杉野 勇 (SUGINO Isamu) お茶の水女子大学・人間発達科学専攻・応用社会学コース担当
『入門・社会統計学』サポートウェブ |
|
 第5章 2変数の関連の推定と検定
第5章 2変数の関連の推定と検定
1 積率相関係数についての推測統計
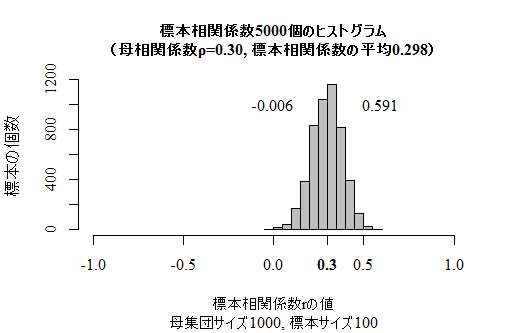
本文の標本相関係数の標本抽出分布(一部)を描くスクリプトを紹介しておこう。単回帰分析を深く理解していないと意味が分からないと思うので,解読できなくて良い。シミュレイションなので,実行するたびに少しずつ違う結果が得られる。NやR,n,timesを変えて実行してみると良い。


N <- 1000 # 母集団サイズ
R <- 0.3 # 欲しい母相関係数の値
y <- rnorm(N, mean=0, sd=1)
x <- rnorm(N, mean=0, sd=1)
slope_xy <- cor(x, y, method="pearson")*sd(y)/sd(x)
intercept_xy <- mean(y) - slope_xy*mean(x)
e <- y - (intercept_xy + slope_xy*x)
sd_x <- sqrt(sd(x)^2*(N-1)/N)
sd_e <- sqrt(sd(e)^2*(N-1)/N)
std_x <- (x-mean(x))/sd_x
std_e <- (e-mean(e))/sd_e
u <- R*std_x + sqrt(1-R^2)*std_e
sd_u <- sqrt(sd(u)^2*(N-1)/N)
## サンプリング
n <- 50 # サンプルサイズの指定
times <- 100000 # 抽出回数
corrs <- vector(length=times) # 標本相関係数を格納するヴェクトル
for (i in 1:times) {
j <- sample(N, n)
corrs[i] <- cor(std_x[j], u[j], method="pearson")
}
hist(corrs, xlim=c(-1,1),
main=sprintf("標本相関係数%d個のヒストグラム\n(母相関係数ρ=%.2f, 標本相関係数の平均%.3f)", times, R, mean(corrs)),
sub=sprintf("母集団サイズ%d, 標本サイズ%.d", N, n), cex.main=1.0,
xlab="標本相関係数rの値", ylab="標本の個数", family="serif", col="#00000040")
axis(side=1, R, font=2, family="serif")
text(c(min(corrs), max(corrs)), 1000, round(c(min(corrs), max(corrs)),3), family="serif")
timesとnの値を変えて実行したグラフを以下に示す。この場合の標本相関係数の理論的な期待値は約.2986である。R <- 0.3 # 欲しい母相関係数の値
y <- rnorm(N, mean=0, sd=1)
x <- rnorm(N, mean=0, sd=1)
slope_xy <- cor(x, y, method="pearson")*sd(y)/sd(x)
intercept_xy <- mean(y) - slope_xy*mean(x)
e <- y - (intercept_xy + slope_xy*x)
sd_x <- sqrt(sd(x)^2*(N-1)/N)
sd_e <- sqrt(sd(e)^2*(N-1)/N)
std_x <- (x-mean(x))/sd_x
std_e <- (e-mean(e))/sd_e
u <- R*std_x + sqrt(1-R^2)*std_e
sd_u <- sqrt(sd(u)^2*(N-1)/N)
## サンプリング
n <- 50 # サンプルサイズの指定
times <- 100000 # 抽出回数
corrs <- vector(length=times) # 標本相関係数を格納するヴェクトル
for (i in 1:times) {
j <- sample(N, n)
corrs[i] <- cor(std_x[j], u[j], method="pearson")
}
hist(corrs, xlim=c(-1,1),
main=sprintf("標本相関係数%d個のヒストグラム\n(母相関係数ρ=%.2f, 標本相関係数の平均%.3f)", times, R, mean(corrs)),
sub=sprintf("母集団サイズ%d, 標本サイズ%.d", N, n), cex.main=1.0,
xlab="標本相関係数rの値", ylab="標本の個数", family="serif", col="#00000040")
axis(side=1, R, font=2, family="serif")
text(c(min(corrs), max(corrs)), 1000, round(c(min(corrs), max(corrs)),3), family="serif")
1-1 積率相関係数のt検定(t-test)
標本サイズと標本相関係数から,ゼロ仮説「母相関係数=0」のt検定を行う(有意確率を表示する)スクリプトを示す。片側検定と両側検定の両方を表示しているが,両側検定での有意確率は片側検定での有意確率の2倍である。よって,両側検定で有意になる場合,同じ有意水準の片側検定では必ず有意になるが,片側検定で有意になったとしても,同じ有意水準の両側検定で有意になるとは限らない。
nやrに自由な値を設定して試してみよう。rの絶対値はもちろん1を超えてはならない。

nやrに自由な値を設定して試してみよう。rの絶対値はもちろん1を超えてはならない。
n <- 50 # 標本サイズ
r <- -.30 # 標本相関係数
t0 <- r/sqrt(1-r^2)*sqrt(n-2); t0 # 検定統計量t
pt(-1*abs(t0), n-2)+(1-pt(abs(t0), n-2)) # 両側有意確率
# 片側検定の有意確率
# 標本相関係数の符号と同じ側に棄却域を設定する
if (r < 0) prob <- pt(t0, n-2)
if (r >=0) prob <- 1-pt(t0, n-2)
prob
r <- -.30 # 標本相関係数
t0 <- r/sqrt(1-r^2)*sqrt(n-2); t0 # 検定統計量t
pt(-1*abs(t0), n-2)+(1-pt(abs(t0), n-2)) # 両側有意確率
# 片側検定の有意確率
# 標本相関係数の符号と同じ側に棄却域を設定する
if (r < 0) prob <- pt(t0, n-2)
if (r >=0) prob <- 1-pt(t0, n-2)
prob
1-2 標本サイズと有意確率
本文の表のように,n,rの幾つかの組合せに対して,95%限界値,有意確率を計算してみよう。本文よりも,限界値に対応する標本相関係数の値など少し追加してある。

