杉野 勇 (SUGINO Isamu) お茶の水女子大学・人間発達科学専攻・応用社会学コース担当
『入門・社会統計学』サポートウェブ |
|
 第4章 統計的検定の一般型(general form of statistical testing)
第4章 統計的検定の一般型(general form of statistical testing)
多くの統計的検定に共通する一般型,もしくは論理構造(logical structure)を解説する。1-1 背理法(帰謬法; reduction to absurdity)



1-2 母集団についての推測としてのゼロ仮説
null hypothesis: 帰無仮説,ゼロ仮説,零仮説
null(ナル,ヌル): 「無効の,価値の無い,ゼロ(零)の,空の」「"null hypothesis"は,統計的検定において棄却された場合でさえ,それが正しいと証明された訳では決してなく,『否定するに足るだけの十分な証拠が無かった』と見做すべきだ」と云う考え方も説得的である。言い換えれば,否定(棄却)される場合にのみ意味があると云う立場である。その立場からすると「無に帰すべき」仮説と云うニュアンスで「帰無仮説」と呼ぶ事にも一理あるが,本書では,必ずしも"null hypothesis"は無に帰す訳ではない(否定・棄却される訳ではない)事は勿論の事,分析者からしても,無に帰す事を期待しているとは限らない(モデルの適合度検定など)と考え,「帰無仮説」ではなく,「議論の出発点(ゼロ地点)に置かれる仮説」と云うニュアンスを持たせて「ゼロ仮説」と呼ぶ事にする。
"null hypothesis"は文字通り「仮説」であり,未知のもの・不可知のものについての言明・命題をその内容とする。社会調査方法論では,いわゆる「量的(定量的)調査」であれ「質的(定性的)調査」であれ,母集団(全体)と標本(一部分)の枠組みでものを考える事を徹底すべきであると云うのが本書の主張である。本当に知りたいのは母集団(全体)についてであるが,実際に知る事が出来るのは標本(一部分)についてのみである。標本について仮説を立てる事を妨げる訳では必ずしもないが,実際に調査研究を行えば標本については情報・知識が得られるので,遅くともその時点では仮説の積極的意味はなくなる。それに対して,母集団については,通常,真実を直接知る事は永久に無いので,仮説を立てて考える事に意味がある,と云うより,それ以外に方法は無い。
であるから,"null hypothesis"は,未知の母集団についての(母数[parameter]についての)言明・命題がその内容になる。「もし,母集団において〜〜であったとしたら(null hypothesis),標本調査の結果が(実際に得られた)この様な結果になる確率はそこそこあるであろうか,それとも極めて低いであろうか」と云うのが統計的検定の骨格であり,得られる結論は,「null hypothesisを棄てるか,残すか」の二択である。
1-3 検定統計量(test statistic)と確率分布
1-4 有意水準(significance level)と有意確率(p-value)
本文で例示している母平均のt検定を実行するスクリプトを紹介する。

H0やp0の値を変えて同じスクリプトを(必要な部分からのみ)実行してみる。

# 作業フォルダの確認。そこにデータファイルを置く
getwd()
# dataの読み込みとq1700の度数分布表の確認
data01 <- read.csv("practice.csv")
table(data01$q1700, useNA="always")
# q1700が11となるのはNAにrecodeする
data01$q1700 <- c(0:10)[data01$q1700+1]
# 有効ケースだけをデータフレイムdata02とし,度数分布表の確認
data02 <- data01[complete.cases(data01$q1700),]
table(data02$q1700, useNA="always")
# 標本統計量や有効データ数の算出
n <- length(data02$q1700); n
m1700 <- mean(data02$q1700); m1700
sd1700 <- sd(data02$q1700); sd1700
se1700 <- sd1700/sqrt(n); se1700
H0 <- 5.0 # ゼロ仮説の値を指定する
t <- (m1700 - H0)/se1700; t
# t分布の正確な限界値
p0 <- .05
t0 <- qt(p0/2, df=n-1)
t1 <- qt(1-p0/2, df=n-1)
t0; t1
# 計算されたt統計量に対応する有意確率
p <- pt(-1*abs(t), df=n-1)*2; p
getwd()
# dataの読み込みとq1700の度数分布表の確認
data01 <- read.csv("practice.csv")
table(data01$q1700, useNA="always")
# q1700が11となるのはNAにrecodeする
data01$q1700 <- c(0:10)[data01$q1700+1]
# 有効ケースだけをデータフレイムdata02とし,度数分布表の確認
data02 <- data01[complete.cases(data01$q1700),]
table(data02$q1700, useNA="always")
# 標本統計量や有効データ数の算出
n <- length(data02$q1700); n
m1700 <- mean(data02$q1700); m1700
sd1700 <- sd(data02$q1700); sd1700
se1700 <- sd1700/sqrt(n); se1700
H0 <- 5.0 # ゼロ仮説の値を指定する
t <- (m1700 - H0)/se1700; t
# t分布の正確な限界値
p0 <- .05
t0 <- qt(p0/2, df=n-1)
t1 <- qt(1-p0/2, df=n-1)
t0; t1
# 計算されたt統計量に対応する有意確率
p <- pt(-1*abs(t), df=n-1)*2; p
H0やp0の値を変えて同じスクリプトを(必要な部分からのみ)実行してみる。
2-1 2種類の過誤(two types of errors)と検定力(statistical power)
αエラーとβエラーのトレイド・オフ
αエラーとβエラーのトレイド・オフについては,それぞれの過誤を刑事司法や病気の検査,新薬開発などの例で考えればイメージしやすいだろう。ある容疑者がいるとき,「その容疑者は無罪である」という“推定無罪”に基づくゼロ仮説を誤って棄却して有罪だとしてしまうのが“冤罪”であり,第一種の過誤にあたる。逆に,本当は真犯人であるのに推定無罪のゼロ仮説を棄却できないのが第二種の過誤にあたる。一般に(他の条件が一定であれば),有罪判定の条件を厳しくすれば第一種の過誤である冤罪は減るが,第二種の過誤である真犯人の取り逃がしは増えると想定される。
病気の検査の例では,「検査対象の人は,病気ではない」をゼロ仮説とすると,本当は病気ではないのに検査で陽性になる偽陽性がαエラーであり,本当は罹患しているのに検査で陽性にならない偽陰性がβエラーである。検査の性能が同じであれば,陽性判定の基準を緩めればβエラーは減るがαエラーは増え,逆に陽性判定基準を厳しくすれば,βエラーは減るがαエラーが増える。
新薬開発の臨床試験では,「新薬に優れた効果はない」をゼロ仮説とすると,本当は効果はないのにたまたま効果があるかのような結果が得られる確率がαエラーであり,本当は優れた効果があるのにゼロ仮説が棄却できないのがβエラーである。
