (Mh*rh + (Mh-dM)*(rh-dr))/(rh + (rh-dr))
M; dM/M; dM/Mh
dr; m; m - M; (m - M)/M
項目無回答と欠損値補定(補綴;imputation)
やや分かりにくいが,教育年数と年収の模擬データを発生させ,そこから人為的に欠損値を発生させ,どの様な結果が得られるかを例示してみる。まず教育年数eduを適当に尤もらしい確率で乱数発生させ,次にそのeduと強く順相関する年収データincome0を生成する。更に,年収が低い程高い値を取りやすい0〜1の範囲の変数missを生成させて,missの上位10%のケースについて,年収だけをNAにした変数incomeを生成する。最後に,それらの要約統計量と相関係数行列を示している。
n <- 200 # ケース数は適当に指定
# 模擬教育年数
edu <- sample(c(9, 12, 14, 16, 18), n, replace=TRUE, c(.05, .40, .15, .35, .05))
# 教育年数に相関する模擬年収データ(試行錯誤で工夫したので気にしなくて良い)
income0 <- round(scale(edu)+abs(rnorm(n, 0, 3)), 1)*50 + 300
# ここで,低収入群からのみ,収入の項目欠損をランダムに発生させる
miss0 <- (scale(income0 + rnorm(n, 0, 50)))
miss <- (max(miss0) - miss0)/(max(miss0)-min(miss0))
income <- income0
income[miss > quantile(miss, probs=c(.9))] <- NA # 全体の10%について年収欠損の生成
# 関連する4つの変数をデータフレイムに
data01 <- data.frame(edu, "income_full"=income0, "income_NA"=income, "missing"=miss)
summary(data01)
cor(data01, use="pairwise") # 相関係数行列
# 模擬教育年数
edu <- sample(c(9, 12, 14, 16, 18), n, replace=TRUE, c(.05, .40, .15, .35, .05))
# 教育年数に相関する模擬年収データ(試行錯誤で工夫したので気にしなくて良い)
income0 <- round(scale(edu)+abs(rnorm(n, 0, 3)), 1)*50 + 300
# ここで,低収入群からのみ,収入の項目欠損をランダムに発生させる
miss0 <- (scale(income0 + rnorm(n, 0, 50)))
miss <- (max(miss0) - miss0)/(max(miss0)-min(miss0))
income <- income0
income[miss > quantile(miss, probs=c(.9))] <- NA # 全体の10%について年収欠損の生成
# 関連する4つの変数をデータフレイムに
data01 <- data.frame(edu, "income_full"=income0, "income_NA"=income, "missing"=miss)
summary(data01)
cor(data01, use="pairwise") # 相関係数行列
当然,欠損を含んだ年収incomeは分布が全体に高い方にずれ,教育年数eduとの積率相関は完備データ(income_full)より低下している。本来は教育年数と年収はもっと強く相関しているのに,低収入層が不釣り合いに分析から除外される為に,相関が弱まって見えてしまっていると云う(仮想的)状況である。これは「完備データ分析(complete case analysis)」の問題を示している。
最も簡単な欠損値補定の例
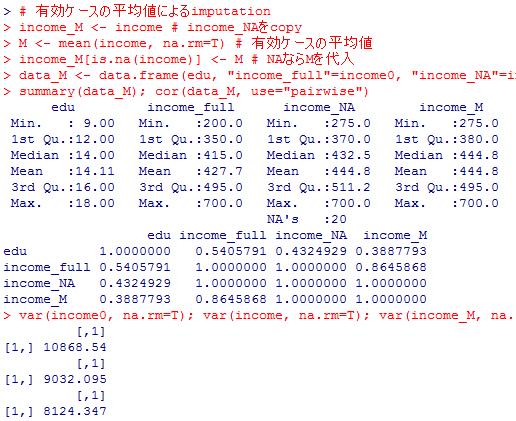
ここで,最も簡単な欠損値補定(imputation)の例を示して,より複雑な補定が必要である事だけ示唆しておこう。まずは有効ケースの平均でNAを置き換える方法の結果を示す。スクリプトと結果から解読してみよう。
# 有効ケースの平均値によるimputation
income_M <- income # income_NAをcopy
M <- mean(income, na.rm=T) # 有効ケースの平均値
income_M[is.na(income)] <- M # NAならMを代入
data_M <- data.frame(edu, "income_full"=income0, "income_NA"=income, "income_M"=income_M)
summary(data_M); cor(data_M, use="pairwise")
var(income0, na.rm=T); var(income, na.rm=T); var(income_M, na.rm=T)
income_M <- income # income_NAをcopy
M <- mean(income, na.rm=T) # 有効ケースの平均値
income_M[is.na(income)] <- M # NAならMを代入
data_M <- data.frame(edu, "income_full"=income0, "income_NA"=income, "income_M"=income_M)