上の結果を解説しよう。n=50,r=.20の場合,検定統計量tは約1.414となり,95%範囲の両端の±2.010635よりずっと中心寄りであり,両端の限界値の外側に位置する5%棄却域には入らない。即ち,「母相関係数はゼロである」とのゼロ仮説を棄却出来ない。両側有意確率は約16.4%である。このサンプルサイズで5%棄却域に入る(=ゼロ仮説が棄却できる)のは,r=.2787くらいになってからである。
r <- .20 # 標本相関係数
n <- 50 # サンプルサイズ
p0 <- .95 # 信頼水準(信頼係数)
t0 <- r/sqrt(1-r^2)*sqrt(n-2)
t0 # t検定統計量
qt((1-p0)/2, n-2); qt((1+p0)/2, n-2) # 100p%限界値
pt(-1*t0, n-2)+(1-pt(t0, n-2)) # 両側検定での有意確率
# t統計量の100p%限界値tcに対応する標本相関係数rcの値(正の値のみ)
tc <- qt((1+p0)/2, n-2)
sqrt((tc^2/(n-2))/(1+tc^2/(n-2)))
n <- 50 # サンプルサイズ
p0 <- .95 # 信頼水準(信頼係数)
t0 <- r/sqrt(1-r^2)*sqrt(n-2)
t0 # t検定統計量
qt((1-p0)/2, n-2); qt((1+p0)/2, n-2) # 100p%限界値
pt(-1*t0, n-2)+(1-pt(t0, n-2)) # 両側検定での有意確率
# t統計量の100p%限界値tcに対応する標本相関係数rcの値(正の値のみ)
tc <- qt((1+p0)/2, n-2)
sqrt((tc^2/(n-2))/(1+tc^2/(n-2)))
上の結果を解説しよう。n=50,r=.20の場合,検定統計量tは約1.414となり,95%範囲の両端の±2.010635よりずっと中心寄りであり,両端の限界値の外側に位置する5%棄却域には入らない。即ち,「母相関係数はゼロである」とのゼロ仮説を棄却出来ない。両側有意確率は約16.4%である。このサンプルサイズで5%棄却域に入る(=ゼロ仮説が棄却できる)のは,r=.2787くらいになってからである。
1-3 母相関係数の区間推定
サンプルサイズと標本相関係数が与えられた時に,信頼区間を計算する方法は,本文脚注にも書いてある通りである。フィッシャーのZ変換を行ったものはそのままZと表記する事が多いが[南風原 2002: 116],ここでは他の多くの標準正規変量と区別し易いようにあえてLと表記しておく。
 ここで,フィッシャーのZ変換を行ったものが実際に正規分布で近似できるかをシミュレイションで確かめてみよう。上の1で使用した模擬母集団とそこからのランダムサンプリングのスクリプトを利用し,多くの標本相関係数を格納したヴェクトルcorrsまで求められているとし,その続きを示す。まずは,シミュレイションで得られた標本相関係数のヒストグラムを再確認しておこう(シミュレイションなので実行するたびに少しずつ異なる結果になる)。
ここで,フィッシャーのZ変換を行ったものが実際に正規分布で近似できるかをシミュレイションで確かめてみよう。上の1で使用した模擬母集団とそこからのランダムサンプリングのスクリプトを利用し,多くの標本相関係数を格納したヴェクトルcorrsまで求められているとし,その続きを示す。まずは,シミュレイションで得られた標本相関係数のヒストグラムを再確認しておこう(シミュレイションなので実行するたびに少しずつ異なる結果になる)。
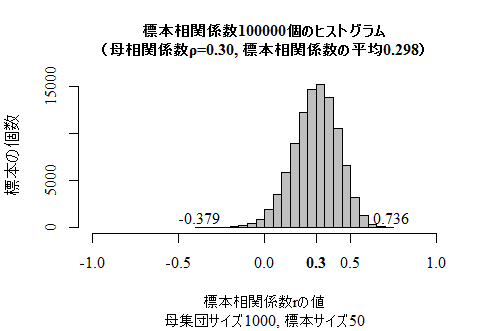
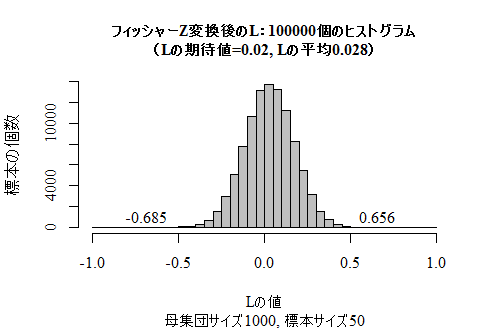
確かに,かなり正規分布に近付いている様子が分かる。
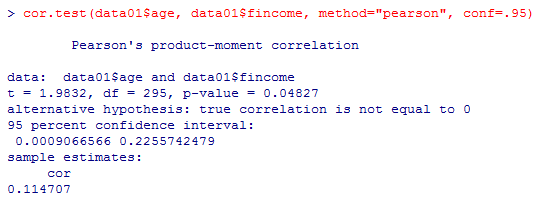
本文で「t検定の結果と95%信頼区間,標本相関係数の値は,Rのcor.test(x, y, method=”pearson”)によってすべて出力される。」と書いたので,その出力例を以下に挙げておく。
r <- .30
n <- 50
lwr <- 1/2*log((1+r)/(1-r))-1.96/sqrt(n-3) # Lの信頼区間下限
upr <- 1/2*log((1+r)/(1-r))+1.96/sqrt(n-3) # Lの信頼区間上限
lwr; upr
# 逆変換して相関係数の値に戻す
rhoL <- (exp(2*lwr)-1)/(exp(2*lwr)+1)
rhoU <- (exp(2*upr)-1)/(exp(2*upr)+1)
rhoL; rhoU
n <- 50
lwr <- 1/2*log((1+r)/(1-r))-1.96/sqrt(n-3) # Lの信頼区間下限
upr <- 1/2*log((1+r)/(1-r))+1.96/sqrt(n-3) # Lの信頼区間上限
lwr; upr
# 逆変換して相関係数の値に戻す
rhoL <- (exp(2*lwr)-1)/(exp(2*lwr)+1)
rhoU <- (exp(2*upr)-1)/(exp(2*upr)+1)
rhoL; rhoU
ここで,フィッシャーのZ変換を行ったものが実際に正規分布で近似できるかをシミュレイションで確かめてみよう。上の1で使用した模擬母集団とそこからのランダムサンプリングのスクリプトを利用し,多くの標本相関係数を格納したヴェクトルcorrsまで求められているとし,その続きを示す。まずは,シミュレイションで得られた標本相関係数のヒストグラムを再確認しておこう(シミュレイションなので実行するたびに少しずつ異なる結果になる)。
L <- 1/2*log((1+corrs)/(1-corrs))-1.96/sqrt(n-3) # Lの信頼区間下限
muL <- 1/2*log((1+R)/(1-R))-1.96/sqrt(n-3) # Lの期待値
hist(L, xlim=c(-1,1), breaks=seq(-1, 1, by=.05),
main=sprintf("フィッシャーZ変換後のL:%d個のヒストグラム\n(Lの期待値=%.2f, Lの平均%.3f)", times, muL, mean(L)),
sub=sprintf("母集団サイズ%d, 標本サイズ%.d", N, n), cex.main=1.0,
xlab="Lの値", ylab="標本の個数", family="serif", col="#00000040")
text(c(min(L), max(L)), 1000, round(c(min(L), max(L)),3), family="serif")
muL <- 1/2*log((1+R)/(1-R))-1.96/sqrt(n-3) # Lの期待値
hist(L, xlim=c(-1,1), breaks=seq(-1, 1, by=.05),
main=sprintf("フィッシャーZ変換後のL:%d個のヒストグラム\n(Lの期待値=%.2f, Lの平均%.3f)", times, muL, mean(L)),
sub=sprintf("母集団サイズ%d, 標本サイズ%.d", N, n), cex.main=1.0,
xlab="Lの値", ylab="標本の個数", family="serif", col="#00000040")
text(c(min(L), max(L)), 1000, round(c(min(L), max(L)),3), family="serif")
確かに,かなり正規分布に近付いている様子が分かる。
本文で「t検定の結果と95%信頼区間,標本相関係数の値は,Rのcor.test(x, y, method=”pearson”)によってすべて出力される。」と書いたので,その出力例を以下に挙げておく。
data01 <- read.csv("practice.csv") # working directoryにデータファイルを置いておく
names(data01)
cor.test(data01$age, data01$fincome, method="pearson", conf=.95)
names(data01)
cor.test(data01$age, data01$fincome, method="pearson", conf=.95)
2-1 カイ二乗分布(chi-squared distribution)
本文の,「自由度1,4,6,8,9,12のカイ二乗分布」のグラフを描くスクリプトは以下である。