こうした二つのエラー(やリスク)のトレイド・オフは人間社会の様々な領域に遍在している。自分でも是非一つ具体的な例を考えてみよう。
続いて,本文で示しているのと同様のグラフを描くスクリプトを説明する。
H0 <- 5.0 # 母平均のゼロ仮説の値を指定する
p0 <- .95 # 信頼係数を指定する
sigma <- 2 # 母分散の仮定値
n <- 100 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが受容される範囲", H0))
abline(h=0, col="gray")
range <- seq(H0-qnorm((1+p0)/2, 0, 1)*se, H0+qnorm((1+p0)/2, 0, 1)*se, by=.01)
segments(range, 0, range, dnorm(range, mean=H0, sd=se), col="gray")
range の代入部分は,本当はp0 <- .95 # 信頼係数を指定する
sigma <- 2 # 母分散の仮定値
n <- 100 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが受容される範囲", H0))
abline(h=0, col="gray")
range <- seq(H0-qnorm((1+p0)/2, 0, 1)*se, H0+qnorm((1+p0)/2, 0, 1)*se, by=.01)
segments(range, 0, range, dnorm(range, mean=H0, sd=se), col="gray")
range <- seq(qnorm((1-p0)/2, mean=H0, sd=se), qnorm((1+p0)/2, mean=H0, sd=se), by=.01)
とする方が直接的ではある。
H0,p0,sigma,nの値を変えて実行するとどうなるか。ついでに限界値の値をx軸に追記してみる。
H0 <- 8.0 # 母平均のゼロ仮説の値を指定する
p0 <- .90 # 信頼係数を指定する
sigma <- 3 # 母分散の仮定値
n <- 400 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが受容される範囲", H0),
xlim=c(H0-5*se, H0+5*se))
abline(h=0, col="gray")
range <- seq(qnorm((1-p0)/2, mean=H0, sd=se), qnorm((1+p0)/2, mean=H0, sd=se), by=.01)
segments(range, 0, range, dnorm(range, mean=H0, sd=se), col="gray")
axis(side=1, at=c(qnorm((1-p0)/2, mean=H0, sd=se), qnorm((1+p0)/2, mean=H0, sd=se)), col="red", col.axis="red", las=2)
p0 <- .90 # 信頼係数を指定する
sigma <- 3 # 母分散の仮定値
n <- 400 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが受容される範囲", H0),
xlim=c(H0-5*se, H0+5*se))
abline(h=0, col="gray")
range <- seq(qnorm((1-p0)/2, mean=H0, sd=se), qnorm((1+p0)/2, mean=H0, sd=se), by=.01)
segments(range, 0, range, dnorm(range, mean=H0, sd=se), col="gray")
axis(side=1, at=c(qnorm((1-p0)/2, mean=H0, sd=se), qnorm((1+p0)/2, mean=H0, sd=se)), col="red", col.axis="red", las=2)
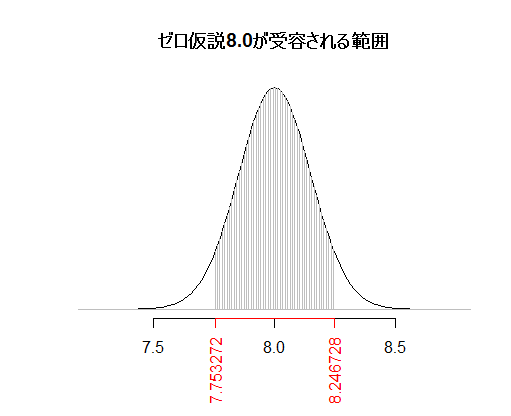
上の数値の設定においては,標本平均が約7.75から約8.25の間であれば,「母平均は8.0である」というゼロ仮説は有意水準10%(p0=.90)で棄却されないということを示したグラフが描かれている。
ここに,対立仮説に従う場合の標本抽出分布を重ね書きしてみよう。
H1 <- 5.3 # 母平均の対立仮説の値を指定する
par(new=T) # 現在のグラフの上に重ね描きする
curve(dnorm(x, mean=H1, sd=se), from=H1-5*se, to=H1+5*se,
xlab="", ylab="", bty="n", axes=F, xlim=c(H0-5*se, H0+5*se),
main=sprintf("\n\n対立仮説%.1fが受容されない範囲", H1))
segments(range, 0, range, dnorm(range, mean=H1, sd=se), col="gray50")
par(new=T) # 現在のグラフの上に重ね描きする
curve(dnorm(x, mean=H1, sd=se), from=H1-5*se, to=H1+5*se,
xlab="", ylab="", bty="n", axes=F, xlim=c(H0-5*se, H0+5*se),
main=sprintf("\n\n対立仮説%.1fが受容されない範囲", H1))
segments(range, 0, range, dnorm(range, mean=H1, sd=se), col="gray50")
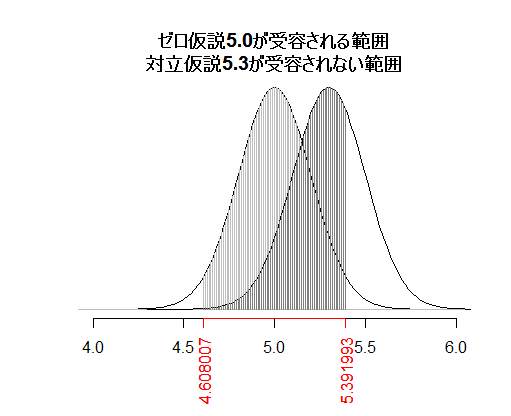
対立仮説をH1=5.3としている。自由に指定出来るが,H0と余りに離れた値を指定するとグラフ内に描かれなくなるので,ゼロ仮説のグラフのx軸のメモリを見ながら注意して欲しい。
ゼロ仮説が棄却されない標本統計量の範囲を赤で示しているが,本当は対立仮説が真である場合,この範囲の標本統計量が出現したら,ゼロ仮説が棄却されない=対立仮説が受容されない,と云う事になるのである。
これが「第二種の過誤」「βエラー」である。(第一種の過誤,αエラーはp0によって自分で指定している。)
βエラーの確率を計算してみよう。本文とは少し違うやり方であるが,同じことを色々な方法でできるのである。
beta <- pnorm(qnorm((1+p0)/2, mean=H0, sd=se), mean=H1, sd=se)-pnorm(qnorm((1-p0)/2, mean=H0, sd=se), mean=H1, sd=se)
beta # βエラー
1-beta # 対立仮説をH1と特定した場合の検定力
beta # βエラー
1-beta # 対立仮説をH1と特定した場合の検定力

2-2 標本サイズ(sample size)と検定力
本文のように,標本サイズを100から400に4倍にしたときに検定力がどうなるかを確認しよう。
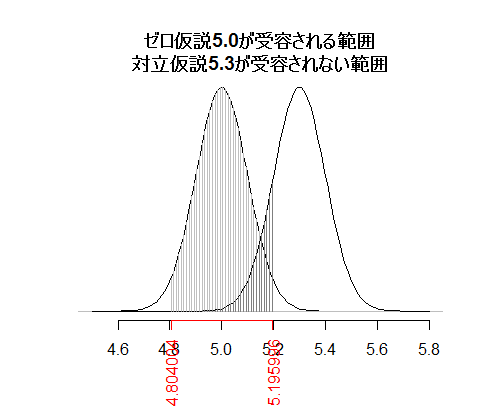
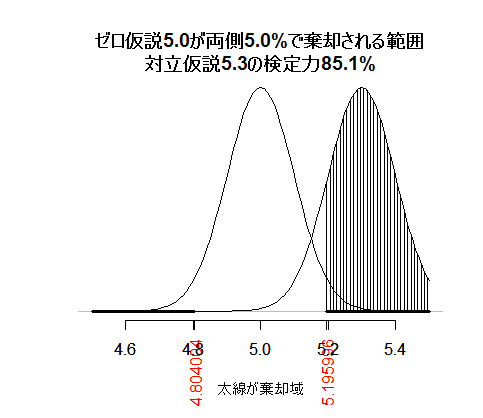
x軸をよく見ると,二つの正規分布がいずれもかなり細くなり(幅が半分になっている),重複する部分が少なくなっていることが明らかである。βエラーと検定力は,