summary(data_M); cor(data_M, use="pairwise")
var(income0, na.rm=T); var(income, na.rm=T); var(income_M, na.rm=T)
よく考えれば当然だが,分布はより平均に集中してバラつきが小さくなり,教育年数eduとの相関も更に小さくなっている。主に低い年収であった筈のケースが全体平均年収で補定されているのであるから当然そうなる。欠測がランダムではない上の例の限りでは,平均値で補定する利点は無い。
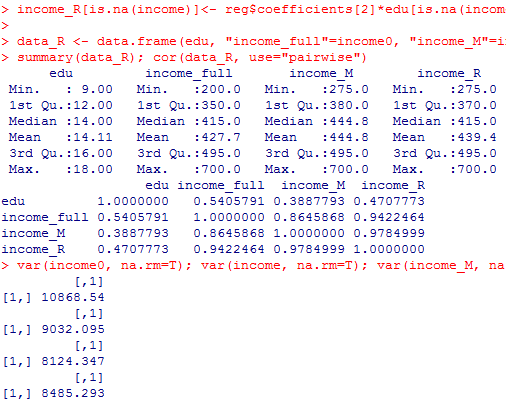
次に,収入の欠測を,収入を教育年数に回帰させた結果を用いた予測値で置換する方法を示す。偶然誤差(攪乱項)を含まない回帰補定である。回帰分析の結果を利用する為に,summary( )関数,names( )関数などで確認をしている部分も敢えて表示させている。それぞれの意味をしっかり解読しよう。
# 誤差を含まない回帰補定
income_R <- income
summary(reg <- lm(income ~ edu)); names(reg); reg$coefficients
income_R[is.na(income)]<- reg$coefficients[2]*edu[is.na(income)] + reg$coefficients[1]
data_R <- data.frame(edu, "income_full"=income0, "income_M"=income_M, "income_R"=income_R)
summary(data_R); cor(data_R, use="pairwise")
var(income0, na.rm=T); var(income, na.rm=T); var(income_M, na.rm=T); var(income_R, na.rm=T)
まずは回帰分析の結果を確認する部分。セミコロン";"で複数のコマンドを一行に書いて一度に結果を表示させているので区切りが分からないかも知れない。そう云う場合はセミコロンを使わずコマンドを一つ一つ実行して確認する。income_R <- income
summary(reg <- lm(income ~ edu)); names(reg); reg$coefficients
income_R[is.na(income)]<- reg$coefficients[2]*edu[is.na(income)] + reg$coefficients[1]
data_R <- data.frame(edu, "income_full"=income0, "income_M"=income_M, "income_R"=income_R)
summary(data_R); cor(data_R, use="pairwise")
var(income0, na.rm=T); var(income, na.rm=T); var(income_M, na.rm=T); var(income_R, na.rm=T)
次がここでの本来の目的の回帰補定の結果と比較である。平均値補定程はバラつきは過小にならないが,それでも本来の分布からすると集中度が高く,平均値も未だ高い。教育年数との相関も,平均値補定程は弱くならないが,本来の相関からするとまだ弱い。欠損値生成(miss0が登場する行以降)をやり直すと結果は変化するが,何度か繰り返してもこの傾向は変わらない。自分で確認してみると良い。
このほか,回帰補定に誤差(攪乱項)を交える方法や,複数の値で補定して異なるデータセット・分析結果を作り出して,その結果を統合する多重代入法(multiple imputation)などの方法がある。注目度が高いのは最後の多重代入法であるが,高度な内容になるのでここでは割愛する。
第3章【練習問題】の解答
1)の答え:
2)の答え:
[1] 1.962339
となるので,「-1.962 以上,1.962 以下」が答えである。
3)の答え:
4)の答え:
標準正規分布近似,F分布計算,二項分布スクリプトの実施例を示す。

いずれを用いるかによって,41.6%〜48.4% もしくは 41.5%〜48.5%と微妙にずれるが,実際に必要な/期待される精度からすれば問題とする差ではない。
5)の答え: 問題文に書かれたスクリプトを実際に実行してみるのが課題である。以下に少し変えて再掲する。

pt(2.00, df=200) - pt(-1.00, df=200)
答えは 0.817314 となる。2)の答え:
qt(.025, df=1000); qt(.975, df=1000)
[1] -1.962339[1] 1.962339
となるので,「-1.962 以上,1.962 以下」が答えである。
3)の答え:
m <- 60; v <- 120; n <- 285
m - qt(.95, df=n-1)*sqrt(v/n)
m + qt(.95, df=n-1)*sqrt(v/n)
答えは, 58.92919 以上,61.07081 以下となる。58.9〜61.1で良いだろう。m - qt(.95, df=n-1)*sqrt(v/n)
m + qt(.95, df=n-1)*sqrt(v/n)
4)の答え:
標準正規分布近似,F分布計算,二項分布スクリプトの実施例を示す。