x <- seq(0, end <- 20, by=0.1)
df0 <- 1
# 最初に自由度1で基本のグラフを描く
plot(x, dchisq(x, df=df0), type="l", ylim=c(0, .20),
bty="n", xlab="カイ二乗変量", ylab="確率密度", las=1,
main="自由度1,4,6,8,9,12のカイ二乗分布",
family="serif")
for (df1 in c(4, 6, 8, 9, 12)) {
par(new=T) # グラフを重ね描きする為のコマンド
plot(x, dchisq(x, df=df1), type="l", ylim=c(0, .20),
bty="n", axes=F, ylab="", xlab="", lwd=1+df1/5,
lty=floor(df1/2))
}
次の,棄却域を塗り潰したカイ二乗分布のグラフは下記。自由度と有意水準は変更する事が出来る。df0 <- 1
# 最初に自由度1で基本のグラフを描く
plot(x, dchisq(x, df=df0), type="l", ylim=c(0, .20),
bty="n", xlab="カイ二乗変量", ylab="確率密度", las=1,
main="自由度1,4,6,8,9,12のカイ二乗分布",
family="serif")
for (df1 in c(4, 6, 8, 9, 12)) {
par(new=T) # グラフを重ね描きする為のコマンド
plot(x, dchisq(x, df=df1), type="l", ylim=c(0, .20),
bty="n", axes=F, ylab="", xlab="", lwd=1+df1/5,
lty=floor(df1/2))
}
df0 <- 6 # 自由度を指定する
p0 <- .95 # 有意水準を指定する
x <- seq(0, end <- 20, by=0.1) # endはx軸の右端
plot(x, dchisq(x, df=df0), type="l", ylim=c(0, .20),
bty="n", xlab="カイ二乗変量", ylab="確率密度", las=1,
main=paste("自由度", df0, "のカイ二乗分布の", (1-p0)*100, "%棄却域"),
family="serif", cex.main=1)
rej <- seq(qchisq(p0, df0), end, by=.1) # 棄却域を設定
segments(rej, 0, rej, dchisq(rej, df0))
segments(min(rej), 0, max(rej), 0, lwd=3)
axis(side=1, at=round(min(rej),1), las=2, font=2, family="serif")
実際のデータ(演習用データ)から分割表のカイ二乗検定を行うには下記の様にする。欠損値処理が入っているので少し手間がかかっている。ついでにクラメールのVやファイ係数の計算もしておこう。p0 <- .95 # 有意水準を指定する
x <- seq(0, end <- 20, by=0.1) # endはx軸の右端
plot(x, dchisq(x, df=df0), type="l", ylim=c(0, .20),
bty="n", xlab="カイ二乗変量", ylab="確率密度", las=1,
main=paste("自由度", df0, "のカイ二乗分布の", (1-p0)*100, "%棄却域"),
family="serif", cex.main=1)
rej <- seq(qchisq(p0, df0), end, by=.1) # 棄却域を設定
segments(rej, 0, rej, dchisq(rej, df0))
segments(min(rej), 0, max(rej), 0, lwd=3)
axis(side=1, at=round(min(rej),1), las=2, font=2, family="serif")
data01 <- read.csv("practice.csv") # working directoryにデータファイルを置いておく
names(data01)
data$q1601b <- data$q1601 # q1601をq1601bに複製して,
data$q1601b[data$q1601 ==6] <- NA # 欠損値処理をする
table1 <- table("性別"=data$sex, "機会平等なら格差やむをえない"=data$q1601b)
dimnames(table1)[[1]] <- c("男性", "女性")
dimnames(table1)[[2]] <- c("そう思う", "どち…思う", "どちらとも", "どち…思わない", "そう思わない")
table1 # 分割表
ch <- chisq.test(table1); ch # カイ二乗検定の結果
names(ch)
ch$residual # 標準化残差
ch$stdres # 調整済み標準化残差
V <- sqrt(ch$statistic/min(dim(table1)-1)/sum(table1))
phi <- sqrt(ch$statistic/sum(table1))
names(V) <- "Cramer's V"; names(phi) <- "phi coefficient"
V; phi
names(data01)
data$q1601b <- data$q1601 # q1601をq1601bに複製して,
data$q1601b[data$q1601 ==6] <- NA # 欠損値処理をする
table1 <- table("性別"=data$sex, "機会平等なら格差やむをえない"=data$q1601b)
dimnames(table1)[[1]] <- c("男性", "女性")
dimnames(table1)[[2]] <- c("そう思う", "どち…思う", "どちらとも", "どち…思わない", "そう思わない")
table1 # 分割表
ch <- chisq.test(table1); ch # カイ二乗検定の結果
names(ch)
ch$residual # 標準化残差
ch$stdres # 調整済み標準化残差
V <- sqrt(ch$statistic/min(dim(table1)-1)/sum(table1))
phi <- sqrt(ch$statistic/sum(table1))
names(V) <- "Cramer's V"; names(phi) <- "phi coefficient"
V; phi
2-2 カイ二乗検定の前提条件
分割表の独立性についてのカイ二乗検定において,検定統計量がカイ二乗分布で近似できる条件は,各セルの度数がポワソン分布に従い,そのポワソン分布が正規分布で近似できるということである。本文中の,二つのポワソン分布を重ね描きするスクリプトは下記である。
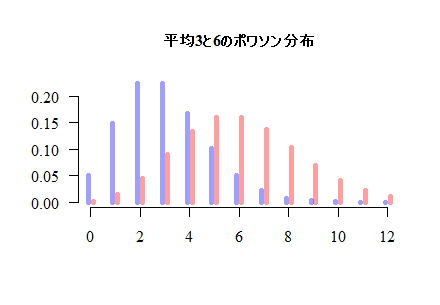
x1 <- c(0:15)
lambda1 <- 2
lambda2 <- 5
plot(x1, dpois(x1, lambda1), type="h", bty="n",
lwd=5, col="#00000060", xlab="", ylab="",
las=1, family="serif", cex.main=1.0, ylim=c(0, .3),
main=sprintf("平均%dと%dのポワソン分布", lambda1, lambda2))
par(new=T)
plot(x1, dpois(x1, lambda2), type="b", bty="n", axes=F,
lwd=1, col="#000000", xlab="", ylab="",
las=1, family="serif", ylim=c(0, .3))
少し改変したスクリプトとその結果も例示しておこう。lambda1 <- 2
lambda2 <- 5
plot(x1, dpois(x1, lambda1), type="h", bty="n",
lwd=5, col="#00000060", xlab="", ylab="",
las=1, family="serif", cex.main=1.0, ylim=c(0, .3),
main=sprintf("平均%dと%dのポワソン分布", lambda1, lambda2))
par(new=T)
plot(x1, dpois(x1, lambda2), type="b", bty="n", axes=F,
lwd=1, col="#000000", xlab="", ylab="",
las=1, family="serif", ylim=c(0, .3))
lambda <- c(3, 6) # 二つのポワソン分布の平均をヴェクトルで指定
x1 <- c(0: (max(lambda)*2))
plot(x1-.1, dpois(x1, min(lambda)), type="h", bty="n", xlim=range(x1),
lwd=5, col="#0000ff60", xlab="", ylab="", las=1, family="serif",
cex.main=1.0, ylim=c(0, Y <- dpois(min(lambda), min(lambda))),
main=sprintf("平均%dと%dのポワソン分布", min(lambda), max(lambda)))
par(new=T)
plot(x1+.1, dpois(x1, max(lambda)), type="h", bty="n", axes=F,
lwd=5, col="#ff000060", xlab="", ylab="", xlim=range(x1),
las=1, family="serif", ylim=c(0, Y))
x1 <- c(0: (max(lambda)*2))
plot(x1-.1, dpois(x1, min(lambda)), type="h", bty="n", xlim=range(x1),
lwd=5, col="#0000ff60", xlab="", ylab="", las=1, family="serif",
cex.main=1.0, ylim=c(0, Y <- dpois(min(lambda), min(lambda))),
main=sprintf("平均%dと%dのポワソン分布", min(lambda), max(lambda)))
par(new=T)
plot(x1+.1, dpois(x1, max(lambda)), type="h", bty="n", axes=F,
lwd=5, col="#ff000060", xlab="", ylab="", xlim=range(x1),
las=1, family="serif", ylim=c(0, Y))
2-3 データに対するモデルの適合度検定(Goodness of Fit test)
社会学では,「カイ二乗検定」と云うと「独立性の検定」と同一視する傾向があるが,これはデータに対して「2変数独立モデル」が適合するかどうかを検定していると考えれば,「適合度検定」の一種であるとも言える。カイ二乗統計量は社会統計学のより発展的な場面で色々と登場してくる事になるが,いずれも「データとモデルのズレ」を表す統計量として統一的に考えるのが良い。ここでは,chisq.test( )関数を使用した最も単純な適合度の検定を紹介しよう。
少人数の無作為標本に対して,「夫は外で働き,妻は家庭を守るべきである」という考え方について,そう思うかそう思わないか(性別役割分業意識)を,「そう思う/どちらかと言えばそう思う/どちらかと言えばそう思わない/そう思わない」の4件法で尋ねた結果,それぞれ5人,8人,15人,12人であったとする。
「この結果では偶然ばらついたが,本当はどの回答も等確率で出現する」,つまり同じ比率ずつ分布していると仮定した時,その等比率(もしくは等確率)モデルと実際のデータのズレが偶然の範囲内と言えるかどうかをカイ二乗検定する事が出来るが,これが最も単純な適合度検定である。