と,n=100ではβエラーが67.7%,検定力が32.3%であったのに対し,n=400ではβエラーが14.9%,検定力が85.1%と大幅に改善している。
H0 <- 5.0 # 母平均のゼロ仮説の値
H1 <- 5.3 # 母平均の対立仮説の値
n <- 400 # サンプルサイズの設定
p0 <- .95 # 信頼係数を指定
sigma <- 2 # 母分散の仮定値
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=min(H0, H1)-5*se, to=max(H0, H1)+5*se,
xlab="", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが受容される範囲", H0),
xlim=c(min(H0, H1)-5*se, max(H0, H1)+5*se))
abline(h=0, col="gray")
range <- seq(H0-qnorm((1+p0)/2, 0, 1)*se, H0+qnorm((1+p0)/2, 0, 1)*se, by=.01)
segments(range, 0, range, dnorm(range, mean=H0, sd=se), col="gray")
axis(side=1, at=c(qnorm((1-p0)/2, mean=H0, sd=se), qnorm((1+p0)/2, mean=H0, sd=se)),
col="red", col.axis="red", las=2)
par(new=T) # 現在のグラフの上に重ね描きする
curve(dnorm(x, mean=H1, sd=se), from=min(H0, H1)-5*se, to=max(H0, H1)+5*se,
xlab="", ylab="", bty="n", axes=F, xlim=c(min(H0, H1)-5*se, max(H0, H1)+5*se),
main=sprintf("\n\n対立仮説%.1fが受容されない範囲", H1))
segments(range, 0, range, dnorm(range, mean=H1, sd=se), col="gray50")
beta <- pnorm(qnorm((1+p0)/2, mean=H0, sd=se), mean=H1, sd=se)-pnorm(qnorm((1-p0)/2, mean=H0, sd=se), mean=H1, sd=se)
beta # βエラー
1-beta # 対立仮説をH1と特定した場合の検定力
H1 <- 5.3 # 母平均の対立仮説の値
n <- 400 # サンプルサイズの設定
p0 <- .95 # 信頼係数を指定
sigma <- 2 # 母分散の仮定値
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=min(H0, H1)-5*se, to=max(H0, H1)+5*se,
xlab="", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが受容される範囲", H0),
xlim=c(min(H0, H1)-5*se, max(H0, H1)+5*se))
abline(h=0, col="gray")
range <- seq(H0-qnorm((1+p0)/2, 0, 1)*se, H0+qnorm((1+p0)/2, 0, 1)*se, by=.01)
segments(range, 0, range, dnorm(range, mean=H0, sd=se), col="gray")
axis(side=1, at=c(qnorm((1-p0)/2, mean=H0, sd=se), qnorm((1+p0)/2, mean=H0, sd=se)),
col="red", col.axis="red", las=2)
par(new=T) # 現在のグラフの上に重ね描きする
curve(dnorm(x, mean=H1, sd=se), from=min(H0, H1)-5*se, to=max(H0, H1)+5*se,
xlab="", ylab="", bty="n", axes=F, xlim=c(min(H0, H1)-5*se, max(H0, H1)+5*se),
main=sprintf("\n\n対立仮説%.1fが受容されない範囲", H1))
segments(range, 0, range, dnorm(range, mean=H1, sd=se), col="gray50")
beta <- pnorm(qnorm((1+p0)/2, mean=H0, sd=se), mean=H1, sd=se)-pnorm(qnorm((1-p0)/2, mean=H0, sd=se), mean=H1, sd=se)
beta # βエラー
1-beta # 対立仮説をH1と特定した場合の検定力
x軸をよく見ると,二つの正規分布がいずれもかなり細くなり(幅が半分になっている),重複する部分が少なくなっていることが明らかである。βエラーと検定力は,
と,n=100ではβエラーが67.7%,検定力が32.3%であったのに対し,n=400ではβエラーが14.9%,検定力が85.1%と大幅に改善している。
発展1-1 片側検定(one-tailed test)と両側検定(two-tailed test)
本文のように棄却域を図示するスクリプトを書く。
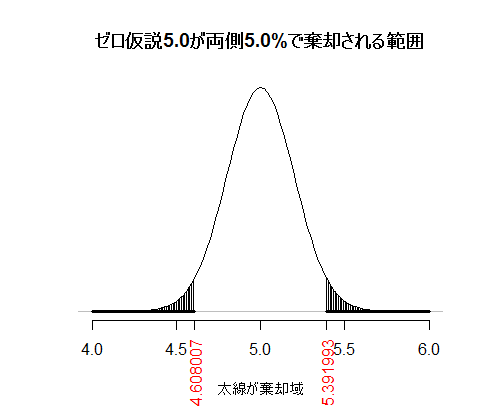
次に,片側(右側)だけに棄却域を設ける片側検定の場合を図示する。
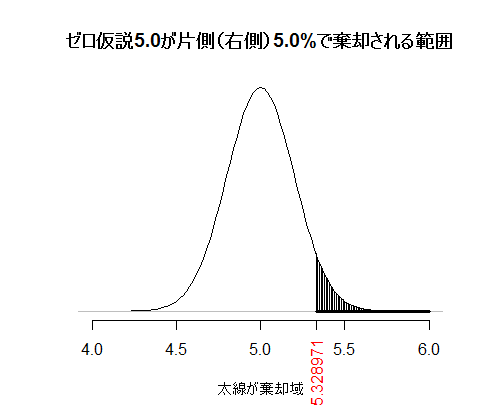
二つのグラフを見比べると,両側5%検定の棄却域の右側(プラス方向の裾)だけを見ると,片側5%検定の棄却域に含まれていることが分かる。つまり,両側5%検定でプラスの方向に有意になる場合,片側5%検定でも必ず有意になる。当然,片側検定で適切な側に棄却域が設定できることが大前提ではある。
両側5%検定か片側5%検定かの違いが重要なのは,検定力も考えた場合であろう。上記の例それぞれに,対立仮説5.3の検定力を書き入れよう。
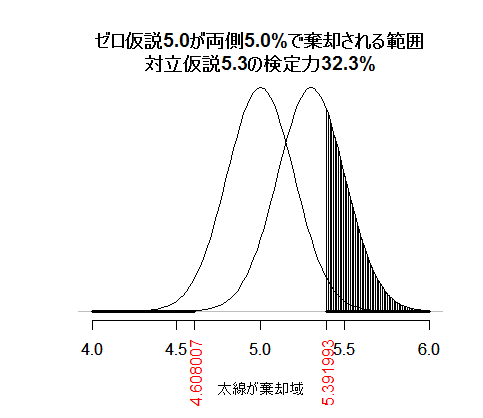
塗り潰されている部分の面積が,対立仮説が真である時にゼロ仮説が正しく棄却される確率を示している。両側なのでマイナス方向にもその領域が存在しているのだが,高さが殆どゼロなので図でも面積としては見えない。
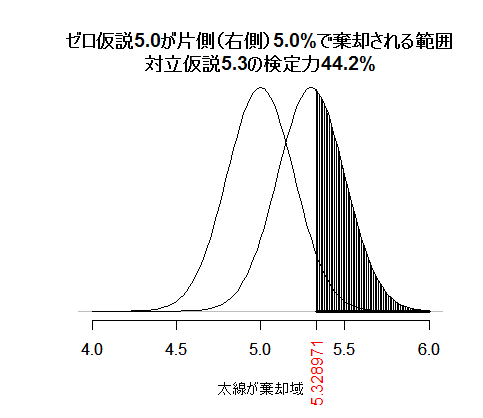
片側検定で同じ事を図示したのが下の図である。
ぞれぞれのスクリプトでnを400にして実行して比べたのが下の2つの図である。
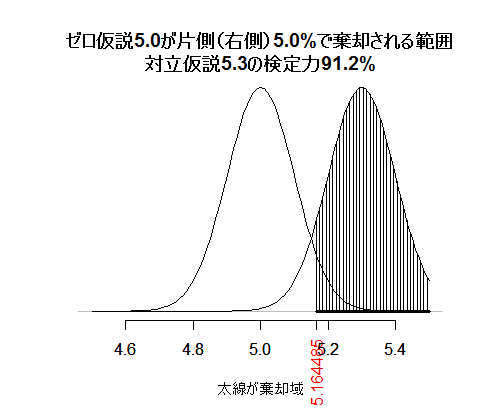
H0 <- 5.0 # 母平均のゼロ仮説の値を指定
p0 <- .05 # 有意水準を指定
sigma <- 2 # 母分散の仮定値
n <- 100 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="太線が棄却域", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが両側%.1f%%で棄却される範囲", H0, p0*100),
xlim=c(H0-5*se, H0+5*se))
abline(h=0, col="gray")
segments(H0-5*se, 0, qnorm(p0/2, mean=H0, sd=se), 0, lwd=3)