n <- 800; p <- .45; alpha <- .95
# 標準正規分布を用いて(alpha*100)%信頼区間の上限と下限の計算
lwr <- p - qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
upr <- p + qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
lwr; upr
# t分布を用いて(alpha*100)%信頼区間の上限と下限の計算
N <- 106200000
lwr2 <- p - qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
upr2 <- p + qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
lwr2; upr2
# F分布で求める信頼区間下限と下限
2*x/(2*x+2*(n-x+1)*qf(.975, 2*(n-x+1), 2*x)); 2*(x+1)*qf(.975, 2*(x+1), 2*(n-x))/(2*(n-x)+2*(x+1)*qf(.975, 2*(x+1), 2*(n-x)))
# 二項分布スクリプト
x <- n*p
pi <- seq(0, 1, by=0.00001)
lower <- min(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2])
upper <- max(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2])
lower; upper
# 標準正規分布を用いて(alpha*100)%信頼区間の上限と下限の計算
lwr <- p - qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
upr <- p + qnorm(1-(1-alpha)/2, 0, 1)*sqrt(p*(1-p)/n)
lwr; upr
# t分布を用いて(alpha*100)%信頼区間の上限と下限の計算
N <- 106200000
lwr2 <- p - qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
upr2 <- p + qt(1-(1-alpha)/2, n-1)*sqrt((N-n)/(N-1))*sqrt(p*(1-p)/(n-1))
lwr2; upr2
# F分布で求める信頼区間下限と下限
2*x/(2*x+2*(n-x+1)*qf(.975, 2*(n-x+1), 2*x)); 2*(x+1)*qf(.975, 2*(x+1), 2*(n-x))/(2*(n-x)+2*(x+1)*qf(.975, 2*(x+1), 2*(n-x)))
# 二項分布スクリプト
x <- n*p
pi <- seq(0, 1, by=0.00001)
lower <- min(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2])
upper <- max(pi[pbinom(x, n, pi) >= (1-alpha)/2 & pbinom(max(0, x-1), n, pi) <= 1-(1-alpha)/2])
lower; upper
いずれを用いるかによって,41.6%〜48.4% もしくは 41.5%〜48.5%と微妙にずれるが,実際に必要な/期待される精度からすれば問題とする差ではない。
5)の答え: 問題文に書かれたスクリプトを実際に実行してみるのが課題である。以下に少し変えて再掲する。
population <- rnorm(n=10000, mean=50, sd=10)
mean(population); sd(population); quantile(population)
hist(population)
dev.new() # グラフウィンドウを新たに開く
boxplot(population)
n <- 100
s1 <- sample(population, n)
mean(s1) # 標本平均を求める
mean(s1)-qnorm(.975, 0, 1)*sd(s1)/sqrt(n) # 母平均の95%信頼区間の下限
mean(s1)+qnorm(.975, 0, 1)*sd(s1)/sqrt(n) # 母平均の95%信頼区間の上限
問題文にある様に,サンプリングの部分からだけ繰り返してみる。mean(population); sd(population); quantile(population)
hist(population)
dev.new() # グラフウィンドウを新たに開く
boxplot(population)
n <- 100
s1 <- sample(population, n)
mean(s1) # 標本平均を求める
mean(s1)-qnorm(.975, 0, 1)*sd(s1)/sqrt(n) # 母平均の95%信頼区間の下限
mean(s1)+qnorm(.975, 0, 1)*sd(s1)/sqrt(n) # 母平均の95%信頼区間の上限
Copyright (C) 2016-2017 SUGINO Isamu All Rights Reserved. design by tempnate