等確率だとしたら全ての選択肢が10人ずつに選ばれる筈であり,実際の結果はそこからカイ二乗統計量にして5.8ずれているが,これは自由度3(=カテゴリ数4 - 1)のχ2分布に近似的に従うと考えられる。自由度3のχ2分布で5.8以上の範囲の面積(確率)は約12.2%ある。つまり本当は(母集団では)等比率で分布しているのにたまたまこの様な無作為標本が得られることは10回に1回より多く起こると考えられ,特に不自然であるとは言えないので,「本当は(母集団では)等比率である」と云うゼロ仮説は棄却出来ない。
これを,等比率モデルの適合度は悪くないと考えるのが適合度検定である。「モデルがデータに適合している」と云うゼロ仮説が棄却されなかった事をもって「モデルは正しい」と解釈する事は統計の誤用であるとする立場からするとこの適合度検定の考え方には疑問や批判もある。その立場からすると,「等比率モデルは間違っていると自信をもって言えるだけの証拠が無かっただけで,等比率モデルが正しいと言える訳ではなく,精々判断が保留されるだけである」となる。この辺りは研究者によって考え方が違ってくるかも知れない。
上の例では,適合度検定と独立性の検定の違いがいまいちはっきりしないかも知れないので,少し違った例を示そう。
上では等比率仮説は棄却されないが,流石に現在の日本ではこの質問に対して4つの選択肢で同じ比率ずつ意見が分布しているとは考えられない。本当の意見分布を2:3:4:5であると仮定して,データと齟齬を来すかどうかを検討しよう。Rスクリプトと結果は以下の通りである。chisq.test( )関数のオプションp=で,それぞれのカテゴリの生起確率を指定する点だけが異なる。