segments(qnorm(1-p0/2, mean=H0, sd=se), 0, H0+5*se, 0, lwd=3)
axis(side=1, at=c(qnorm(p0/2, mean=H0, sd=se), qnorm(1-p0/2, mean=H0, sd=se)),
col.axis="red", las=2)
range <- c(seq(H0-5*se, qnorm(p0/2, mean=H0, sd=se), by=.01),
seq(qnorm(1-p0/2, mean=H0, sd=se), H0+5*se, by=.01))
segments(range, 0, range, dnorm(range, mean=H0, sd=se))
p0 <- .05 # 有意水準を指定
sigma <- 2 # 母分散の仮定値
n <- 100 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="太線が棄却域", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが両側%.1f%%で棄却される範囲", H0, p0*100),
xlim=c(H0-5*se, H0+5*se))
abline(h=0, col="gray")
segments(H0-5*se, 0, qnorm(p0/2, mean=H0, sd=se), 0, lwd=3)
segments(qnorm(1-p0/2, mean=H0, sd=se), 0, H0+5*se, 0, lwd=3)
axis(side=1, at=c(qnorm(p0/2, mean=H0, sd=se), qnorm(1-p0/2, mean=H0, sd=se)),
col.axis="red", las=2)
range <- c(seq(H0-5*se, qnorm(p0/2, mean=H0, sd=se), by=.01),
seq(qnorm(1-p0/2, mean=H0, sd=se), H0+5*se, by=.01))
segments(range, 0, range, dnorm(range, mean=H0, sd=se))
次に,片側(右側)だけに棄却域を設ける片側検定の場合を図示する。
H0 <- 5.0 # 母平均のゼロ仮説の値を指定する
p0 <- .05 # 有意水準を指定する
sigma <- 2 # 母分散の仮定値
n <- 100 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="太線が棄却域", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが片側(右側)%.1f%%で棄却される範囲", H0, p0*100),
xlim=c(H0-5*se, H0+5*se))
abline(h=0, col="gray")
segments(qnorm(1-p0, mean=H0, sd=se), 0, H0+5*se, 0, lwd=3)
axis(side=1, at=c(qnorm(1-p0, mean=H0, sd=se)),
col.axis="red", las=2)
range <- seq(qnorm(1-p0, mean=H0, sd=se), H0+5*se, by=.01)
segments(range, 0, range, dnorm(range, mean=H0, sd=se))
p0 <- .05 # 有意水準を指定する
sigma <- 2 # 母分散の仮定値
n <- 100 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="太線が棄却域", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが片側(右側)%.1f%%で棄却される範囲", H0, p0*100),
xlim=c(H0-5*se, H0+5*se))
abline(h=0, col="gray")
segments(qnorm(1-p0, mean=H0, sd=se), 0, H0+5*se, 0, lwd=3)
axis(side=1, at=c(qnorm(1-p0, mean=H0, sd=se)),
col.axis="red", las=2)
range <- seq(qnorm(1-p0, mean=H0, sd=se), H0+5*se, by=.01)
segments(range, 0, range, dnorm(range, mean=H0, sd=se))
二つのグラフを見比べると,両側5%検定の棄却域の右側(プラス方向の裾)だけを見ると,片側5%検定の棄却域に含まれていることが分かる。つまり,両側5%検定でプラスの方向に有意になる場合,片側5%検定でも必ず有意になる。当然,片側検定で適切な側に棄却域が設定できることが大前提ではある。
両側5%検定か片側5%検定かの違いが重要なのは,検定力も考えた場合であろう。上記の例それぞれに,対立仮説5.3の検定力を書き入れよう。
H0 <- 5.0 # 母平均のゼロ仮説の値を指定
p0 <- .05 # 有意水準を指定
sigma <- 2 # 母分散の仮定値
n <- 100 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="太線が棄却域", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが両側%.1f%%で棄却される範囲", H0, p0*100),
xlim=c(H0-5*se, H0+5*se))
abline(h=0, col="gray")
segments(H0-5*se, 0, qnorm(p0/2, mean=H0, sd=se), 0, lwd=3)
segments(qnorm(1-p0/2, mean=H0, sd=se), 0, H0+5*se, 0, lwd=3)
axis(side=1, at=c(qnorm(p0/2, mean=H0, sd=se), qnorm(1-p0/2, mean=H0, sd=se)),
col.axis="red", las=2)
range <- c(seq(H0-5*se, qnorm(p0/2, mean=H0, sd=se), by=.01),
seq(qnorm(1-p0/2, mean=H0, sd=se), H0+5*se, by=.01))
H1 <- 5.3 # 対立仮説の値を指定
beta <- pnorm(qnorm(1-p0/2, mean=H0, sd=se), mean=H1, sd=se)-pnorm(qnorm(p0/2, mean=H0, sd=se), mean=H1, sd=se)
par(new=T)
curve(dnorm(x, mean=H1, sd=se), from=H0-5*se, to=H0+5*se,
xlab="", ylab="", bty="n", yaxt="n",
main=sprintf("\n\n対立仮説%.1fの検定力%.1f%%", H1, (1-beta)*100),
xlim=c(H0-5*se, H0+5*se))
segments(range, 0, range, dnorm(range, mean=H1, sd=se))
p0 <- .05 # 有意水準を指定
sigma <- 2 # 母分散の仮定値
n <- 100 # サンプルサイズの設定
se <- sigma/sqrt(n) # 標本平均の標準誤差
curve(dnorm(x, mean=H0, sd=se), from=H0-5*se, to=H0+5*se,
xlab="太線が棄却域", ylab="", bty="n", yaxt="n",
main=sprintf("ゼロ仮説%.1fが両側%.1f%%で棄却される範囲", H0, p0*100),
xlim=c(H0-5*se, H0+5*se))
abline(h=0, col="gray")
segments(H0-5*se, 0, qnorm(p0/2, mean=H0, sd=se), 0, lwd=3)
segments(qnorm(1-p0/2, mean=H0, sd=se), 0, H0+5*se, 0, lwd=3)
axis(side=1, at=c(qnorm(p0/2, mean=H0, sd=se), qnorm(1-p0/2, mean=H0, sd=se)),
col.axis="red", las=2)
range <- c(seq(H0-5*se, qnorm(p0/2, mean=H0, sd=se), by=.01),
seq(qnorm(1-p0/2, mean=H0, sd=se), H0+5*se, by=.01))
H1 <- 5.3 # 対立仮説の値を指定
beta <- pnorm(qnorm(1-p0/2, mean=H0, sd=se), mean=H1, sd=se)-pnorm(qnorm(p0/2, mean=H0, sd=se), mean=H1, sd=se)
par(new=T)
curve(dnorm(x, mean=H1, sd=se), from=H0-5*se, to=H0+5*se,
xlab="", ylab="", bty="n", yaxt="n",
main=sprintf("\n\n対立仮説%.1fの検定力%.1f%%", H1, (1-beta)*100),
xlim=c(H0-5*se, H0+5*se))
segments(range, 0, range, dnorm(range, mean=H1, sd=se))
塗り潰されている部分の面積が,対立仮説が真である時にゼロ仮説が正しく棄却される確率を示している。両側なのでマイナス方向にもその領域が存在しているのだが,高さが殆どゼロなので図でも面積としては見えない。
片側検定で同じ事を図示したのが下の図である。
ぞれぞれのスクリプトでnを400にして実行して比べたのが下の2つの図である。
発展1-2 区間推定と検定
本文と同様,(簡便化の為に母分散が既知であるとして)母平均の検定と区間推定が表裏一体の関係にある事を示してみよう。
母集団サイズは十分に大きいとして有限母集団修正項は省略しても議論に違いはない。母分散が既知であるとしているのでt分布ではなく標準正規分布を使用出来る。
数値を幾つに設定するかは本質的ではないので,母分散sigma=10,標本サイズn=200,調査を実施して得られた標本平均m=50,と仮定しよう。
この時,まずは区間推定によって95%信頼区間を求める。

次に,有意水準5%(=100% - 95%)での統計的検定(ゼロ仮説有意性検定; NHST)を,様々なゼロ仮説の値H0について実行し,どんな仮説値は棄却され,どんな仮説値は棄却されないかを調べてみる。
標準正規分布に従うと考えられる検定統計量zは (m - H0)/(sigma/sqrt(n)) で計算出来るので,この値の絶対値が1.96以内に収まればそのゼロ仮説は棄却されず,1.96を超えれば棄却される。
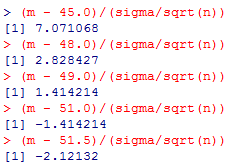
以下は,H0の部分に手動で任意の値を指定してzを計算した結果である。
先の区間推定の結果と見比べると,95%信頼区間に含まれる値を仮定したゼロ仮説は棄却されず,95%信頼区間の外の値を仮定したゼロ仮説は棄却されている事が確認出来る。
もっと大量の仮説値H0について半自動で検定を行い,棄却されなかったものだけを表示させる事も出来る。

スクリプトの by=.1 の部分を,.01や.001などより小さな値にすればそれだけ精度が上がっていくが,余り小さく刻むと計算に少し時間がかかる様になる。またH0の値の集合をそのまま表示させると膨大になって画面に表示し切れなくなるので,range( )関数で最大値と最小値だけを表示させるのが良い。

下の二つの結果は,by= の値は異なるので計算結果の精度は異なるのだが,結果の表示桁数がいずれもデフォルトで7桁に設定されているので一見異なった結果に見える。もしも表示桁数を7桁よりも大きくしたければ(例えば全部で10桁まで表示させたければ),options(digits=10) などとすれば良い。
母集団サイズは十分に大きいとして有限母集団修正項は省略しても議論に違いはない。母分散が既知であるとしているのでt分布ではなく標準正規分布を使用出来る。
数値を幾つに設定するかは本質的ではないので,母分散sigma=10,標本サイズn=200,調査を実施して得られた標本平均m=50,と仮定しよう。
この時,まずは区間推定によって95%信頼区間を求める。
sigma <- 10 # 母分散
n <- 200 # 標本サイズ
m <- 50 # 標本平均
se <- sigma/sqrt(n) # 標準誤差
# 母平均の95%信頼区間
lwr <- m - 1.96*se; upr <- m + 1.96*se
lwr; upr # 95%信頼区間の下限と上限
n <- 200 # 標本サイズ
m <- 50 # 標本平均
se <- sigma/sqrt(n) # 標準誤差
# 母平均の95%信頼区間
lwr <- m - 1.96*se; upr <- m + 1.96*se
lwr; upr # 95%信頼区間の下限と上限
次に,有意水準5%(=100% - 95%)での統計的検定(ゼロ仮説有意性検定; NHST)を,様々なゼロ仮説の値H0について実行し,どんな仮説値は棄却され,どんな仮説値は棄却されないかを調べてみる。
標準正規分布に従うと考えられる検定統計量zは (m - H0)/(sigma/sqrt(n)) で計算出来るので,この値の絶対値が1.96以内に収まればそのゼロ仮説は棄却されず,1.96を超えれば棄却される。
以下は,H0の部分に手動で任意の値を指定してzを計算した結果である。
# ゼロ仮説有意性検定
# ゼロ仮説として仮定する母平均値に,様々な値を入れて計算する。
# この絶対値が1.96を超えたらこのゼロ仮説は棄却される。
(m - 45.0)/(sigma/sqrt(n))
(m - 48.0)/(sigma/sqrt(n))
(m - 49.0)/(sigma/sqrt(n))
(m - 51.0)/(sigma/sqrt(n))
(m - 51.5)/(sigma/sqrt(n))
# ゼロ仮説として仮定する母平均値に,様々な値を入れて計算する。
# この絶対値が1.96を超えたらこのゼロ仮説は棄却される。
(m - 45.0)/(sigma/sqrt(n))
(m - 48.0)/(sigma/sqrt(n))
(m - 49.0)/(sigma/sqrt(n))
(m - 51.0)/(sigma/sqrt(n))
(m - 51.5)/(sigma/sqrt(n))
先の区間推定の結果と見比べると,95%信頼区間に含まれる値を仮定したゼロ仮説は棄却されず,95%信頼区間の外の値を仮定したゼロ仮説は棄却されている事が確認出来る。
もっと大量の仮説値H0について半自動で検定を行い,棄却されなかったものだけを表示させる事も出来る。