結果,性別役割分業に否定的な人ほど数が多いと云うこのモデルも有意性検定で棄却されず,データとの適合は悪くないと云う結果になった。むしろズレの指標は等比率モデルよりも遥かに小さく,有意確率もずっと高い。いずれのモデルも(そして他にも多くの可能なモデルが)データに適合する(適合しないとは言い切れない)と云う結果になる。そのいずれかが正しいと証明される訳でも無く,カイ二乗統計量や有意確率の値からいずれかが「より正しい」と言えるかどうかにも議論がある。
適合度検定と考えられるものには,第6章の基礎1-1や第7章基礎1-5の等分散性の検定(各群の母分散が等しいモデルが適合するかどうか),第6章発展1の正規性の検定(変数の分布が正規分布に適合するかどうか)がある。それ以外にも,第11章発展1-1の構造方程式モデリング(SEM; Structural Equation Modelling)では,設定したモデルの適合度がカイ二乗検定される(それ以外に,GFI[Goodness-of-Fit Index]を始めとして幾つかの適合度指標が算出されるが,GFIらについては統計的検定がされる訳では無い)。第12章基礎1-4では,2項ロジスティック回帰分析に対する適合度検定としてHosmer-Lemeshow検定を紹介した。第12章発展1のログリニア・モデル(log-linear model)も「モデルがデータに適合するか」を重視した分析手法であると言える。
適合度検定の多くは,統計的検定一般がそうである様に,サンプルサイズが大きいと有意になり易い。大標本では「僅かなズレでも敏感に検出してしまう」のである。適合度検定で統計的に有意になると云う事は,「モデルがデータに適合している」と仮定すると(ゼロ仮説),ズレの指標が偶然とは思えない程に大きくなるので,ゼロ仮説は棄却されると云う事であり,つまり「このモデルはデータには適合しない」と云う結論になるので,モデルが当てはまる事を期待していた分析者にとっては嬉しい結果ではない事も多いだろう。
少人数の無作為標本に対して,「夫は外で働き,妻は家庭を守るべきである」という考え方について,そう思うかそう思わないか(性別役割分業意識)を,「そう思う/どちらかと言えばそう思う/どちらかと言えばそう思わない/そう思わない」の4件法で尋ねた結果,それぞれ5人,8人,15人,12人であったとする。
「この結果では偶然ばらついたが,本当はどの回答も等確率で出現する」,つまり同じ比率ずつ分布していると仮定した時,その等比率(もしくは等確率)モデルと実際のデータのズレが偶然の範囲内と言えるかどうかをカイ二乗検定する事が出来るが,これが最も単純な適合度検定である。
# 適合度のカイ二乗検定1: 等比率(等確率)モデルがデータに適合するか
x <- c(5, 8, 15, 12) # 回答の結果のヴェクトル
sum(x) # 一応総人数を確認しておく
ch01 <- chisq.test(x); ch01 # 適合度のカイ二乗検定
ch01$expected # 等比率だとした場合の期待度数
x <- c(5, 8, 15, 12) # 回答の結果のヴェクトル
sum(x) # 一応総人数を確認しておく
ch01 <- chisq.test(x); ch01 # 適合度のカイ二乗検定
ch01$expected # 等比率だとした場合の期待度数
等確率だとしたら全ての選択肢が10人ずつに選ばれる筈であり,実際の結果はそこからカイ二乗統計量にして5.8ずれているが,これは自由度3(=カテゴリ数4 - 1)のχ2分布に近似的に従うと考えられる。自由度3のχ2分布で5.8以上の範囲の面積(確率)は約12.2%ある。つまり本当は(母集団では)等比率で分布しているのにたまたまこの様な無作為標本が得られることは10回に1回より多く起こると考えられ,特に不自然であるとは言えないので,「本当は(母集団では)等比率である」と云うゼロ仮説は棄却出来ない。
これを,等比率モデルの適合度は悪くないと考えるのが適合度検定である。「モデルがデータに適合している」と云うゼロ仮説が棄却されなかった事をもって「モデルは正しい」と解釈する事は統計の誤用であるとする立場からするとこの適合度検定の考え方には疑問や批判もある。その立場からすると,「等比率モデルは間違っていると自信をもって言えるだけの証拠が無かっただけで,等比率モデルが正しいと言える訳ではなく,精々判断が保留されるだけである」となる。この辺りは研究者によって考え方が違ってくるかも知れない。
上の例では,適合度検定と独立性の検定の違いがいまいちはっきりしないかも知れないので,少し違った例を示そう。
上では等比率仮説は棄却されないが,流石に現在の日本ではこの質問に対して4つの選択肢で同じ比率ずつ意見が分布しているとは考えられない。本当の意見分布を2:3:4:5であると仮定して,データと齟齬を来すかどうかを検討しよう。Rスクリプトと結果は以下の通りである。chisq.test( )関数のオプションp=で,それぞれのカテゴリの生起確率を指定する点だけが異なる。
ch02 <- chisq.test(x, p=c(2, 3, 4, 5)/14)
ch02
ch02$expected
ch02
ch02$expected
結果,性別役割分業に否定的な人ほど数が多いと云うこのモデルも有意性検定で棄却されず,データとの適合は悪くないと云う結果になった。むしろズレの指標は等比率モデルよりも遥かに小さく,有意確率もずっと高い。いずれのモデルも(そして他にも多くの可能なモデルが)データに適合する(適合しないとは言い切れない)と云う結果になる。そのいずれかが正しいと証明される訳でも無く,カイ二乗統計量や有意確率の値からいずれかが「より正しい」と言えるかどうかにも議論がある。
適合度検定と考えられるものには,第6章の基礎1-1や第7章基礎1-5の等分散性の検定(各群の母分散が等しいモデルが適合するかどうか),第6章発展1の正規性の検定(変数の分布が正規分布に適合するかどうか)がある。それ以外にも,第11章発展1-1の構造方程式モデリング(SEM; Structural Equation Modelling)では,設定したモデルの適合度がカイ二乗検定される(それ以外に,GFI[Goodness-of-Fit Index]を始めとして幾つかの適合度指標が算出されるが,GFIらについては統計的検定がされる訳では無い)。第12章基礎1-4では,2項ロジスティック回帰分析に対する適合度検定としてHosmer-Lemeshow検定を紹介した。第12章発展1のログリニア・モデル(log-linear model)も「モデルがデータに適合するか」を重視した分析手法であると言える。
適合度検定の多くは,統計的検定一般がそうである様に,サンプルサイズが大きいと有意になり易い。大標本では「僅かなズレでも敏感に検出してしまう」のである。適合度検定で統計的に有意になると云う事は,「モデルがデータに適合している」と仮定すると(ゼロ仮説),ズレの指標が偶然とは思えない程に大きくなるので,ゼロ仮説は棄却されると云う事であり,つまり「このモデルはデータには適合しない」と云う結論になるので,モデルが当てはまる事を期待していた分析者にとっては嬉しい結果ではない事も多いだろう。
発展1-1 分割表の残差分析(analysis of residual)
上の2-1でデータフレイムdata01,その中の変数data01$sex,data01$q1601b,分割表table1などを既に準備済みであるので,それを利用して調整済み標準化残差(ハーバーマン残差)を表示したりモザイクプロットを表示したりしてみよう。