# 半自動で様々な仮説値H0について検定し,棄却されないものを集める
H0 <- seq(m-sigma, m+sigma, by=.1) # 複数のゼロ仮説値をヴェクトルとして作成
z0 <- (m - H0)/(sigma/sqrt(n)) # 検定統計量z0
# z0の絶対値が1.96以下になるH0の範囲を表示
H0[abs(z0) <= 1.96]
H0 <- seq(m-sigma, m+sigma, by=.1) # 複数のゼロ仮説値をヴェクトルとして作成
z0 <- (m - H0)/(sigma/sqrt(n)) # 検定統計量z0
# z0の絶対値が1.96以下になるH0の範囲を表示
H0[abs(z0) <= 1.96]
スクリプトの by=.1 の部分を,.01や.001などより小さな値にすればそれだけ精度が上がっていくが,余り小さく刻むと計算に少し時間がかかる様になる。またH0の値の集合をそのまま表示させると膨大になって画面に表示し切れなくなるので,range( )関数で最大値と最小値だけを表示させるのが良い。
# もっと桁数を増やして,最後の結果は範囲rangeだけ表示させる
H0 <- seq(m-sigma, m+sigma, by=.0001)
z0 <- (m - H0)/(sigma/sqrt(n))
range(H0[abs(z0) <= 1.96]) # 有意水準5%で棄却されない仮説値の範囲
以下に,by= の部分を3通りほど変えて試した結果を示す。H0 <- seq(m-sigma, m+sigma, by=.0001)
z0 <- (m - H0)/(sigma/sqrt(n))
range(H0[abs(z0) <= 1.96]) # 有意水準5%で棄却されない仮説値の範囲
下の二つの結果は,by= の値は異なるので計算結果の精度は異なるのだが,結果の表示桁数がいずれもデフォルトで7桁に設定されているので一見異なった結果に見える。もしも表示桁数を7桁よりも大きくしたければ(例えば全部で10桁まで表示させたければ),options(digits=10) などとすれば良い。
発展1-3 母分散が未知の場合の検定力
? 通常のt分布から求める 上の1-2で準備したデータフレイムdata02とその中の変数q1700を使用する。本文では四捨五入して計算例を示しているのでやや誤差が積み重なっている。ここではなるべく四捨五入せずに計算を進めていく。

ゼロ仮説が棄却できない標本平均の範囲が求められたので,対立仮説が正しい場合のt統計量の式にこれらを代入してtの範囲を求め,それに対応する面積=確率を求める。

「ゼロ仮説が棄却できない標本平均の範囲」から「真にt分布に従う標本統計量の範囲」を求め,t分布におけるその面積=確率を求めたところ,約13.2%となった。つまり,対立仮説が正しいときにゼロ仮説が棄却できない確率が13.2%となり,これがβエラーである。本文では約13%弱だったので四捨五入誤差によって僅かにずれる。検定力(検出力)は1-.132=.868より86.8%となる。
? 非心t分布を用いて求める 上の?では,対立仮説の値から,対立仮説が真であるときに本当にt分布に従う標本統計量を計算し,検定力を求めた。Rを使えばこの計算もさほど難しくはないが,通常は「非心t分布(noncentric t-distribution)」を利用する。
非心t分布を使う方法では,標本統計量には,ゼロ仮説に基づいて計算したt値を用いるが,これが従う分布がt分布ではなく非心t分布であることを利用する。
非心t分布は,通常のt分布を含んだより一般的なt分布である。通常のt分布は,「非心度パラメタ(ncp; noncentrality parameter)」が0の非心t分布と位置付けられる。
Rの関数は,t分布についての関数pt(t, df),qt(p, df),dt(t, df)に,ncp=のオプションをつけるだけである。 逆に言えば,これまでのt分布の関数は,ncp=0と指定するのを省略していただけと言える。

ゼロ仮説が(正しく)棄却される確率として,?の計算結果とほぼ同じ86.8%という確率が得られた。
非心t分布のグラフは,もっとも単純には以下のコマンドで描ける。非心度パラメタと自由度を適当に指定し,x軸の描画範囲を非心度が中心になるように設定した。
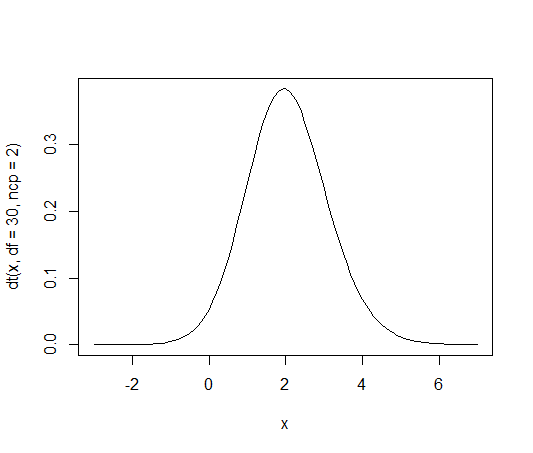
正規分布やt分布のグラフとの大きな違いは,左右対称ではないという点である。
次の様にすると,t分布と非心t分布を重ねて描く事が出来る。実線が非心度0のt分布,点線が非心度3の非心t分布である。
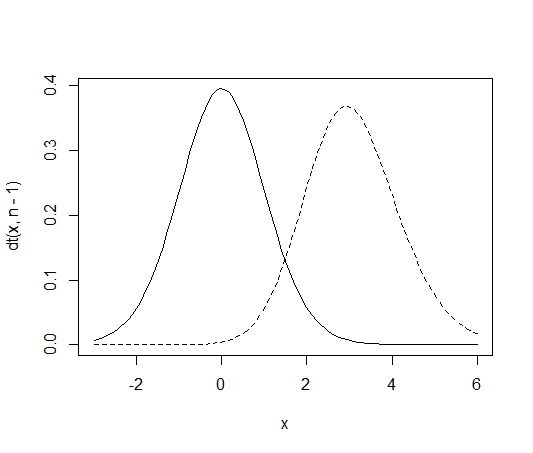
非心度0のt分布と比較することで,非心t分布の歪みがよくわかるだろう。
本文と同様の図を描くスクリプトは以下である。
? power.t.test( )関数で求める 検定力関数 power.t.test(n, delta, sd, sig.level, power, type="one.sample | two.sample") を使って,本文よりも正確な値を計算してみよう。
どの方法で検定力を計算しても,ほとんど同じ値を得る事ができた。
H0 <- 5.0 # 母平均のゼロ仮説の値を指定
p0 <- .05 # 有意水準を指定
n <- length(data02$q1700)
m1700 <- mean(data02$q1700) # これはここでは使わない
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n)
# n, sdを固定したときに,両側検定でゼロ仮説が棄却されないmの範囲
qt(p0/2, df=n-1); qt(1-p0/2, df=n-1)
qt(p0/2, df=n-1)*se1700+H0 # 標本平均の範囲に変換
qt(1-p0/2, df=n-1)*se1700+H0
p0 <- .05 # 有意水準を指定
n <- length(data02$q1700)
m1700 <- mean(data02$q1700) # これはここでは使わない
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n)
# n, sdを固定したときに,両側検定でゼロ仮説が棄却されないmの範囲
qt(p0/2, df=n-1); qt(1-p0/2, df=n-1)
qt(p0/2, df=n-1)*se1700+H0 # 標本平均の範囲に変換
qt(1-p0/2, df=n-1)*se1700+H0
ゼロ仮説が棄却できない標本平均の範囲が求められたので,対立仮説が正しい場合のt統計量の式にこれらを代入してtの範囲を求め,それに対応する面積=確率を求める。
lwr <- qt(p0/2, df=n-1)*se1700+H0 # 標本平均の範囲に変換し,代入
upr <- qt(1-p0/2, df=n-1)*se1700+H0
H1 <- 5.3 # 対立仮説
(lwr - H1)/se1700; (upr - H1)/se1700 # 真にt分布に従う標本統計量の範囲
pt((upr - H1)/se1700, df=n-1) - pt((lwr - H1)/se1700, df=n-1) # 対応する確率
upr <- qt(1-p0/2, df=n-1)*se1700+H0
H1 <- 5.3 # 対立仮説
(lwr - H1)/se1700; (upr - H1)/se1700 # 真にt分布に従う標本統計量の範囲
pt((upr - H1)/se1700, df=n-1) - pt((lwr - H1)/se1700, df=n-1) # 対応する確率
「ゼロ仮説が棄却できない標本平均の範囲」から「真にt分布に従う標本統計量の範囲」を求め,t分布におけるその面積=確率を求めたところ,約13.2%となった。つまり,対立仮説が正しいときにゼロ仮説が棄却できない確率が13.2%となり,これがβエラーである。本文では約13%弱だったので四捨五入誤差によって僅かにずれる。検定力(検出力)は1-.132=.868より86.8%となる。
? 非心t分布を用いて求める 上の?では,対立仮説の値から,対立仮説が真であるときに本当にt分布に従う標本統計量を計算し,検定力を求めた。Rを使えばこの計算もさほど難しくはないが,通常は「非心t分布(noncentric t-distribution)」を利用する。
非心t分布を使う方法では,標本統計量には,ゼロ仮説に基づいて計算したt値を用いるが,これが従う分布がt分布ではなく非心t分布であることを利用する。
非心t分布は,通常のt分布を含んだより一般的なt分布である。通常のt分布は,「非心度パラメタ(ncp; noncentrality parameter)」が0の非心t分布と位置付けられる。
Rの関数は,t分布についての関数pt(t, df),qt(p, df),dt(t, df)に,ncp=のオプションをつけるだけである。 逆に言えば,これまでのt分布の関数は,ncp=0と指定するのを省略していただけと言える。
H0 <- 5.0 # 母平均のゼロ仮説
H1 <- 5.3 # 対立仮説
p0 <- .05 # 有意水準
n <- length(data02$q1700)
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n)
# 通常のt分布の,有意水準p0での棄却域の限界値(2つ)
reject <- c(qt(p0/2, df=n-1), qt(1-p0/2, df=n-1))
# 非心度の計算
ncp0 <- (H1 - H0)/se1700
# 非心t分布で上の棄却域に対応する範囲の確率
1 - pt(reject[2], df=n-1, ncp=ncp0) + pt(reject[1], df=n-1, ncp=ncp0)
H1 <- 5.3 # 対立仮説
p0 <- .05 # 有意水準
n <- length(data02$q1700)
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n)
# 通常のt分布の,有意水準p0での棄却域の限界値(2つ)
reject <- c(qt(p0/2, df=n-1), qt(1-p0/2, df=n-1))
# 非心度の計算
ncp0 <- (H1 - H0)/se1700
# 非心t分布で上の棄却域に対応する範囲の確率
1 - pt(reject[2], df=n-1, ncp=ncp0) + pt(reject[1], df=n-1, ncp=ncp0)
ゼロ仮説が(正しく)棄却される確率として,?の計算結果とほぼ同じ86.8%という確率が得られた。
非心t分布のグラフは,もっとも単純には以下のコマンドで描ける。非心度パラメタと自由度を適当に指定し,x軸の描画範囲を非心度が中心になるように設定した。
curve(dt(x, df=30, ncp=2), from=-3, to=7)
正規分布やt分布のグラフとの大きな違いは,左右対称ではないという点である。
次の様にすると,t分布と非心t分布を重ねて描く事が出来る。実線が非心度0のt分布,点線が非心度3の非心t分布である。
n <- 30; curve(dt(x, df=n-1), from=-3, to=6); curve(dt(x, df=n-1, ncp=3), from=-3, to=6, lty=2, add=T)
非心度0のt分布と比較することで,非心t分布の歪みがよくわかるだろう。
本文と同様の図を描くスクリプトは以下である。
H0 <- 5.0 # 母平均のゼロ仮説
H1 <- 5.3 # 対立仮説
p0 <- .05 # 有意水準
n <- length(data02$q1700)
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n)
# 非心度の計算
ncp0 <- (H1 - H0)/se1700
# 通常のt分布の,有意水準p0でのゼロ仮説の採択域
reject <- seq(qt(p0/2, df=n-1), qt(1-p0/2, df=n-1), by=.03)
# 非心t分布で上の棄却域に対応する範囲の確率
beta <- pt(qt(1-p0/2, df=n-1), df=n-1, ncp=ncp0) - pt(qt(p0/2, df=n-1), df=n-1, ncp=ncp0)
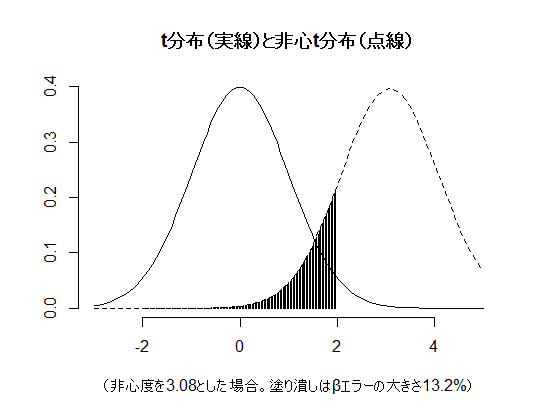
curve(dt(x, df=n-1), from=-3, to=5, bty="n", main="t分布(実線)と非心t分布(点線)", ylab="",
xlab=sprintf("(非心度を%.2fとした場合。塗り潰しはβエラーの大きさ%.1f%%)", ncp0, beta*100))
curve(dt(x, df=n-1, ncp=ncp0), from=-3, to=5, lty=2, add=T)
segments(reject, 0, reject, dt(reject, df=n-1, ncp=ncp0))
H1 <- 5.3 # 対立仮説
p0 <- .05 # 有意水準
n <- length(data02$q1700)
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n)
# 非心度の計算
ncp0 <- (H1 - H0)/se1700
# 通常のt分布の,有意水準p0でのゼロ仮説の採択域
reject <- seq(qt(p0/2, df=n-1), qt(1-p0/2, df=n-1), by=.03)
# 非心t分布で上の棄却域に対応する範囲の確率
beta <- pt(qt(1-p0/2, df=n-1), df=n-1, ncp=ncp0) - pt(qt(p0/2, df=n-1), df=n-1, ncp=ncp0)
curve(dt(x, df=n-1), from=-3, to=5, bty="n", main="t分布(実線)と非心t分布(点線)", ylab="",
xlab=sprintf("(非心度を%.2fとした場合。塗り潰しはβエラーの大きさ%.1f%%)", ncp0, beta*100))
curve(dt(x, df=n-1, ncp=ncp0), from=-3, to=5, lty=2, add=T)
segments(reject, 0, reject, dt(reject, df=n-1, ncp=ncp0))
? power.t.test( )関数で求める 検定力関数 power.t.test(n, delta, sd, sig.level, power, type="one.sample | two.sample") を使って,本文よりも正確な値を計算してみよう。
H0 <- 5.0 # 母平均のゼロ仮説
H1 <- 5.3 # 対立仮説
p0 <- .05 # 有意水準
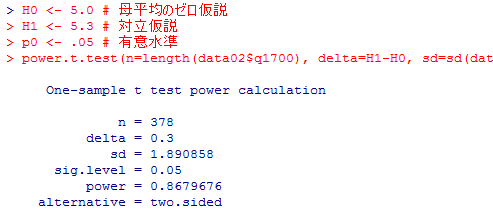
power.t.test(n=length(data02$q1700), delta=H1-H0, sd=sd(data02$q1700), sig.level=p0, type="one.sample")