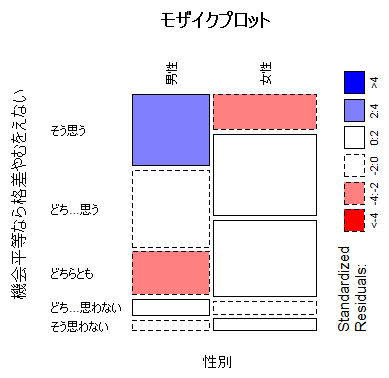
table1 # 分割表
ch <- chisq.test(table1); ch # カイ二乗検定の結果
names(ch)
ch$"stdres"
round(ch$"stdres", 3) # 小数第三位までに四捨五入して表示
mosaicplot(table1, type="pearson", shade=T,
main="モザイクプロット", las=2)
ch <- chisq.test(table1); ch # カイ二乗検定の結果
names(ch)
ch$"stdres"
round(ch$"stdres", 3) # 小数第三位までに四捨五入して表示
mosaicplot(table1, type="pearson", shade=T,
main="モザイクプロット", las=2)
発展1-2 イェーツの連続性修正(Yates' correction for continuity)と
フィッシャーの正確検定(Fisher's exact test)
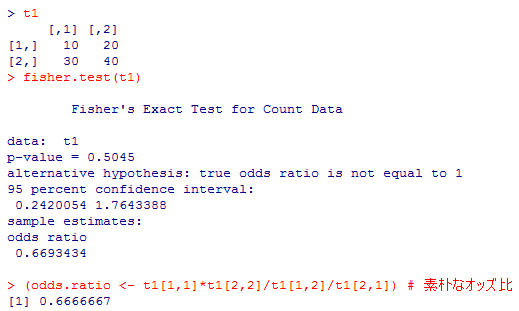
模擬的に2行2列の分割表を作成し,カイ二乗検定の関数を適用してみよう。correct=というオプションを省略した場合,TRUEにした場合,FALSEにした場合をよく比較して欲しい。2行2列分割表ではcorrect=を省略すると自動的にcorrect=TRUEとなる。行数か列数が2を超えると連続修正は存在しない。
 同じ分割表に対してフィッシャーの正確検定を行ってみる。fisher.test( )関数の出力するodds ratioは注意が必要なので,通常のオッズ比を計算するコマンドも最後に付け加えてある。
同じ分割表に対してフィッシャーの正確検定を行ってみる。fisher.test( )関数の出力するodds ratioは注意が必要なので,通常のオッズ比を計算するコマンドも最後に付け加えてある。
演習用データの学歴(3行)×性別役割分業意識(4列)の分割表にカイ二乗検定や正確検定を行ってみよう。2行2列ではないのでオッズ比は計算されない。

t1 <- matrix(c(10, 30, 20, 40), ncol=2); t1
chisq.test(t1) # デフォルトでのカイ二乗検定
chisq.test(t1, correct=T) # 連続性修正のオプションをTRUE
chisq.test(t1, correct=F) # 連続性修正のオプションをFALSE
chisq.test(t1) # デフォルトでのカイ二乗検定
chisq.test(t1, correct=T) # 連続性修正のオプションをTRUE
chisq.test(t1, correct=F) # 連続性修正のオプションをFALSE
同じ分割表に対してフィッシャーの正確検定を行ってみる。fisher.test( )関数の出力するodds ratioは注意が必要なので,通常のオッズ比を計算するコマンドも最後に付け加えてある。
t1
fisher.test(t1)
(odds.ratio <- t1[1,1]*t1[2,2]/t1[1,2]/t1[2,1]) # 素朴なオッズ比
fisher.test(t1)
(odds.ratio <- t1[1,1]*t1[2,2]/t1[1,2]/t1[2,1]) # 素朴なオッズ比
演習用データの学歴(3行)×性別役割分業意識(4列)の分割表にカイ二乗検定や正確検定を行ってみよう。2行2列ではないのでオッズ比は計算されない。
table1 <- table("学歴3区分"=data01$edu2, "性別役割分業"=data01$q1900)
dimnames(table1)[[1]] <- c("1 初等", "2 中等", "3 高等")
dimnames(table1)[[2]] <- c("1 そう思う", "2 どち…思う", "3 どち…思わない", "4 思わない")
table1 # まず分割表(特に行変数と列変数)を確認する。
chisq.test(table1) # カイ二乗検定
fisher.test(table1) # 正確検定
fisher.test(table1, simulate.p.value=T) # 正確検定(近似計算)
dimnames(table1)[[1]] <- c("1 初等", "2 中等", "3 高等")
dimnames(table1)[[2]] <- c("1 そう思う", "2 どち…思う", "3 どち…思わない", "4 思わない")
table1 # まず分割表(特に行変数と列変数)を確認する。
chisq.test(table1) # カイ二乗検定
fisher.test(table1) # 正確検定
fisher.test(table1, simulate.p.value=T) # 正確検定(近似計算)
第5章【練習問題】の解答
1)の答え:

有意確率は18.3%程度であり,有意水準を1%にしようが5%にしようが10%にしようが有意にはならない。つまりゼロ仮説は棄却出来ない。片側検定として考えるなら有意水準を半分にすればよいが,それでも5%では有意にならない。
2)の答え:

両側5%検定で有意になり,ゼロ仮説は棄却される。1)とは標本相関係数の値は同じであるが,標本サイズが2倍以上になっており,弱い関連に対してより敏感に検出出来る様になっている。
3)の答え:
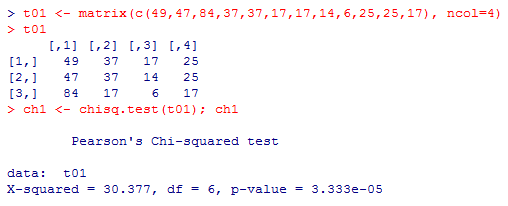
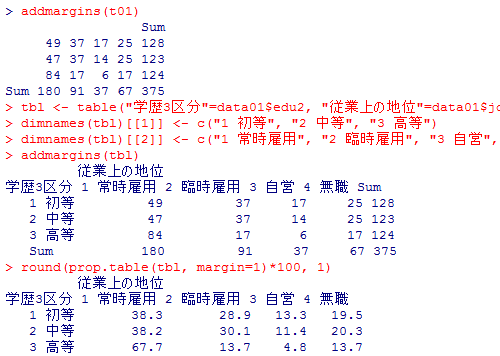
高度に有意となり,母集団では独立であるとのゼロ仮説は棄却される。
独立性が否定されたので,行比率や列比率を計算して,どの様な偏りがあるのかを確認しておく。
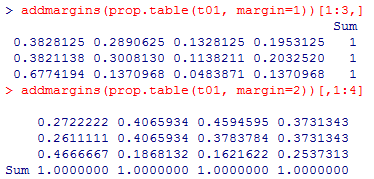
4)の答え:
カイ二乗検定のみならず正確検定も行っておこう。