H1 <- 5.3 # 対立仮説
p0 <- .05 # 有意水準
power.t.test(n=length(data02$q1700), delta=H1-H0, sd=sd(data02$q1700), sig.level=p0, type="one.sample")
どの方法で検定力を計算しても,ほとんど同じ値を得る事ができた。
| 検定力の種々の求め方比較 | |
| 方法 | 検定力(1-β) |
| ?通常のt分布から | .8679441 |
| ?非心t分布から | .8679679 |
| ?power.t.test( )から | .8679676 |
第4章【練習問題】の解答
1)の答え:
「ゼロ仮説が正しい確率」はそもそも条件付き確率ではないが,有意確率は,「ゼロ仮説が正しい時に,標本統計量が実際の計算結果の値以上に,偶然になる確率」という条件付き確率である。言いかえれば「もしゼロ仮説が正しいなら,どれくらい珍しい事が起こった事になるのか」を表すのが有意確率で,それが大きければ「大して珍しい事は起こらなかった(事になる)」,有意確率がとても小さければ「かなり珍しい事が起こった(事になる)」と云う意味となる。
2)の答え:

ゼロ仮説が正しい時,t統計量の絶対値が偶然に1.877を超える確率は約6.1%である。有意水準が5%ではゼロ仮説は棄却されない,つまり母平均は6.5ではないと主張する根拠は弱い。
3)の答え:

ゼロ仮説が正しい時,t統計量の値が偶然に1.877を超える確率は約3.1%しかない。有意水準5%でゼロ仮説は棄却される,つまり母平均はおそらく6.5より大きいだろうと考える。
4)の答え:

2)や3)に比べて標準誤差が大きくなり,その結果t統計量の絶対値が小さくなっている。
必然的に有意確率が大きくなり,2)でも検定結果は5%有意ではなかったが10%よりは小さかった。4)では有意確率は10%をも大きく超えており,全く有意ではない。つまり,ゼロ仮説が正しいとしても,全く珍しくもなんともない結果であったと云う事になる。
5)の答え:
「ゼロ仮説が正しい確率」はそもそも条件付き確率ではないが,有意確率は,「ゼロ仮説が正しい時に,標本統計量が実際の計算結果の値以上に,偶然になる確率」という条件付き確率である。言いかえれば「もしゼロ仮説が正しいなら,どれくらい珍しい事が起こった事になるのか」を表すのが有意確率で,それが大きければ「大して珍しい事は起こらなかった(事になる)」,有意確率がとても小さければ「かなり珍しい事が起こった(事になる)」と云う意味となる。
2)の答え:
# 標本統計量や有効データ数の算出
n <- length(data02$q1700); n
m1700 <- mean(data02$q1700); m1700
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n); se1700
H0 <- 6.5 # ゼロ仮説の値を指定する
t <- (m1700 - H0)/se1700; t
# 計算されたt統計量に対応する有意確率
p <- pt(-1*abs(t), df=n-1) + 1-pt(abs(t), df=n-1); p
n <- length(data02$q1700); n
m1700 <- mean(data02$q1700); m1700
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n); se1700
H0 <- 6.5 # ゼロ仮説の値を指定する
t <- (m1700 - H0)/se1700; t
# 計算されたt統計量に対応する有意確率
p <- pt(-1*abs(t), df=n-1) + 1-pt(abs(t), df=n-1); p
ゼロ仮説が正しい時,t統計量の絶対値が偶然に1.877を超える確率は約6.1%である。有意水準が5%ではゼロ仮説は棄却されない,つまり母平均は6.5ではないと主張する根拠は弱い。
3)の答え:
# 標本統計量や有効データ数の算出
n <- length(data02$q1700); n
m1700 <- mean(data02$q1700); m1700
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n); se1700
H0 <- 6.5 # ゼロ仮説の値を指定する
t <- (m1700 - H0)/se1700; t
# 計算されたt統計量に対応する有意確率
p <- 1-pt(abs(t), df=n-1); p
n <- length(data02$q1700); n
m1700 <- mean(data02$q1700); m1700
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n); se1700
H0 <- 6.5 # ゼロ仮説の値を指定する
t <- (m1700 - H0)/se1700; t
# 計算されたt統計量に対応する有意確率
p <- 1-pt(abs(t), df=n-1); p
ゼロ仮説が正しい時,t統計量の値が偶然に1.877を超える確率は約3.1%しかない。有意水準5%でゼロ仮説は棄却される,つまり母平均はおそらく6.5より大きいだろうと考える。
4)の答え:
# 標本統計量やサンプルサイズの代入
n <- 190
m1700 <- mean(data02$q1700); m1700
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n); se1700
H0 <- 6.5 # ゼロ仮説の値を指定する
t <- (m1700 - H0)/se1700; t
# 計算されたt統計量に対応する有意確率
p <- pt(-1*abs(t), df=n-1) + 1-pt(abs(t), df=n-1); p
n <- 190
m1700 <- mean(data02$q1700); m1700
sd1700 <- sd(data02$q1700)
se1700 <- sd1700/sqrt(n); se1700
H0 <- 6.5 # ゼロ仮説の値を指定する
t <- (m1700 - H0)/se1700; t
# 計算されたt統計量に対応する有意確率
p <- pt(-1*abs(t), df=n-1) + 1-pt(abs(t), df=n-1); p
2)や3)に比べて標準誤差が大きくなり,その結果t統計量の絶対値が小さくなっている。
必然的に有意確率が大きくなり,2)でも検定結果は5%有意ではなかったが10%よりは小さかった。4)では有意確率は10%をも大きく超えており,全く有意ではない。つまり,ゼロ仮説が正しいとしても,全く珍しくもなんともない結果であったと云う事になる。
5)の答え:
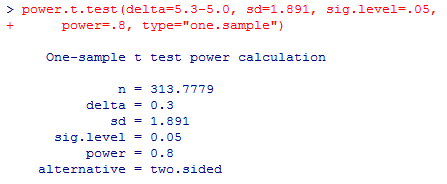
power.t.test(delta=5.3-5.0, sd=1.891, sig.level=.05,
power=.8, type="one.sample")
power=.8, type="one.sample")
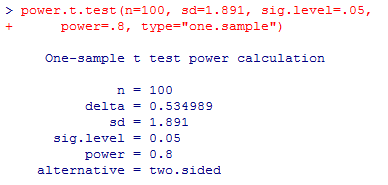
power.t.test(n=100, sd=1.891, sig.level=.05,
power=.8, type="one.sample")
power=.8, type="one.sample")
Copyright (C) 2016-2017 SUGINO Isamu All Rights Reserved. design by tempnate