いずれにしても有意にはならず,独立モデルは棄却出来ない。3)と比較すると,分割表の行数・列数は等しく,したがって自由度も同じである。各セルの度数を一律に三分の一にしているので,行比率の表もほぼ同じである。
しかしカイ二乗統計量の値は,30.377と9.5046と3倍余り異なり,その結果検定結果は1%有意と10%でも有意でないと云う様に対照的である。サンプルサイズが小さいと,同じ様な関連が「偶然に過ぎないかも知れない」と見做されてしまうのである。
5)の答え:
調整済み標準化残差(ハーバーマン残差)が標準正規分布に近似的に従う事を利用する。
調整済み標準化残差は,カイ二乗検定の結果を格納したオブジェクトのstdresで取り出せる。
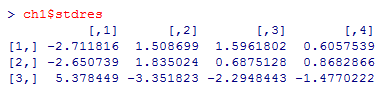
有意水準を両側5%とすると,絶対値が1.96を超えているセルが,有意に独立モデルから乖離しているセルであり,[3行, 1列]が期待値より有意に,かなり多い。[3, 2], [3, 3], [1, 1], [1, 2]は期待値より有意に少ない。つまり,3行1列のセルに著しく集中している事が分かる。
実はこの分割表は,演習用データの学歴3区分と従業上の地位4区分のものであり,高学歴者ほど常時雇用者が多いと云う結果を示しているのである。
r <- .25 # 標本相関係数
n <- 30 # サンプルサイズ
p0 <- .95 # 信頼水準(信頼係数)
t0 <- r/sqrt(1-r^2)*sqrt(n-2)
t0 # t検定統計量
qt((1-p0)/2, n-2); qt((1+p0)/2, n-2) # 100p%限界値
pt(-1*t0, n-2)+(1-pt(t0, n-2)) # 両側検定での有意確率
n <- 30 # サンプルサイズ
p0 <- .95 # 信頼水準(信頼係数)
t0 <- r/sqrt(1-r^2)*sqrt(n-2)
t0 # t検定統計量
qt((1-p0)/2, n-2); qt((1+p0)/2, n-2) # 100p%限界値
pt(-1*t0, n-2)+(1-pt(t0, n-2)) # 両側検定での有意確率
有意確率は18.3%程度であり,有意水準を1%にしようが5%にしようが10%にしようが有意にはならない。つまりゼロ仮説は棄却出来ない。片側検定として考えるなら有意水準を半分にすればよいが,それでも5%では有意にならない。
2)の答え:
両側5%検定で有意になり,ゼロ仮説は棄却される。1)とは標本相関係数の値は同じであるが,標本サイズが2倍以上になっており,弱い関連に対してより敏感に検出出来る様になっている。
3)の答え:
t01 <- matrix(c(49,47,84,37,37,17,17,14,6,25,25,17), ncol=4)
t01
ch1 <- chisq.test(t01); ch1
t01
ch1 <- chisq.test(t01); ch1
高度に有意となり,母集団では独立であるとのゼロ仮説は棄却される。
独立性が否定されたので,行比率や列比率を計算して,どの様な偏りがあるのかを確認しておく。
addmargins(prop.table(t01, margin=1))[1:3,]
addmargins(prop.table(t01, margin=2))[,1:4]
addmargins(prop.table(t01, margin=2))[,1:4]
4)の答え:
カイ二乗検定のみならず正確検定も行っておこう。
t01s <- round(t01/3, 0); t01s
chisq.test(t01s)
fisher.test(t01s)
addmargins(prop.table(t01s, margin=1))[1:3,]
chisq.test(t01s)
fisher.test(t01s)
addmargins(prop.table(t01s, margin=1))[1:3,]
いずれにしても有意にはならず,独立モデルは棄却出来ない。3)と比較すると,分割表の行数・列数は等しく,したがって自由度も同じである。各セルの度数を一律に三分の一にしているので,行比率の表もほぼ同じである。
しかしカイ二乗統計量の値は,30.377と9.5046と3倍余り異なり,その結果検定結果は1%有意と10%でも有意でないと云う様に対照的である。サンプルサイズが小さいと,同じ様な関連が「偶然に過ぎないかも知れない」と見做されてしまうのである。
5)の答え:
調整済み標準化残差(ハーバーマン残差)が標準正規分布に近似的に従う事を利用する。
調整済み標準化残差は,カイ二乗検定の結果を格納したオブジェクトのstdresで取り出せる。
有意水準を両側5%とすると,絶対値が1.96を超えているセルが,有意に独立モデルから乖離しているセルであり,[3行, 1列]が期待値より有意に,かなり多い。[3, 2], [3, 3], [1, 1], [1, 2]は期待値より有意に少ない。つまり,3行1列のセルに著しく集中している事が分かる。
実はこの分割表は,演習用データの学歴3区分と従業上の地位4区分のものであり,高学歴者ほど常時雇用者が多いと云う結果を示しているのである。
ウェブ増補1 xtabs( )関数による分割表の作成
第2章と第5章を中心として,本書では分割表を作成する為に table( )関数を使用しているが,他によく使用される関数として,xtabs( )があるのでここで補っておく。
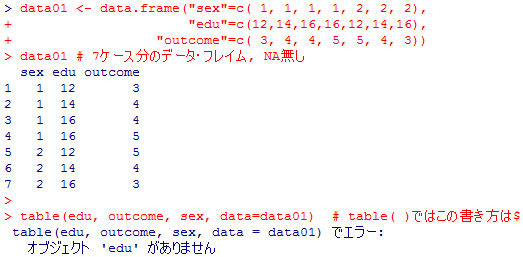
コマンドの文法と出力スタイルの両方を見比べてみよう。


この限りでは,特に重回帰分析(一般線型モデル)などに慣れている人ほど,xtabs( )の方を好むだろう。出力の表記だけをとってもxtabs( )の方がやや親切である。




NAの処理は,xtabs( )の方が何だか面倒である。


逆に,その様なFreq変数(変数名は別でも良い)を持つデータ・フレイムから,その度数によって重み付けを行った分割表を作成する事も xtabs( )によって可能になる。


これを利用すると,単に度数で重みを付けるだけでなく,サンプルの歪みの補正にしばしば使われる重み付け(ウェイト付け)を行う事も出来る。原理的には,重回帰分析などのウェイト付けと同じである。ウェイト付けを行わない場合と行った場合では,そもそも分布が違ったものになるので,分析結果も異なり得る。


分割表の基本
まずは7ケース分のデータ・フレイムdata01を作成してから,table( )とxtabs( )で三元分割表を作成してみる。その後,ftable( )を利用して三元分割表を見易くする。コマンドの文法と出力スタイルの両方を見比べてみよう。
data01 <- data.frame("sex"=c( 1, 1, 1, 1, 2, 2, 2),
"edu"=c(12,14,16,16,12,14,16),
"outcome"=c( 3, 4, 4, 5, 5, 4, 3))
data01 # 7ケース分のデータ・フレイム, NA無し
table(edu, outcome, sex, data=data01) # table( )ではこの書き方はNG
table(data01$edu, data01$outcome, data01$sex)
# xtabs( )での書き方. table( )よりも若干親切な出力表示と,lm( )に似た構文.
xtabs(~ edu + outcome + sex, data=data01)
# 三元分割表をftableで表示するには,変数の順序に注意
ftable(table(data01$edu, data01$outcome, data01$sex))
ftable(table(data01$sex, data01$edu, data01$outcome))
ftable(xtabs(~ edu + outcome + sex, data=data01))
"edu"=c(12,14,16,16,12,14,16),
"outcome"=c( 3, 4, 4, 5, 5, 4, 3))
data01 # 7ケース分のデータ・フレイム, NA無し
table(edu, outcome, sex, data=data01) # table( )ではこの書き方はNG
table(data01$edu, data01$outcome, data01$sex)
# xtabs( )での書き方. table( )よりも若干親切な出力表示と,lm( )に似た構文.
xtabs(~ edu + outcome + sex, data=data01)
# 三元分割表をftableで表示するには,変数の順序に注意
ftable(table(data01$edu, data01$outcome, data01$sex))
ftable(table(data01$sex, data01$edu, data01$outcome))
ftable(xtabs(~ edu + outcome + sex, data=data01))
この限りでは,特に重回帰分析(一般線型モデル)などに慣れている人ほど,xtabs( )の方を好むだろう。出力の表記だけをとってもxtabs( )の方がやや親切である。
NAの処理
実際の調査データ分析では,欠損値(欠測missing)の処理が必須である。この点も違いがあるので比べておこう。
data02 <- data.frame("sex"=c( 1, 1, 1,NA, 2, 2, 2),
"edu"=c(12,14,NA,16,12,14,16),
"outcome"=c( 3, 4, 4, 5, 5,NA, 3))
data02 # 7ケース分のデータ・フレイム, NA有り
table(data02$edu, data02$outcome, data02$sex)
xtabs(~ edu + outcome + sex, data=data02)
table(data02$edu, data02$outcome, data02$sex, useNA="ifany")
xtabs(~ edu + outcome + sex, data=data02, na.action=na.pass, exclude=NULL)
ftable(table(data02$edu, data02$outcome, data02$sex, useNA="ifany"))
ftable(xtabs(~ edu + outcome + sex, data=data02, na.action=na.pass, exclude=NULL))
"edu"=c(12,14,NA,16,12,14,16),
"outcome"=c( 3, 4, 4, 5, 5,NA, 3))
data02 # 7ケース分のデータ・フレイム, NA有り
table(data02$edu, data02$outcome, data02$sex)
xtabs(~ edu + outcome + sex, data=data02)
table(data02$edu, data02$outcome, data02$sex, useNA="ifany")
xtabs(~ edu + outcome + sex, data=data02, na.action=na.pass, exclude=NULL)
ftable(table(data02$edu, data02$outcome, data02$sex, useNA="ifany"))
ftable(xtabs(~ edu + outcome + sex, data=data02, na.action=na.pass, exclude=NULL))
NAの処理は,xtabs( )の方が何だか面倒である。
データ・フレイムへの(逆)変換
分割表からデータ・フレイムへの変換(逆変換?)を行う関数,as.data.frame.table( )があるが,これを使用する場合には,table( )の結果よりもxtabs( )の結果の方が便利である。上のdata01を使って実際に示してみるので,どう云う事か違いをよく見比べて読み取って欲しい。
t1 <- table(data01$edu, data01$outcome, data01$sex); t1
xt1 <- xtabs(~ edu + outcome + sex, data=data01); xt1
as.data.frame.table(t1) # データフレイムに逆変換
as.data.frame.table(xt1) # データフレイムに逆変換
xt1 <- xtabs(~ edu + outcome + sex, data=data01); xt1
as.data.frame.table(t1) # データフレイムに逆変換
as.data.frame.table(xt1) # データフレイムに逆変換
ウェイト付け
上のas.data.frame.table( )関数の結果をよく見ると,出力されたデータ・フレイムにはFreqと云う変数が新たに加わっている。この例では,それぞれのパタンに該当するのはせいぜい1ケースしかなかったのでFreqは0か1の値しかないが,全く同じ変数値プロファイルを持つケースが複数あれば,Freqもその2以上のケース数を表す。逆に,その様なFreq変数(変数名は別でも良い)を持つデータ・フレイムから,その度数によって重み付けを行った分割表を作成する事も xtabs( )によって可能になる。
# weightを付ける事が出来る。
data01$Freq <- c(1,2,3,4,5,6,7)
data01
xtabs(~ edu + outcome + sex, data=data01)
xtabs(Freq ~ edu + outcome + sex, data=data01)
data01$Freq <- c(1,2,3,4,5,6,7)
data01
xtabs(~ edu + outcome + sex, data=data01)
xtabs(Freq ~ edu + outcome + sex, data=data01)
これを利用すると,単に度数で重みを付けるだけでなく,サンプルの歪みの補正にしばしば使われる重み付け(ウェイト付け)を行う事も出来る。原理的には,重回帰分析などのウェイト付けと同じである。ウェイト付けを行わない場合と行った場合では,そもそも分布が違ったものになるので,分析結果も異なり得る。
# 単純に度数ではなく,ケースへのweight付けを同様に行える。
data01$weight <- c(1.6, .4, 1.8 , 0.2, .4, .6, 2.0)
data01
xtabs(weight ~ edu + outcome + sex, data=data01)
# 線型モデル lm( )におけるweight付け
data01$fsex <- factor(data01$sex) # 性別は要因型(名義尺度)に
data01$cedu <- data01$edu - mean(data01$edu) # 教育年数は中心化
lm(outcome ~ fsex * cedu, data=data01) # weight付け無し
lm(outcome ~ fsex * cedu, data=data01, weights=weight) # weight付け有り
data01$weight <- c(1.6, .4, 1.8 , 0.2, .4, .6, 2.0)
data01
xtabs(weight ~ edu + outcome + sex, data=data01)
# 線型モデル lm( )におけるweight付け
data01$fsex <- factor(data01$sex) # 性別は要因型(名義尺度)に
data01$cedu <- data01$edu - mean(data01$edu) # 教育年数は中心化
lm(outcome ~ fsex * cedu, data=data01) # weight付け無し
lm(outcome ~ fsex * cedu, data=data01, weights=weight) # weight付け有り
Copyright (C) 2016-2017 SUGINO Isamu All Rights Reserved. design by tempnate